




Antoine Chaffin
@nohtow.bsky.social
27, French CS Engineer 💻, PhD in ML 🎓🤖 — Guiding generative models for better synthetic data and building multimodal representations @LightOn
Reposted by Antoine Chaffin

✔️ Supporting enterprise-scale document processing
✔️ Enabling more accurate retrieval for AI-generated responses
Kudos to @nohtow.bsky.social for this new SOTA achievement!
🔗 Read the full blog article: www.lighton.ai/lighton-blog...
✔️ Enabling more accurate retrieval for AI-generated responses
Kudos to @nohtow.bsky.social for this new SOTA achievement!
🔗 Read the full blog article: www.lighton.ai/lighton-blog...

LightOn Releases GTE-ModernColBERT, First State-of-the-Art Late-Interaction Model Trained on PyLate! - LightOn
LightOn is proud to announce the release of GTE-ModernColBERT, our new state-of-the-art, open-source, multi-vector retrieval model. By leveraging ModernBERT architecture and our innovative PyLate libr...
www.lighton.ai
April 30, 2025 at 3:49 PM
✔️ Supporting enterprise-scale document processing
✔️ Enabling more accurate retrieval for AI-generated responses
Kudos to @nohtow.bsky.social for this new SOTA achievement!
🔗 Read the full blog article: www.lighton.ai/lighton-blog...
✔️ Enabling more accurate retrieval for AI-generated responses
Kudos to @nohtow.bsky.social for this new SOTA achievement!
🔗 Read the full blog article: www.lighton.ai/lighton-blog...
Reposted by Antoine Chaffin

ColBERT (a.k.a. multi-vector, late-interaction) models are extremely strong search models, often outperforming dense embedding models. And @lightonai.bsky.social just released a new state-of-the-art one: GTE-ModernColBERT-v1!
Details in 🧵
Details in 🧵

April 30, 2025 at 3:27 PM
ColBERT (a.k.a. multi-vector, late-interaction) models are extremely strong search models, often outperforming dense embedding models. And @lightonai.bsky.social just released a new state-of-the-art one: GTE-ModernColBERT-v1!
Details in 🧵
Details in 🧵
Reposted by Antoine Chaffin
I'm a big fan of the PyLate project for ColBERT models, and I'm glad to see these strong models coming out. Very nice work by the @lightonai.bsky.social folks, especially @nohtow.bsky.social.
Learn more about PyLate here: lightonai.github.io/pylate/
Learn more about PyLate here: lightonai.github.io/pylate/
pylate
Neural Search
lightonai.github.io
April 30, 2025 at 3:27 PM
I'm a big fan of the PyLate project for ColBERT models, and I'm glad to see these strong models coming out. Very nice work by the @lightonai.bsky.social folks, especially @nohtow.bsky.social.
Learn more about PyLate here: lightonai.github.io/pylate/
Learn more about PyLate here: lightonai.github.io/pylate/
Among all those LLM releases, here is an important retrieval release:
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀

April 30, 2025 at 2:42 PM
Among all those LLM releases, here is an important retrieval release:
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀
Reposted by Antoine Chaffin
ModernBERT-embed-large is released under Apache 2.0 and is available on Hugging Face:
huggingface.co/lightonai/mo...
Congrats to @nohtow.bsky.social for this great work!
huggingface.co/lightonai/mo...
Congrats to @nohtow.bsky.social for this great work!

lightonai/modernbert-embed-large · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 14, 2025 at 4:42 PM
ModernBERT-embed-large is released under Apache 2.0 and is available on Hugging Face:
huggingface.co/lightonai/mo...
Congrats to @nohtow.bsky.social for this great work!
huggingface.co/lightonai/mo...
Congrats to @nohtow.bsky.social for this great work!
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!

January 14, 2025 at 3:32 PM
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
Reposted by Antoine Chaffin
Today, LightOn releases ModernBERT, a SOTA model for retrieval and classification.
This work was performed in collaboration with Answer.ai and the model was trained on Orange Business Cloud Avenue infrastructure.
www.lighton.ai/lighton-blog...
This work was performed in collaboration with Answer.ai and the model was trained on Orange Business Cloud Avenue infrastructure.
www.lighton.ai/lighton-blog...

December 19, 2024 at 4:53 PM
Today, LightOn releases ModernBERT, a SOTA model for retrieval and classification.
This work was performed in collaboration with Answer.ai and the model was trained on Orange Business Cloud Avenue infrastructure.
www.lighton.ai/lighton-blog...
This work was performed in collaboration with Answer.ai and the model was trained on Orange Business Cloud Avenue infrastructure.
www.lighton.ai/lighton-blog...
Reposted by Antoine Chaffin

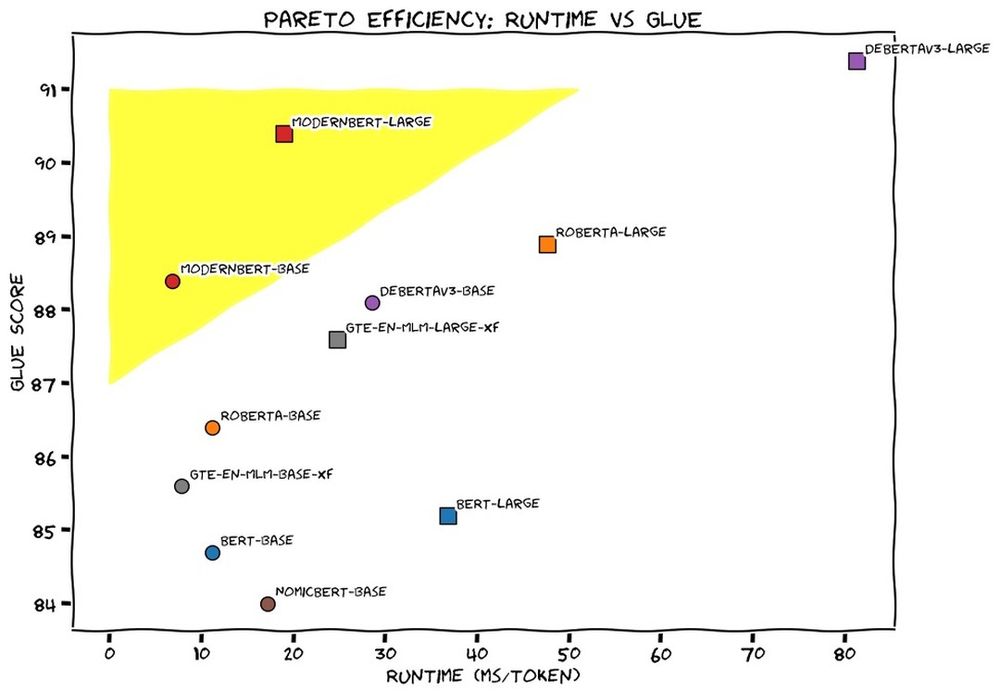
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
December 22, 2024 at 6:12 AM
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
Reposted by Antoine Chaffin

When one evaluates log-likelihood of a sequence of length L via the chain rule of probability, the first term has missingness fraction of 1, the second has missingness of (L-1)/L, etc. So the inference-time masking rate is ~ Uniform[0, 1].
December 20, 2024 at 7:52 PM
When one evaluates log-likelihood of a sequence of length L via the chain rule of probability, the first term has missingness fraction of 1, the second has missingness of (L-1)/L, etc. So the inference-time masking rate is ~ Uniform[0, 1].
Reposted by Antoine Chaffin
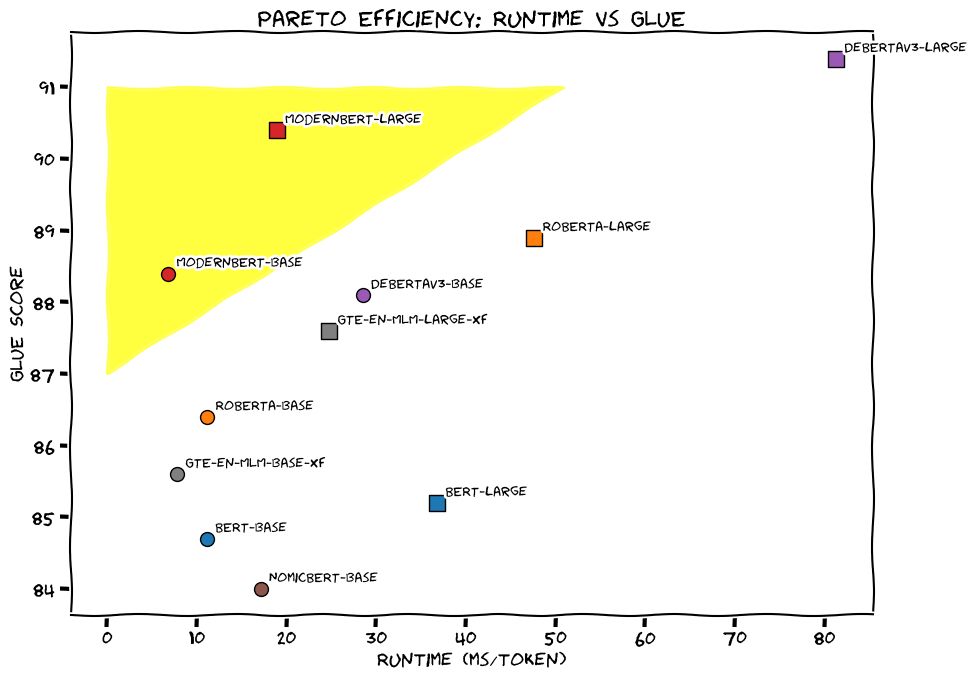
BERT is BACK! I joined a collaboration with AnswerAI and LightOn to bring you the next iteration of BERT.
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
December 19, 2024 at 4:41 PM
BERT is BACK! I joined a collaboration with AnswerAI and LightOn to bring you the next iteration of BERT.
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
Reposted by Antoine Chaffin

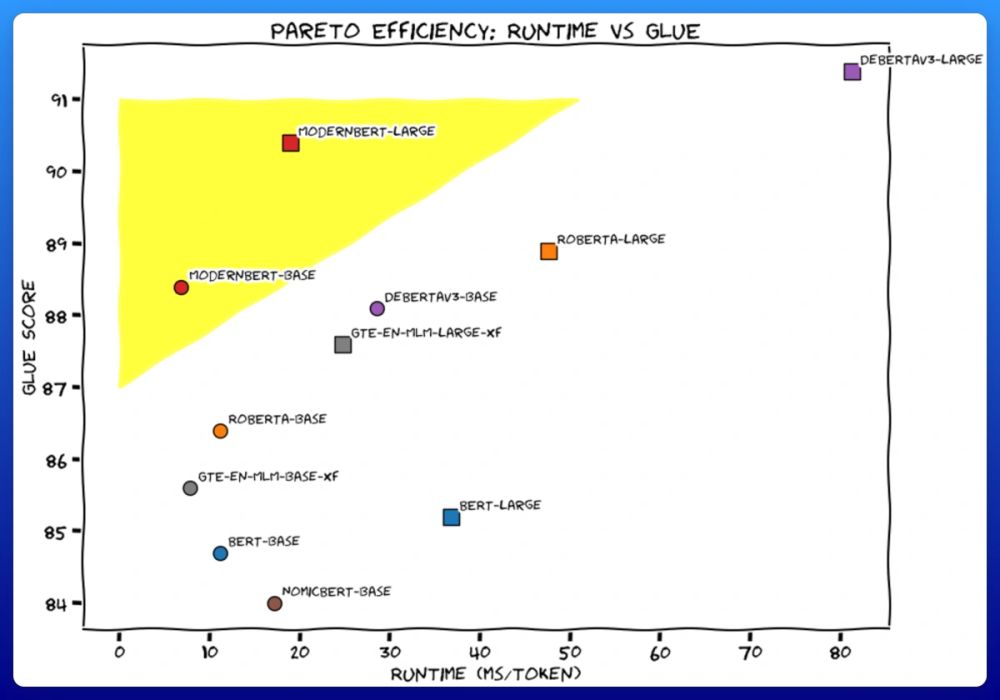
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
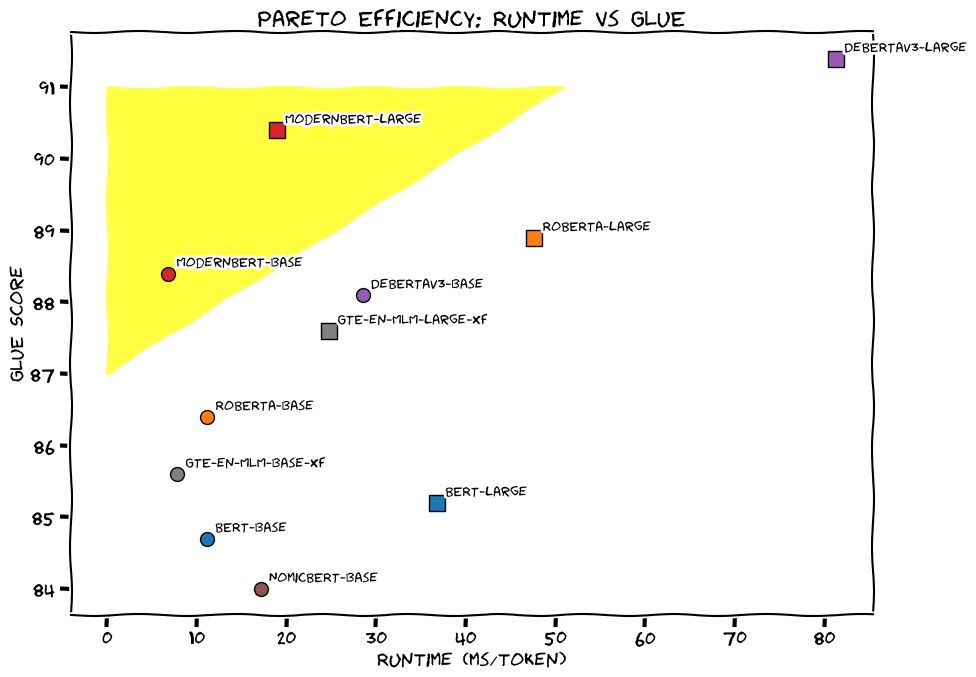
I am thrilled to announce the release of ModernBERT, the long-awaited BERT replacement!
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
December 19, 2024 at 5:36 PM
I am thrilled to announce the release of ModernBERT, the long-awaited BERT replacement!
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
Reposted by Antoine Chaffin
Seven months ago, @bclavie.bsky.social kicked things off, and soon Benjamin Warner & @nohtow.bsky.social joined him as project co-leads. I don't think anyone quite knew what we were getting in to…
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷

December 19, 2024 at 4:45 PM
Seven months ago, @bclavie.bsky.social kicked things off, and soon Benjamin Warner & @nohtow.bsky.social joined him as project co-leads. I don't think anyone quite knew what we were getting in to…
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷
Reposted by Antoine Chaffin
This project is made possible by the huge effort from everyone involved, including the project leads Benjamin Warner, @bclavie.bsky.social, & @nohtow.bsky.social. And a big thanks to LightOnIO for contributing human brains AND computer brains!
December 19, 2024 at 4:45 PM
This project is made possible by the huge effort from everyone involved, including the project leads Benjamin Warner, @bclavie.bsky.social, & @nohtow.bsky.social. And a big thanks to LightOnIO for contributing human brains AND computer brains!
Reposted by Antoine Chaffin
🔗 Read the full blog article here: www.lighton.ai/lighton-blog...
Congratulations to @nohtow.bsky.social, Oskar Hallström, Said Taghadouini, Iacopo Poli and all the folks at Answer.ai that made this model a reality.
Congratulations to @nohtow.bsky.social, Oskar Hallström, Said Taghadouini, Iacopo Poli and all the folks at Answer.ai that made this model a reality.
December 19, 2024 at 4:53 PM
🔗 Read the full blog article here: www.lighton.ai/lighton-blog...
Congratulations to @nohtow.bsky.social, Oskar Hallström, Said Taghadouini, Iacopo Poli and all the folks at Answer.ai that made this model a reality.
Congratulations to @nohtow.bsky.social, Oskar Hallström, Said Taghadouini, Iacopo Poli and all the folks at Answer.ai that made this model a reality.
Wild statement ngl

December 16, 2024 at 6:24 PM
Wild statement ngl
PyLate v1.1.3 is now live!
This update pushes the latest features upstream:
- Loading of stanford-nlp models natively
- Serving of embeddings using a FastAPI with dynamic batch processing
- Trained models now include a model card with information about model and training setup
This update pushes the latest features upstream:
- Loading of stanford-nlp models natively
- Serving of embeddings using a FastAPI with dynamic batch processing
- Trained models now include a model card with information about model and training setup
November 26, 2024 at 3:29 PM
PyLate v1.1.3 is now live!
This update pushes the latest features upstream:
- Loading of stanford-nlp models natively
- Serving of embeddings using a FastAPI with dynamic batch processing
- Trained models now include a model card with information about model and training setup
This update pushes the latest features upstream:
- Loading of stanford-nlp models natively
- Serving of embeddings using a FastAPI with dynamic batch processing
- Trained models now include a model card with information about model and training setup