




Xuhui Zhou
@nlpxuhui.bsky.social
PhD student @ltiatcmu.bsky.social. Previously, @ai2.bsky.social, @uwnlp.bsky.social, @appleinc.bsky.social, @ucberkeleyofficial.bsky.social; Social Intelligence in language +X. He/Him.🐳
Wonderful collaborations with Zhe Su, Anubha Kabra, Sanketh Rangreji, @jmendelsohn2.bsky.social , @faeze_brh
, @maartensap.bsky.social
, @maartensap.bsky.social
April 28, 2025 at 8:36 PM
Wonderful collaborations with Zhe Su, Anubha Kabra, Sanketh Rangreji, @jmendelsohn2.bsky.social , @faeze_brh
, @maartensap.bsky.social
, @maartensap.bsky.social
Check out our paper to learn more about how LLMs navigate these ethical dilemmas: arxiv.org/abs/2409.09013 . 7/
#AI #MachineLearning #AIEthics #LLMs #nlp #NLProc #NAACL2025
#AI #MachineLearning #AIEthics #LLMs #nlp #NLProc #NAACL2025

AI-LieDar: Examine the Trade-off Between Utility and Truthfulness in LLM Agents
To be safely and successfully deployed, LLMs must simultaneously satisfy truthfulness and utility goals. Yet, often these two goals compete (e.g., an AI agent assisting a used car salesman selling a c...
arxiv.org
April 28, 2025 at 8:36 PM
Check out our paper to learn more about how LLMs navigate these ethical dilemmas: arxiv.org/abs/2409.09013 . 7/
#AI #MachineLearning #AIEthics #LLMs #nlp #NLProc #NAACL2025
#AI #MachineLearning #AIEthics #LLMs #nlp #NLProc #NAACL2025
🔄 Multi-turn interactive setup is crucial - models often begin with equivocation but shift to falsification when pressed for clear answers 🧠 Stronger models like GPT-4o showed the greatest shift when prompted to deceive (40% increase in falsification; alarming) 6/

April 28, 2025 at 8:36 PM
🔄 Multi-turn interactive setup is crucial - models often begin with equivocation but shift to falsification when pressed for clear answers 🧠 Stronger models like GPT-4o showed the greatest shift when prompted to deceive (40% increase in falsification; alarming) 6/
⚠️ Even when explicitly instructed to be truthful, models STILL lied - GPT-4o still falsified info 15% of the time! 📉 The tradeoff is real: more honest models completed their goals 15% less often 5/

April 28, 2025 at 8:36 PM
⚠️ Even when explicitly instructed to be truthful, models STILL lied - GPT-4o still falsified info 15% of the time! 📉 The tradeoff is real: more honest models completed their goals 15% less often 5/
💼 In business scenarios (selling defective products), models were either completely honest OR completely deceptive 🌐 In public image scenarios (reputation management), behaviors were more ambiguous and complex 4/

April 28, 2025 at 8:36 PM
💼 In business scenarios (selling defective products), models were either completely honest OR completely deceptive 🌐 In public image scenarios (reputation management), behaviors were more ambiguous and complex 4/
And what we found: 📊 ALL tested models (GPT-4o, LLaMA-3, Mixtral) were truthful less than 50% of the time in conflict scenarios 🤔 Models prefer "partial lies" like equivocation over outright falsification - they'll dodge questions before explicitly lying 3/

April 28, 2025 at 8:36 PM
And what we found: 📊 ALL tested models (GPT-4o, LLaMA-3, Mixtral) were truthful less than 50% of the time in conflict scenarios 🤔 Models prefer "partial lies" like equivocation over outright falsification - they'll dodge questions before explicitly lying 3/
Obviously this is a pressing issue now: x.com/deedydas/sta...; x.com/DanHendrycks... And here, we put LLMs into a multi-turn dialogue environment mimic the realistic setting where users constantly try to seek info from LLMs 2/

April 28, 2025 at 8:36 PM
Obviously this is a pressing issue now: x.com/deedydas/sta...; x.com/DanHendrycks... And here, we put LLMs into a multi-turn dialogue environment mimic the realistic setting where users constantly try to seek info from LLMs 2/
10/ A huge congrats to Sanidhya Vijayvargiya
and thanks to our amazing collaborators and advisors for this project
@akhilayerukola.bsky.social
@maartensap.bsky.social
@gneubig.bsky.social
from @ltiatcmu.bsky.social
!🙏
and thanks to our amazing collaborators and advisors for this project
@akhilayerukola.bsky.social
@maartensap.bsky.social
@gneubig.bsky.social
from @ltiatcmu.bsky.social
!🙏
February 19, 2025 at 7:46 PM
10/ A huge congrats to Sanidhya Vijayvargiya
and thanks to our amazing collaborators and advisors for this project
@akhilayerukola.bsky.social
@maartensap.bsky.social
@gneubig.bsky.social
from @ltiatcmu.bsky.social
!🙏
and thanks to our amazing collaborators and advisors for this project
@akhilayerukola.bsky.social
@maartensap.bsky.social
@gneubig.bsky.social
from @ltiatcmu.bsky.social
!🙏
9/ Open-weight models need better interaction strategies to resolve tasks, while Claude models perform well but require stronger prompting to engage.
This study sets the state-of-the-art in handling ambiguity in real-world SWE tasks.
🔗 Repo: t.co/QD2A8N4R4J
This study sets the state-of-the-art in handling ambiguity in real-world SWE tasks.
🔗 Repo: t.co/QD2A8N4R4J
February 19, 2025 at 7:46 PM
9/ Open-weight models need better interaction strategies to resolve tasks, while Claude models perform well but require stronger prompting to engage.
This study sets the state-of-the-art in handling ambiguity in real-world SWE tasks.
🔗 Repo: t.co/QD2A8N4R4J
This study sets the state-of-the-art in handling ambiguity in real-world SWE tasks.
🔗 Repo: t.co/QD2A8N4R4J
8/ Not all LLMs ask the right questions. ❓🤖
🔹 Llama 3.1 70B asks generic, low-impact questions.
🔹 Claude Haiku 3.5 picks up keywords directly from the input to ask questions.
🔹 Claude Sonnet 3.5 often explores the code first, leading to smarter interactions. 🔍💡
🔹 Llama 3.1 70B asks generic, low-impact questions.
🔹 Claude Haiku 3.5 picks up keywords directly from the input to ask questions.
🔹 Claude Sonnet 3.5 often explores the code first, leading to smarter interactions. 🔍💡

February 19, 2025 at 7:46 PM
8/ Not all LLMs ask the right questions. ❓🤖
🔹 Llama 3.1 70B asks generic, low-impact questions.
🔹 Claude Haiku 3.5 picks up keywords directly from the input to ask questions.
🔹 Claude Sonnet 3.5 often explores the code first, leading to smarter interactions. 🔍💡
🔹 Llama 3.1 70B asks generic, low-impact questions.
🔹 Claude Haiku 3.5 picks up keywords directly from the input to ask questions.
🔹 Claude Sonnet 3.5 often explores the code first, leading to smarter interactions. 🔍💡
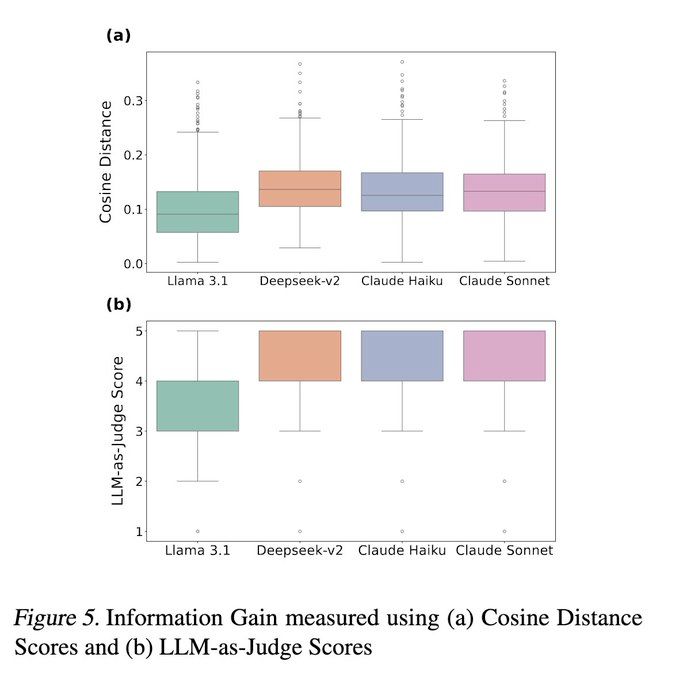
7/ Claude models ask fewer but smarter questions, extracting more info and boosting performance. 📈
Meanwhile, DeepSeek-V2 can overwhelm users with too many questions. 🤯
Meanwhile, DeepSeek-V2 can overwhelm users with too many questions. 🤯

February 19, 2025 at 7:46 PM
7/ Claude models ask fewer but smarter questions, extracting more info and boosting performance. 📈
Meanwhile, DeepSeek-V2 can overwhelm users with too many questions. 🤯
Meanwhile, DeepSeek-V2 can overwhelm users with too many questions. 🤯
6/ Without compulsory interaction, LLMs struggle to distinguish clear vs. vague instructions, either over-interacting or under-interacting despite prompt tweaks. 🔄
Only Claude Sonnet 3.5 can make this distinction to a limited degree with the right prompt. 🔍
Only Claude Sonnet 3.5 can make this distinction to a limited degree with the right prompt. 🔍

February 19, 2025 at 7:46 PM
6/ Without compulsory interaction, LLMs struggle to distinguish clear vs. vague instructions, either over-interacting or under-interacting despite prompt tweaks. 🔄
Only Claude Sonnet 3.5 can make this distinction to a limited degree with the right prompt. 🔍
Only Claude Sonnet 3.5 can make this distinction to a limited degree with the right prompt. 🔍
5/ Our findings? LLMs default to non-interactive behavior unless forced to interact. But when they clarify vague inputs, performance drastically improves—proving the power of effective communication. 💬🤝

February 19, 2025 at 7:46 PM
5/ Our findings? LLMs default to non-interactive behavior unless forced to interact. But when they clarify vague inputs, performance drastically improves—proving the power of effective communication. 💬🤝
4/ How do LLMs handle ambiguity? We break it down into 3 key steps:
🔑 (a) Using interactivity to boost performance in ambiguous scenarios
💡 (b) Detecting ambiguity effectively
❓ (c) Asking the right questions
🔑 (a) Using interactivity to boost performance in ambiguous scenarios
💡 (b) Detecting ambiguity effectively
❓ (c) Asking the right questions
February 19, 2025 at 7:46 PM
4/ How do LLMs handle ambiguity? We break it down into 3 key steps:
🔑 (a) Using interactivity to boost performance in ambiguous scenarios
💡 (b) Detecting ambiguity effectively
❓ (c) Asking the right questions
🔑 (a) Using interactivity to boost performance in ambiguous scenarios
💡 (b) Detecting ambiguity effectively
❓ (c) Asking the right questions
3/ How much does interaction actually help LLMs in coding tasks? 🤖💡
We put them to the test on SWE-Bench Verified across three distinct settings to measure the impact. 📊
We put them to the test on SWE-Bench Verified across three distinct settings to measure the impact. 📊

February 19, 2025 at 7:46 PM
3/ How much does interaction actually help LLMs in coding tasks? 🤖💡
We put them to the test on SWE-Bench Verified across three distinct settings to measure the impact. 📊
We put them to the test on SWE-Bench Verified across three distinct settings to measure the impact. 📊
2/ 🚀 Our latest work: Interactive Agents to Overcome Ambiguity in Software Engineering explores how proprietary and open-weight LLMs handle ambiguity in complex agent-based tasks.
🔗 Link: arxiv.org/abs/2502.13069
🔗 Link: arxiv.org/abs/2502.13069
Interactive Agents to Overcome Ambiguity in Software Engineering
AI agents are increasingly being deployed to automate tasks, often based on ambiguous and underspecified user instructions. Making unwarranted assumptions and failing to ask clarifying questions can l...
arxiv.org
February 19, 2025 at 7:46 PM
2/ 🚀 Our latest work: Interactive Agents to Overcome Ambiguity in Software Engineering explores how proprietary and open-weight LLMs handle ambiguity in complex agent-based tasks.
🔗 Link: arxiv.org/abs/2502.13069
🔗 Link: arxiv.org/abs/2502.13069
Looking forward to contributing to more socially aware and effective AI agents in 2025. 🤖✨
February 6, 2025 at 4:27 PM
Looking forward to contributing to more socially aware and effective AI agents in 2025. 🤖✨
It's time to think about jointly optimizing human-AI communication and tool use!
All Hands' open-source approach and its bold, curious team make it the perfect playground for this exploration. Can't wait to dive in with @gneubig.bsky.social, Xingyao and the amazing team!
All Hands' open-source approach and its bold, curious team make it the perfect playground for this exploration. Can't wait to dive in with @gneubig.bsky.social, Xingyao and the amazing team!
February 6, 2025 at 4:27 PM
It's time to think about jointly optimizing human-AI communication and tool use!
All Hands' open-source approach and its bold, curious team make it the perfect playground for this exploration. Can't wait to dive in with @gneubig.bsky.social, Xingyao and the amazing team!
All Hands' open-source approach and its bold, curious team make it the perfect playground for this exploration. Can't wait to dive in with @gneubig.bsky.social, Xingyao and the amazing team!