


Nathaniel Blalock
@nathanielblalock.bsky.social
Graduate Research Assistant in Dr. Philip Romero's Lab at Duke/Wisconsin Reinforcement and Deep Learning for Protein Redesign | He/him
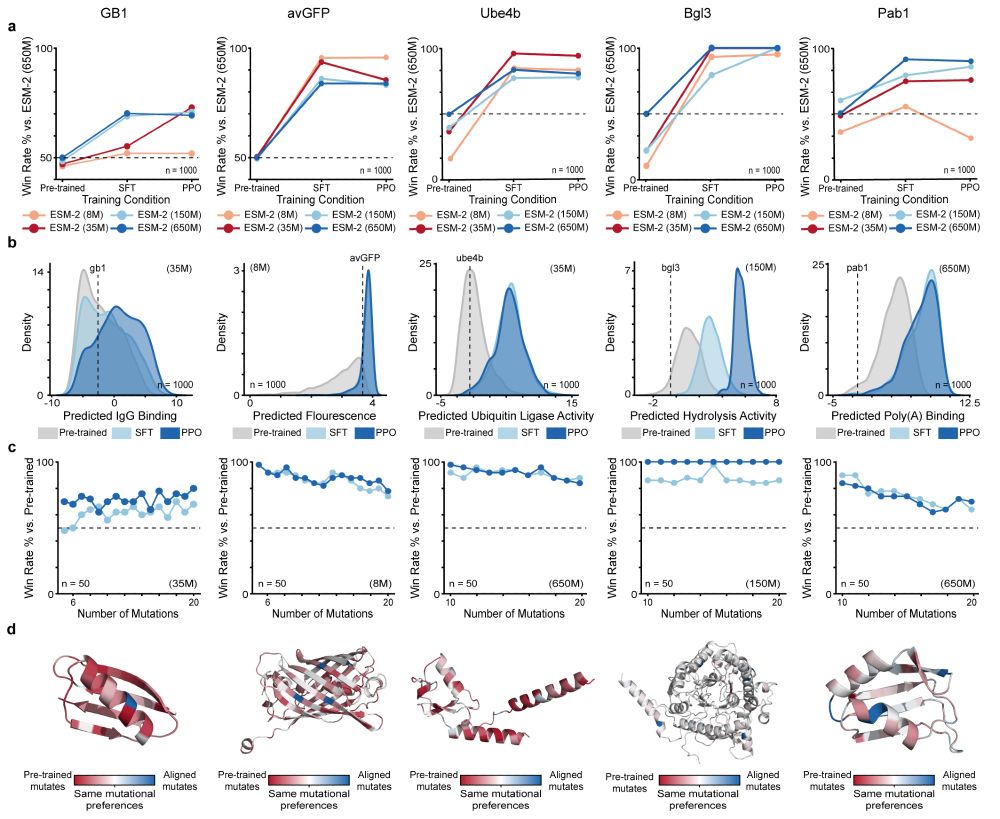
We apply RLXF across five diverse protein classes to demonstrate its generalizability and effectiveness at generating optimized sequences by learning functional constraints beyond those captured during pre-training
May 8, 2025 at 6:02 PM
We apply RLXF across five diverse protein classes to demonstrate its generalizability and effectiveness at generating optimized sequences by learning functional constraints beyond those captured during pre-training
Experimental validation reveals the RLXF-aligned model generates a higher fraction of functional sequences, a greater number of sequences more fluorescent than CreiLOV, and the brightest oxygen-independent fluorescent protein variant reported to date

May 8, 2025 at 6:02 PM
Experimental validation reveals the RLXF-aligned model generates a higher fraction of functional sequences, a greater number of sequences more fluorescent than CreiLOV, and the brightest oxygen-independent fluorescent protein variant reported to date
We align ESM-2 to experimental fluorescence data from the CreiLOV flavin-binding fluorescent protein. The aligned model learns to prioritize mutations that enhance fluorescence, many of which are missed by the base model

May 8, 2025 at 6:02 PM
We align ESM-2 to experimental fluorescence data from the CreiLOV flavin-binding fluorescent protein. The aligned model learns to prioritize mutations that enhance fluorescence, many of which are missed by the base model
RLXF follows a two-phase strategy inspired by RLHF. Supervised Fine-Tuning initializes the model in the right region of sequence space. Proximal Policy Optimization directly aligns sequence generation with feedback from a reward function like a sequence-function predictor

May 8, 2025 at 6:02 PM
RLXF follows a two-phase strategy inspired by RLHF. Supervised Fine-Tuning initializes the model in the right region of sequence space. Proximal Policy Optimization directly aligns sequence generation with feedback from a reward function like a sequence-function predictor
We are excited in the @philromero.bsky.social lab to share our new preprint introducing RLXF for the functional alignment of protein language models (pLMs) with experimentally derived notions of biomolecular function!

May 8, 2025 at 6:02 PM
We are excited in the @philromero.bsky.social lab to share our new preprint introducing RLXF for the functional alignment of protein language models (pLMs) with experimentally derived notions of biomolecular function!
Favorite foods! Tandoori chicken and chili momo's: everestkitchen.ca. Onigiri! www.onigiriya.ca. Pho: www.viethouserestaurant.com.



December 20, 2024 at 4:59 PM
Favorite foods! Tandoori chicken and chili momo's: everestkitchen.ca. Onigiri! www.onigiriya.ca. Pho: www.viethouserestaurant.com.