



Neel Rajani
@neelrajani.bsky.social
PhD student in Responsible NLP at the University of Edinburgh, curious about interpretability and alignment
Caught off-guard by the Llama 3.3 release? This is the loss of Llama-3.3-70B-Instruct (4bit quantized) on its own Twitter release thread. It really didn't like ' RL' (loss of 13.47) and wanted the text to instead go "... progress in online learning, which allows the model to adapt"

December 8, 2024 at 10:33 PM
Caught off-guard by the Llama 3.3 release? This is the loss of Llama-3.3-70B-Instruct (4bit quantized) on its own Twitter release thread. It really didn't like ' RL' (loss of 13.47) and wanted the text to instead go "... progress in online learning, which allows the model to adapt"
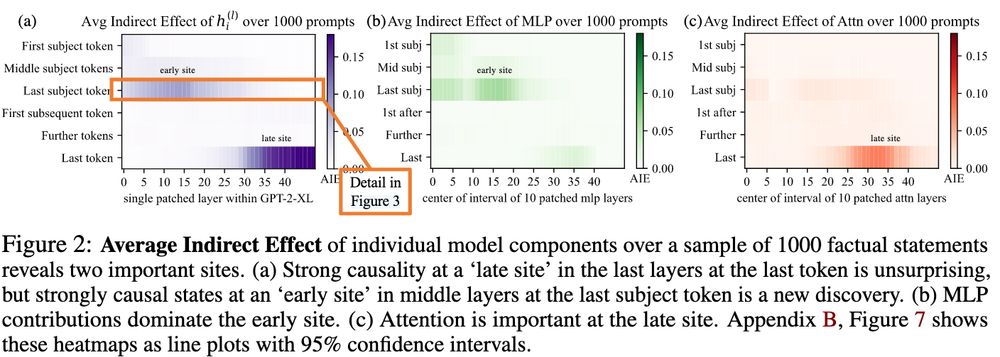
'late site' Attn results replicate somewhat, though this does not look as clean as their results on GPT-2-XL! There does seem to be non-negligible 'late site' MLP Indirect Effect for Llama 3.1 8B. I wonder how this affects their hypothesis? But keep in mind this is only for one Llama model! 3/3
December 3, 2024 at 5:32 PM
'late site' Attn results replicate somewhat, though this does not look as clean as their results on GPT-2-XL! There does seem to be non-negligible 'late site' MLP Indirect Effect for Llama 3.1 8B. I wonder how this affects their hypothesis? But keep in mind this is only for one Llama model! 3/3
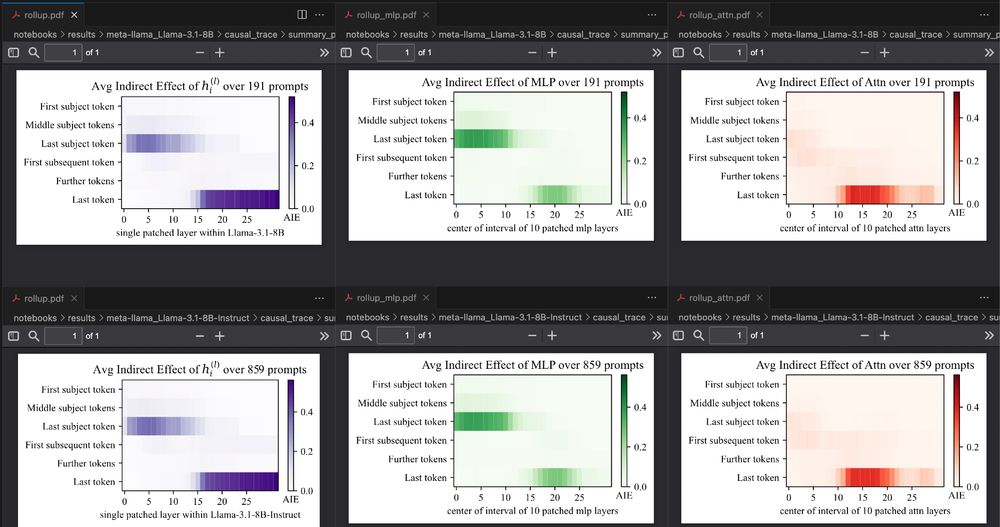
Do instruct models store factual associations differently than base models? 🤔 Doesn't look like it! When adapting ROME's causal tracing code to Llama 3.1 8B, the plots look very similar (base on top, instruct at the bottom). Note the larger sample size for instruct: If the "correct prediction" 1/3
December 3, 2024 at 5:32 PM
Do instruct models store factual associations differently than base models? 🤔 Doesn't look like it! When adapting ROME's causal tracing code to Llama 3.1 8B, the plots look very similar (base on top, instruct at the bottom). Note the larger sample size for instruct: If the "correct prediction" 1/3
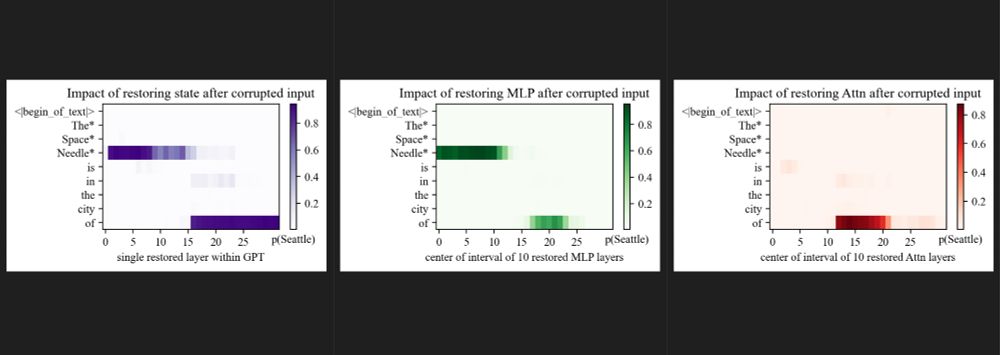
2/2 My hacky attempt at changing their codebase to accept Llama3.1 8B Instruct. Pretty cool that the 'early-site/late-site' findings replicate somewhat even on a single sample. Very curious for my sweep of the full 1209 samples from their paper to finish for more representative results :D
November 24, 2024 at 11:21 PM
2/2 My hacky attempt at changing their codebase to accept Llama3.1 8B Instruct. Pretty cool that the 'early-site/late-site' findings replicate somewhat even on a single sample. Very curious for my sweep of the full 1209 samples from their paper to finish for more representative results :D
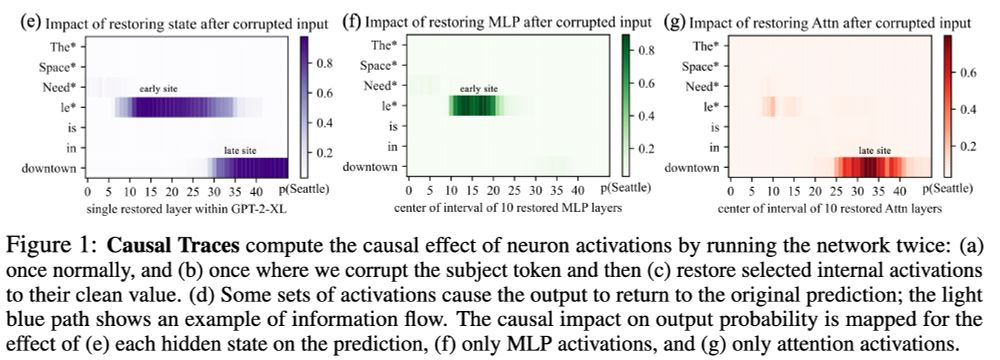
1/2 The original 2022 ROME paper by Meng et al.:
November 24, 2024 at 11:15 PM
1/2 The original 2022 ROME paper by Meng et al.: