




Noam Teyssier
@noamteyssier.bsky.social
Bioinformatics Scientist at the Arc Institute.
Working at the intersection of functional genomics, systems biology, and machine learning. I also build rusty bioinformatics tools
https://github.com/noamteyssier
Working at the intersection of functional genomics, systems biology, and machine learning. I also build rusty bioinformatics tools
https://github.com/noamteyssier
Added a feature to bqtools yesterday for colored grep output. Also supports colored FASTX output as well. Already useful this morning as I troubleshoot some sequencing outputs!


September 4, 2025 at 5:56 PM
Added a feature to bqtools yesterday for colored grep output. Also supports colored FASTX output as well. Already useful this morning as I troubleshoot some sequencing outputs!
Just merged in an awesome new feature for xsra to support named pipes with @robp.bsky.social.
This lets you skip an intermediary write step and go straight from SRA to downstream tools.
It works with accessions that are both on- or off-disk.
This lets you skip an intermediary write step and go straight from SRA to downstream tools.
It works with accessions that are both on- or off-disk.

May 9, 2025 at 3:26 PM
Just merged in an awesome new feature for xsra to support named pipes with @robp.bsky.social.
This lets you skip an intermediary write step and go straight from SRA to downstream tools.
It works with accessions that are both on- or off-disk.
This lets you skip an intermediary write step and go straight from SRA to downstream tools.
It works with accessions that are both on- or off-disk.
Ah yes 2bit was a big inspiration for binseq - I didn't include it because it wasn't widely used and it was more geared towards large genomes so I figured it wouldn't scale.
But you're right I didn't formally test it. Here's a simple bench with Kent's utils (1-core bqtools to be fair)
But you're right I didn't formally test it. Here's a simple bench with Kent's utils (1-core bqtools to be fair)


May 8, 2025 at 3:24 PM
Ah yes 2bit was a big inspiration for binseq - I didn't include it because it wasn't widely used and it was more geared towards large genomes so I figured it wouldn't scale.
But you're right I didn't formally test it. Here's a simple bench with Kent's utils (1-core bqtools to be fair)
But you're right I didn't formally test it. Here's a simple bench with Kent's utils (1-core bqtools to be fair)
I did an exploration into cheap per-record operations with binseq (grep in my example) and was curious how it would hold up here.
I forked sassy for a quick test and found 25x throughput over gzip and a 16x over raw.
That includes sharing SIMD with search during 2bit decode also.
I forked sassy for a quick test and found 25x throughput over gzip and a 16x over raw.
That includes sharing SIMD with search during 2bit decode also.

May 2, 2025 at 12:42 AM
I did an exploration into cheap per-record operations with binseq (grep in my example) and was curious how it would hold up here.
I forked sassy for a quick test and found 25x throughput over gzip and a 16x over raw.
That includes sharing SIMD with search during 2bit decode also.
I forked sassy for a quick test and found 25x throughput over gzip and a 16x over raw.
That includes sharing SIMD with search during 2bit decode also.
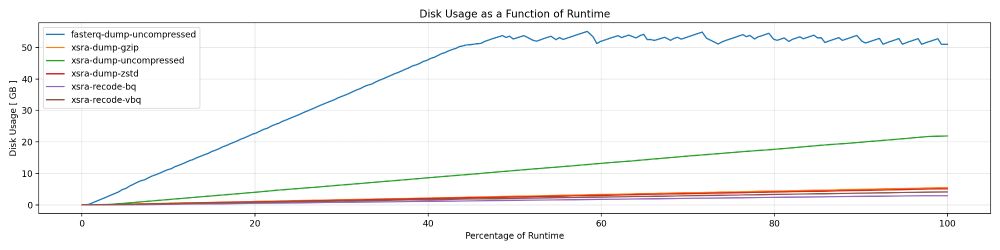
One of the major focuses of the project was to streamline extraction by removing temporary outputs and we show that xsra achieves significantly less disk usage compared to fasterq-dump.
April 29, 2025 at 9:03 PM
One of the major focuses of the project was to streamline extraction by removing temporary outputs and we show that xsra achieves significantly less disk usage compared to fasterq-dump.
xsra significantly outperforms fasterq-dump and fastq-dump when dumping uncompressed records but is also faster when outputting compressed records.
It can achieve almost 10x faster throughput outputting BINSEQ files when skipping FASTQ altogether
It can achieve almost 10x faster throughput outputting BINSEQ files when skipping FASTQ altogether

April 29, 2025 at 9:03 PM
xsra significantly outperforms fasterq-dump and fastq-dump when dumping uncompressed records but is also faster when outputting compressed records.
It can achieve almost 10x faster throughput outputting BINSEQ files when skipping FASTQ altogether
It can achieve almost 10x faster throughput outputting BINSEQ files when skipping FASTQ altogether
Interestingly we also observe the behavior for more complex tasks like sequence alignment. We demonstrate that BINSEQ continues to scale linearly with thread usage with both minimap2 and STAR.

April 15, 2025 at 2:40 PM
Interestingly we also observe the behavior for more complex tasks like sequence alignment. We demonstrate that BINSEQ continues to scale linearly with thread usage with both minimap2 and STAR.
Where these formats really shine is in their ability to scale. Because they don't require being parsed sequentially they continue being performant as sequential formats (FASTQ) plateau. Simple tasks like kmer-counting show gains as early as 8 threads.

April 15, 2025 at 2:40 PM
Where these formats really shine is in their ability to scale. Because they don't require being parsed sequentially they continue being performant as sequential formats (FASTQ) plateau. Simple tasks like kmer-counting show gains as early as 8 threads.
BINSEQ and VBINSEQ are the only family members (for now). They are both built around two-bit encoded nucleotides and each support paired records natively.
We provide rust libraries for IO, C and C++ bindings to BINSEQ, and a CLI tool to easily manipulate them.
We provide rust libraries for IO, C and C++ bindings to BINSEQ, and a CLI tool to easily manipulate them.

April 15, 2025 at 2:40 PM
BINSEQ and VBINSEQ are the only family members (for now). They are both built around two-bit encoded nucleotides and each support paired records natively.
We provide rust libraries for IO, C and C++ bindings to BINSEQ, and a CLI tool to easily manipulate them.
We provide rust libraries for IO, C and C++ bindings to BINSEQ, and a CLI tool to easily manipulate them.