



Neel Rajani
@neelrajani.bsky.social
PhD student in Responsible NLP at the University of Edinburgh, curious about interpretability and alignment
Reposted by Neel Rajani

MMLU-Redux just touched down at #NAACL2025! 🎉
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋

May 2, 2025 at 1:00 PM
MMLU-Redux just touched down at #NAACL2025! 🎉
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
Come say hi :)

Join us at AI for All during Edinburgh Science Festival! Discover how we make #NLP shape our daily lives in a fair, accountable and transparent way. Explore exhibits, activities, and meet the next generation of researchers.
📅 Fri 11 Apr
⏰ 10am – 4pm|Free / Drop-In
📍@edfuturesinstitute.bsky.social
📅 Fri 11 Apr
⏰ 10am – 4pm|Free / Drop-In
📍@edfuturesinstitute.bsky.social

April 11, 2025 at 8:53 AM
Come say hi :)
Caught off-guard by the Llama 3.3 release? This is the loss of Llama-3.3-70B-Instruct (4bit quantized) on its own Twitter release thread. It really didn't like ' RL' (loss of 13.47) and wanted the text to instead go "... progress in online learning, which allows the model to adapt"

December 8, 2024 at 10:33 PM
Caught off-guard by the Llama 3.3 release? This is the loss of Llama-3.3-70B-Instruct (4bit quantized) on its own Twitter release thread. It really didn't like ' RL' (loss of 13.47) and wanted the text to instead go "... progress in online learning, which allows the model to adapt"
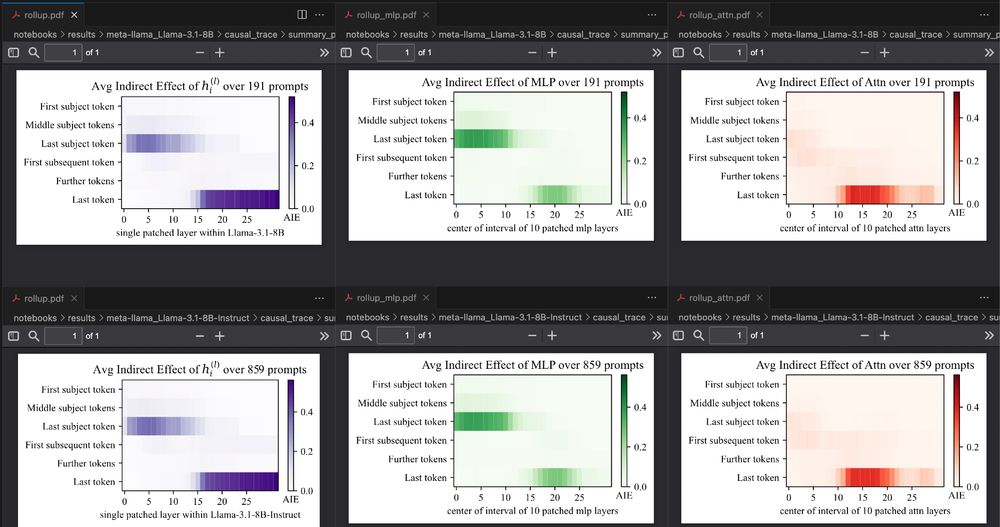
Do instruct models store factual associations differently than base models? 🤔 Doesn't look like it! When adapting ROME's causal tracing code to Llama 3.1 8B, the plots look very similar (base on top, instruct at the bottom). Note the larger sample size for instruct: If the "correct prediction" 1/3
December 3, 2024 at 5:32 PM
Do instruct models store factual associations differently than base models? 🤔 Doesn't look like it! When adapting ROME's causal tracing code to Llama 3.1 8B, the plots look very similar (base on top, instruct at the bottom). Note the larger sample size for instruct: If the "correct prediction" 1/3
Reposted by Neel Rajani

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
November 20, 2024 at 4:35 PM
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Reposted by Neel Rajani


November 25, 2024 at 4:47 AM
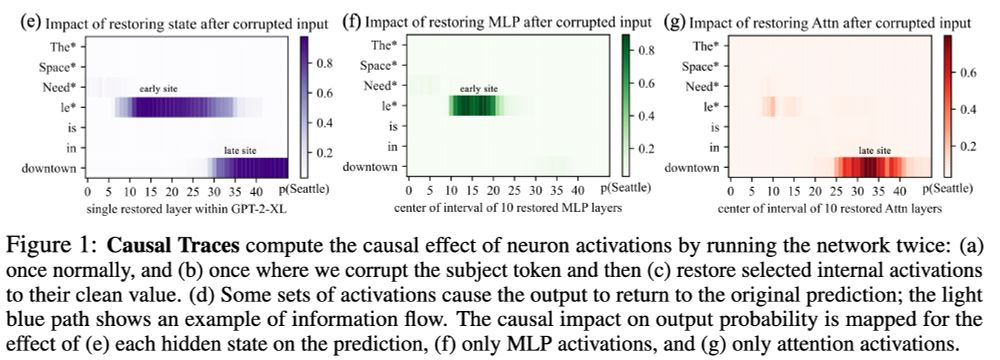
1/2 The original 2022 ROME paper by Meng et al.:
November 24, 2024 at 11:15 PM
1/2 The original 2022 ROME paper by Meng et al.: