


Nic Fishman
@njw.fish
Using computers to read the entrails of modernity (statistics, optimization, machine learning), focused on applications in the social and biological sciences.
Currently: Stats PhD @Harvard
Previously: CS/Soc @Stanford, Stat/ML @Oxford
https://njw.fish
Currently: Stats PhD @Harvard
Previously: CS/Soc @Stanford, Stat/ML @Oxford
https://njw.fish
Not a python package but the full codebase is available here I think we have made it reasonably approachable: bsky.app/profile/njw....
9/ TL;DR:
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...

Generative Distribution Embeddings
Many real-world problems require reasoning across multiple scales, demanding models which operate not on single data points, but on entire distributions. We introduce generative distribution embedding...
arxiv.org
May 27, 2025 at 3:58 PM
Not a python package but the full codebase is available here I think we have made it reasonably approachable: bsky.app/profile/njw....
Yes we are super excited about that kind of direction!
May 27, 2025 at 2:29 PM
Yes we are super excited about that kind of direction!
Imminently reasonable! That being said, I do think these results are kind of incredible. We do not train in any way to recover this kind of OT result, it just happens. I literally could not believe when we saw this. bsky.app/profile/njw....
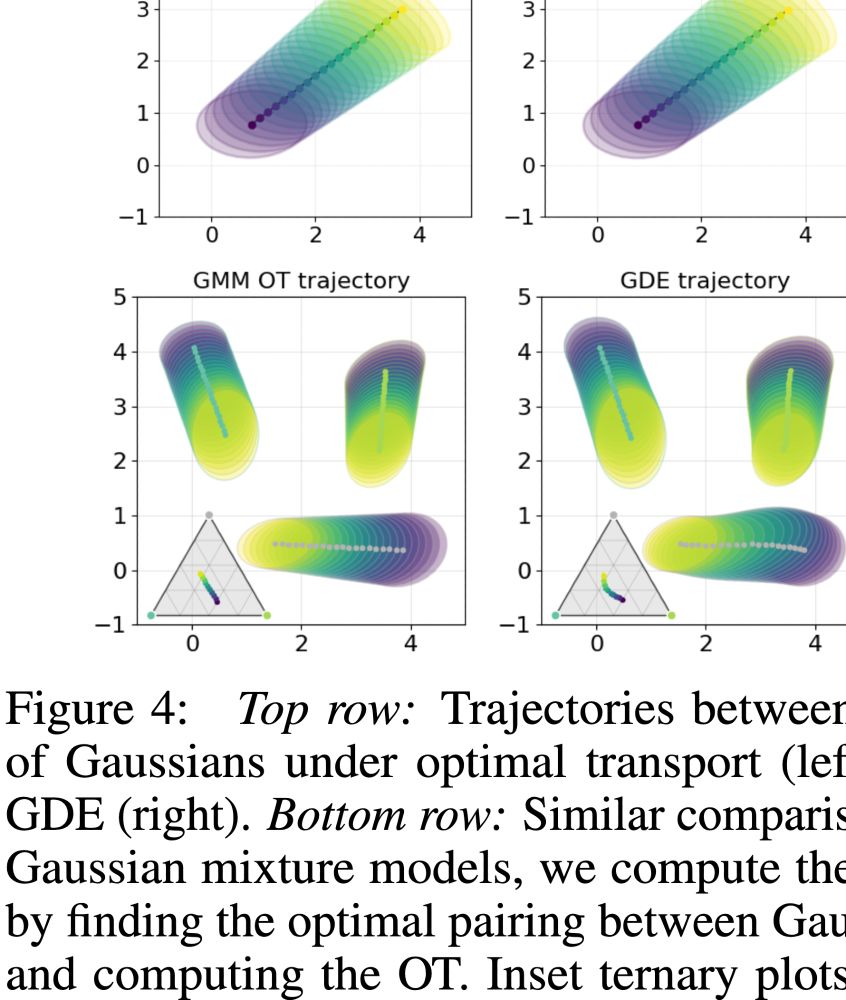
4/ With this simple setup, we find surprisingly elegant geometry:
GDE latent distances track Wasserstein-2 (W₂) distances across modalities (shown for multinomial distributions)
Latent interpolations recover optimal transport paths (shown for Gaussians and Gaussian mixtures)
GDE latent distances track Wasserstein-2 (W₂) distances across modalities (shown for multinomial distributions)
Latent interpolations recover optimal transport paths (shown for Gaussians and Gaussian mixtures)

May 27, 2025 at 12:33 PM
Imminently reasonable! That being said, I do think these results are kind of incredible. We do not train in any way to recover this kind of OT result, it just happens. I literally could not believe when we saw this. bsky.app/profile/njw....
Yep I think you’ll find a bunch of in silicio examples and the applications in the paper! And there is code as well, see here for both: bsky.app/profile/njw....
9/ TL;DR:
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
Generative Distribution Embeddings
Many real-world problems require reasoning across multiple scales, demanding models which operate not on single data points, but on entire distributions. We introduce generative distribution embedding...
arxiv.org
May 27, 2025 at 12:22 PM
Yep I think you’ll find a bunch of in silicio examples and the applications in the paper! And there is code as well, see here for both: bsky.app/profile/njw....
10/ This is joint work with @ggokul.bsky.social, Peng Yin, Jonathan Gootenberg, and Omar Abudayyeh.
We’re excited about GDEs as a tool for multiscale modeling — and as a bridge between empirical process theory, generative modeling, and geometry.
Looking forward to your thoughts!
We’re excited about GDEs as a tool for multiscale modeling — and as a bridge between empirical process theory, generative modeling, and geometry.
Looking forward to your thoughts!
May 26, 2025 at 3:53 PM
10/ This is joint work with @ggokul.bsky.social, Peng Yin, Jonathan Gootenberg, and Omar Abudayyeh.
We’re excited about GDEs as a tool for multiscale modeling — and as a bridge between empirical process theory, generative modeling, and geometry.
Looking forward to your thoughts!
We’re excited about GDEs as a tool for multiscale modeling — and as a bridge between empirical process theory, generative modeling, and geometry.
Looking forward to your thoughts!
9/ TL;DR:
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
Generative Distribution Embeddings
Many real-world problems require reasoning across multiple scales, demanding models which operate not on single data points, but on entire distributions. We introduce generative distribution embedding...
arxiv.org
May 26, 2025 at 3:52 PM
9/ TL;DR:
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
GDEs offer a general framework for:
1. Modeling hierarchical data
2. Embedding and generating distributions
3. Linking modern generative models with classical statistical ideas
📄 arxiv.org/abs/2505.18150
💻 github.com/njwfish/Dist...
8/ 🧬 Synthetic promoter design
Sequences binned by expression → GDEs provide a powerful embedding space for regulatory sequence design.
🦠 SARS-CoV-2 spike protein dynamics
GDEs embed monthly lineage distributions and recover smooth latent chronologies.
Sequences binned by expression → GDEs provide a powerful embedding space for regulatory sequence design.
🦠 SARS-CoV-2 spike protein dynamics
GDEs embed monthly lineage distributions and recover smooth latent chronologies.


May 26, 2025 at 3:52 PM
8/ 🧬 Synthetic promoter design
Sequences binned by expression → GDEs provide a powerful embedding space for regulatory sequence design.
🦠 SARS-CoV-2 spike protein dynamics
GDEs embed monthly lineage distributions and recover smooth latent chronologies.
Sequences binned by expression → GDEs provide a powerful embedding space for regulatory sequence design.
🦠 SARS-CoV-2 spike protein dynamics
GDEs embed monthly lineage distributions and recover smooth latent chronologies.
7/ 🧫 Morphological profiling (20M images)
GDEs model phenotype distributions induced by perturbations and generalize to unseen conditions.
🧬 DNA methylation (253M reads)
We learn tissue-specific methylation patterns directly from raw bisulfite reads — no alignment necessary.
GDEs model phenotype distributions induced by perturbations and generalize to unseen conditions.
🧬 DNA methylation (253M reads)
We learn tissue-specific methylation patterns directly from raw bisulfite reads — no alignment necessary.

May 26, 2025 at 3:51 PM
7/ 🧫 Morphological profiling (20M images)
GDEs model phenotype distributions induced by perturbations and generalize to unseen conditions.
🧬 DNA methylation (253M reads)
We learn tissue-specific methylation patterns directly from raw bisulfite reads — no alignment necessary.
GDEs model phenotype distributions induced by perturbations and generalize to unseen conditions.
🧬 DNA methylation (253M reads)
We learn tissue-specific methylation patterns directly from raw bisulfite reads — no alignment necessary.
6/ 🧬 scRNA-seq lineage tracing
Each clone is a population of cells → a distribution over expression. GDEs predict clonal fate better than prior approaches.
🧪 CRISPR perturbation effects
GDEs can improve zero-shot prediction of transcriptional response distributions.
Each clone is a population of cells → a distribution over expression. GDEs predict clonal fate better than prior approaches.
🧪 CRISPR perturbation effects
GDEs can improve zero-shot prediction of transcriptional response distributions.

May 26, 2025 at 3:51 PM
6/ 🧬 scRNA-seq lineage tracing
Each clone is a population of cells → a distribution over expression. GDEs predict clonal fate better than prior approaches.
🧪 CRISPR perturbation effects
GDEs can improve zero-shot prediction of transcriptional response distributions.
Each clone is a population of cells → a distribution over expression. GDEs predict clonal fate better than prior approaches.
🧪 CRISPR perturbation effects
GDEs can improve zero-shot prediction of transcriptional response distributions.
5/ GDEs are built to scale: at inference, you can embed or generate from large samples without retraining.
We show that GDE embeddings are asymptotically normal, grounding this with results from empirical process theory.
We show that GDE embeddings are asymptotically normal, grounding this with results from empirical process theory.

May 26, 2025 at 3:51 PM
5/ GDEs are built to scale: at inference, you can embed or generate from large samples without retraining.
We show that GDE embeddings are asymptotically normal, grounding this with results from empirical process theory.
We show that GDE embeddings are asymptotically normal, grounding this with results from empirical process theory.
4/ With this simple setup, we find surprisingly elegant geometry:
GDE latent distances track Wasserstein-2 (W₂) distances across modalities (shown for multinomial distributions)
Latent interpolations recover optimal transport paths (shown for Gaussians and Gaussian mixtures)
GDE latent distances track Wasserstein-2 (W₂) distances across modalities (shown for multinomial distributions)
Latent interpolations recover optimal transport paths (shown for Gaussians and Gaussian mixtures)
May 26, 2025 at 3:50 PM
4/ With this simple setup, we find surprisingly elegant geometry:
GDE latent distances track Wasserstein-2 (W₂) distances across modalities (shown for multinomial distributions)
Latent interpolations recover optimal transport paths (shown for Gaussians and Gaussian mixtures)
GDE latent distances track Wasserstein-2 (W₂) distances across modalities (shown for multinomial distributions)
Latent interpolations recover optimal transport paths (shown for Gaussians and Gaussian mixtures)
3/ Why does this matter?
✅ Abstracts away sampling noise
✅ Enables reasoning at the population level
✅ Supports prediction, comparison, and generation of distributions
✅ Lets us leverages powerful domain-specific generative models to learn distributional structure
✅ Abstracts away sampling noise
✅ Enables reasoning at the population level
✅ Supports prediction, comparison, and generation of distributions
✅ Lets us leverages powerful domain-specific generative models to learn distributional structure
May 26, 2025 at 3:50 PM
3/ Why does this matter?
✅ Abstracts away sampling noise
✅ Enables reasoning at the population level
✅ Supports prediction, comparison, and generation of distributions
✅ Lets us leverages powerful domain-specific generative models to learn distributional structure
✅ Abstracts away sampling noise
✅ Enables reasoning at the population level
✅ Supports prediction, comparison, and generation of distributions
✅ Lets us leverages powerful domain-specific generative models to learn distributional structure
2/ GDEs show that all you need is:
1. an encoder that maps samples to a latent representation and
2. any conditional generative model that samples from the distribution conditional on the latent
to lift autoencoders from points to distributions!
1. an encoder that maps samples to a latent representation and
2. any conditional generative model that samples from the distribution conditional on the latent
to lift autoencoders from points to distributions!
May 26, 2025 at 3:49 PM
2/ GDEs show that all you need is:
1. an encoder that maps samples to a latent representation and
2. any conditional generative model that samples from the distribution conditional on the latent
to lift autoencoders from points to distributions!
1. an encoder that maps samples to a latent representation and
2. any conditional generative model that samples from the distribution conditional on the latent
to lift autoencoders from points to distributions!
1/ Real-world problems are hierarchical: we observe sets of datapoints from a distribution.
- Cells grouped by clone or patient
- Sequences by tissue, time, or location
And we want to model the clone, the patient, or the tissue, not just the individual points.
- Cells grouped by clone or patient
- Sequences by tissue, time, or location
And we want to model the clone, the patient, or the tissue, not just the individual points.
May 26, 2025 at 3:49 PM
1/ Real-world problems are hierarchical: we observe sets of datapoints from a distribution.
- Cells grouped by clone or patient
- Sequences by tissue, time, or location
And we want to model the clone, the patient, or the tissue, not just the individual points.
- Cells grouped by clone or patient
- Sequences by tissue, time, or location
And we want to model the clone, the patient, or the tissue, not just the individual points.
A brief postscript: there are a lot of technical ideas under the hood here, using tricks from the causal inference literature to formulate sensitivity analysis as a non-convex optimization problem. One exciting direction is unpacking when/why the resulting problems are easy to solve.
December 12, 2024 at 5:11 PM
A brief postscript: there are a lot of technical ideas under the hood here, using tricks from the causal inference literature to formulate sensitivity analysis as a non-convex optimization problem. One exciting direction is unpacking when/why the resulting problems are easy to solve.
This project was so much fun to work on with Jake Fawkes,
@bayesianboy.bsky.social, and @zacharylipton.bsky.social! You can find full details in the paper here: arxiv.org/abs/2410.09600.
Looking forward to discussing how we can build more nuanced approaches to fairness in machine learning! 5/5
@bayesianboy.bsky.social, and @zacharylipton.bsky.social! You can find full details in the paper here: arxiv.org/abs/2410.09600.
Looking forward to discussing how we can build more nuanced approaches to fairness in machine learning! 5/5

The Fragility of Fairness: Causal Sensitivity Analysis for Fair Machine Learning
Fairness metrics are a core tool in the fair machine learning literature (FairML), used to determine that ML models are, in some sense, "fair". Real-world data, however, are typically plagued by vario...
arxiv.org
December 12, 2024 at 5:10 PM
This project was so much fun to work on with Jake Fawkes,
@bayesianboy.bsky.social, and @zacharylipton.bsky.social! You can find full details in the paper here: arxiv.org/abs/2410.09600.
Looking forward to discussing how we can build more nuanced approaches to fairness in machine learning! 5/5
@bayesianboy.bsky.social, and @zacharylipton.bsky.social! You can find full details in the paper here: arxiv.org/abs/2410.09600.
Looking forward to discussing how we can build more nuanced approaches to fairness in machine learning! 5/5
Our framework allows researchers to:
- Model complex measurement biases
- Encode domain-specific constraints
- Systematically explore metric sensitivity
Stop by our poster today from 4:30-7:30pm in the West Ballroom to learn about rigorous fairness evals and beyond! 4 / 5
- Model complex measurement biases
- Encode domain-specific constraints
- Systematically explore metric sensitivity
Stop by our poster today from 4:30-7:30pm in the West Ballroom to learn about rigorous fairness evals and beyond! 4 / 5
December 12, 2024 at 5:09 PM
Our framework allows researchers to:
- Model complex measurement biases
- Encode domain-specific constraints
- Systematically explore metric sensitivity
Stop by our poster today from 4:30-7:30pm in the West Ballroom to learn about rigorous fairness evals and beyond! 4 / 5
- Model complex measurement biases
- Encode domain-specific constraints
- Systematically explore metric sensitivity
Stop by our poster today from 4:30-7:30pm in the West Ballroom to learn about rigorous fairness evals and beyond! 4 / 5
Another key insight: Not all fairness metrics are created equal. Our sensitivity analysis shows how different metrics respond to measurement biases - some are surprisingly fragile, others more robust. 3 / 5

December 12, 2024 at 5:08 PM
Another key insight: Not all fairness metrics are created equal. Our sensitivity analysis shows how different metrics respond to measurement biases - some are surprisingly fragile, others more robust. 3 / 5
Our research reveals a critical challenge: real-world datasets often have multiple measurement errors, and small measurement errors can completely change fariness analysis. We analyzed 14 benchmark datasets to understand these complex interactions. 2 / 5

December 12, 2024 at 5:07 PM
Our research reveals a critical challenge: real-world datasets often have multiple measurement errors, and small measurement errors can completely change fariness analysis. We analyzed 14 benchmark datasets to understand these complex interactions. 2 / 5
Between the validation and test distribution? Or equivalently between the distribution you conformalize on and future data.
October 11, 2023 at 4:01 PM
Between the validation and test distribution? Or equivalently between the distribution you conformalize on and future data.
I dont think this is exactly right? I think you're assuming the same amount and form of unpredictability. Which I agree is an assumption but weaker than just "predictability".
October 11, 2023 at 3:26 PM
I dont think this is exactly right? I think you're assuming the same amount and form of unpredictability. Which I agree is an assumption but weaker than just "predictability".
Sure heres a few papers with clear applications:
1. academic.oup.com/jrsssb/artic...
2. www.pnas.org/doi/10.1073/...
3. www.pnas.org/doi/abs/10.1...
4. arxiv.org/abs/2303.01422
1. academic.oup.com/jrsssb/artic...
2. www.pnas.org/doi/10.1073/...
3. www.pnas.org/doi/abs/10.1...
4. arxiv.org/abs/2303.01422
October 8, 2023 at 4:31 PM
Sure heres a few papers with clear applications:
1. academic.oup.com/jrsssb/artic...
2. www.pnas.org/doi/10.1073/...
3. www.pnas.org/doi/abs/10.1...
4. arxiv.org/abs/2303.01422
1. academic.oup.com/jrsssb/artic...
2. www.pnas.org/doi/10.1073/...
3. www.pnas.org/doi/abs/10.1...
4. arxiv.org/abs/2303.01422