




Material Scientist
@mtrl-scientist.bsky.social
Founder
Shitposter
Data wrangler
Shitposter
Data wrangler
- traefik
- few DBs (postgres, mysql)
- distributed storage (SeaweedFS)
- JDownloader
- pihole
- few DBs (postgres, mysql)
- distributed storage (SeaweedFS)
- JDownloader
- pihole
October 6, 2025 at 5:13 PM
- traefik
- few DBs (postgres, mysql)
- distributed storage (SeaweedFS)
- JDownloader
- pihole
- few DBs (postgres, mysql)
- distributed storage (SeaweedFS)
- JDownloader
- pihole
Nomad to orchestrate, Consul to network & secure with service mesh, Vault for credentials.
Running on Nomad:
- Observability stack (Vector, loki, prometheus, grafana)
- CSI volumes
- Messaging (NATS)
- micro-services (n8n workflows)
- some python jobs
- Local AI
...
Running on Nomad:
- Observability stack (Vector, loki, prometheus, grafana)
- CSI volumes
- Messaging (NATS)
- micro-services (n8n workflows)
- some python jobs
- Local AI
...
October 6, 2025 at 5:09 PM
Nomad to orchestrate, Consul to network & secure with service mesh, Vault for credentials.
Running on Nomad:
- Observability stack (Vector, loki, prometheus, grafana)
- CSI volumes
- Messaging (NATS)
- micro-services (n8n workflows)
- some python jobs
- Local AI
...
Running on Nomad:
- Observability stack (Vector, loki, prometheus, grafana)
- CSI volumes
- Messaging (NATS)
- micro-services (n8n workflows)
- some python jobs
- Local AI
...
ofc one could argue that you might as well mount to the host directly...
but CSI mounts give you lifecycle management
so.... suck it docker!😁
but CSI mounts give you lifecycle management
so.... suck it docker!😁
August 3, 2025 at 10:17 AM
ofc one could argue that you might as well mount to the host directly...
but CSI mounts give you lifecycle management
so.... suck it docker!😁
but CSI mounts give you lifecycle management
so.... suck it docker!😁
Cool stuff man, looking forward!
June 18, 2025 at 3:16 PM
Cool stuff man, looking forward!
Ah OK!
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
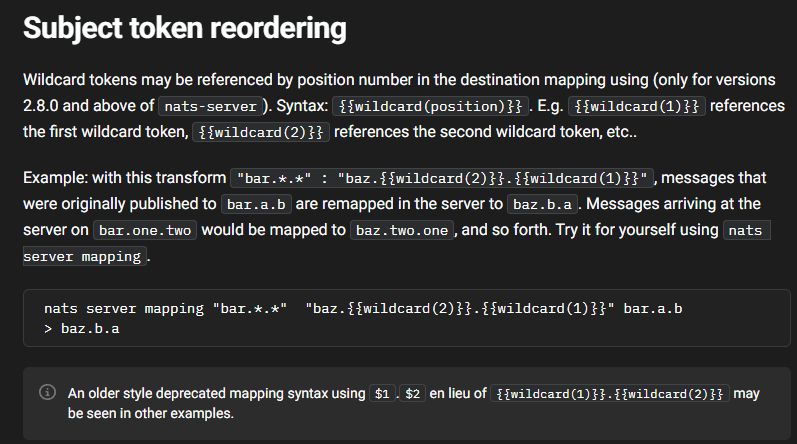
June 18, 2025 at 1:56 PM
Ah OK!
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
What am I looking at here?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
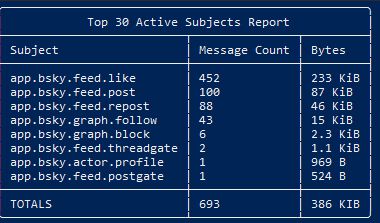
June 18, 2025 at 1:07 PM
What am I looking at here?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
Not always. Databento for example
December 30, 2024 at 10:21 AM
Not always. Databento for example
Added more time on fish-head nebula and did pacman nebula as well this night.
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁



December 27, 2024 at 12:33 AM
Added more time on fish-head nebula and did pacman nebula as well this night.
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁

Andromeda galaxy

December 16, 2024 at 9:16 PM
Andromeda galaxy
Saturn timelapse
December 16, 2024 at 9:16 PM
Saturn timelapse
Moon timelapse
December 16, 2024 at 9:16 PM
Moon timelapse
Awesome, thanks for sharing!
Lots of stuff about xarray & projections that's also useful for non-geosciences.
Lots of stuff about xarray & projections that's also useful for non-geosciences.
December 15, 2024 at 12:34 PM
Awesome, thanks for sharing!
Lots of stuff about xarray & projections that's also useful for non-geosciences.
Lots of stuff about xarray & projections that's also useful for non-geosciences.