




Material Scientist
@mtrl-scientist.bsky.social
Founder
Shitposter
Data wrangler
Shitposter
Data wrangler

August 3, 2025 at 10:18 AM
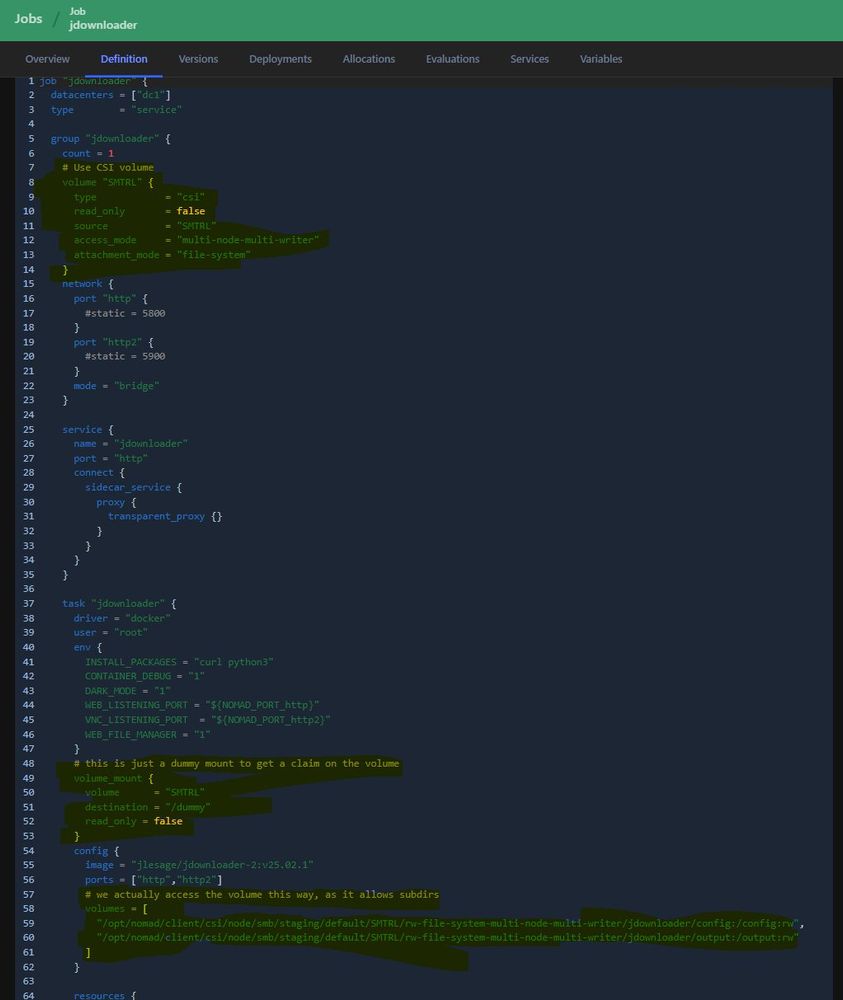
I'm pretty sure this is not how you're supposed to use CSI mounts, but hey - it successfully circumvents the limitations of not being able to mount subdirs w/o having to create a volume for each one 😁
#Nomad #Hashistack #CSI #Docker
#Nomad #Hashistack #CSI #Docker
August 3, 2025 at 10:17 AM
I'm pretty sure this is not how you're supposed to use CSI mounts, but hey - it successfully circumvents the limitations of not being able to mount subdirs w/o having to create a volume for each one 😁
#Nomad #Hashistack #CSI #Docker
#Nomad #Hashistack #CSI #Docker
Ah OK!
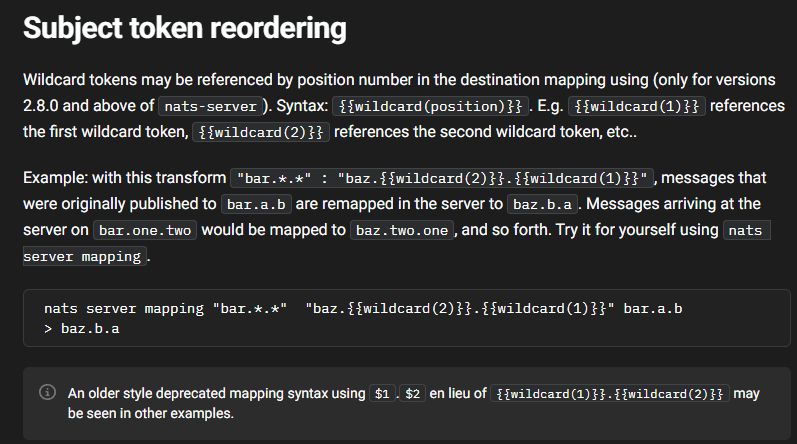
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
June 18, 2025 at 1:56 PM
Ah OK!
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
If you're running your own jetstream, would it make sense to simply put those links in the subject (w/o re-emitting) and just re-order via NATS subject mapping for letting others access by did on ws?
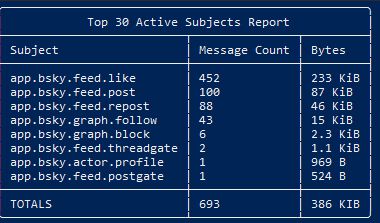
What am I looking at here?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
June 18, 2025 at 1:07 PM
What am I looking at here?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
So, the default jetstream is something like `app.bsky.feed.like`, and you're prepending the `target` account?
Does that mean you can subscribe to just updates on a particular user?
Dayum!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!

December 28, 2024 at 2:16 PM
Dayum!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!
Added more time on fish-head nebula and did pacman nebula as well this night.
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁



December 27, 2024 at 12:33 AM
Added more time on fish-head nebula and did pacman nebula as well this night.
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁
Realized you get way more recording time if you disable real-time stacking! (duh)
Bonus: pug in heated bike trailer 😁
@ninasch.bsky.social and I nearly froze our butts off for these last night
Fish head nebula was particularly nice!
Fish head nebula was particularly nice!




December 26, 2024 at 10:38 AM
@ninasch.bsky.social and I nearly froze our butts off for these last night
Fish head nebula was particularly nice!
Fish head nebula was particularly nice!
Every hour of every day!

December 17, 2024 at 7:56 PM
Every hour of every day!

Andromeda galaxy

December 16, 2024 at 9:16 PM
Andromeda galaxy
Saturn timelapse
December 16, 2024 at 9:16 PM
Saturn timelapse
Moon timelapse
December 16, 2024 at 9:16 PM
Moon timelapse
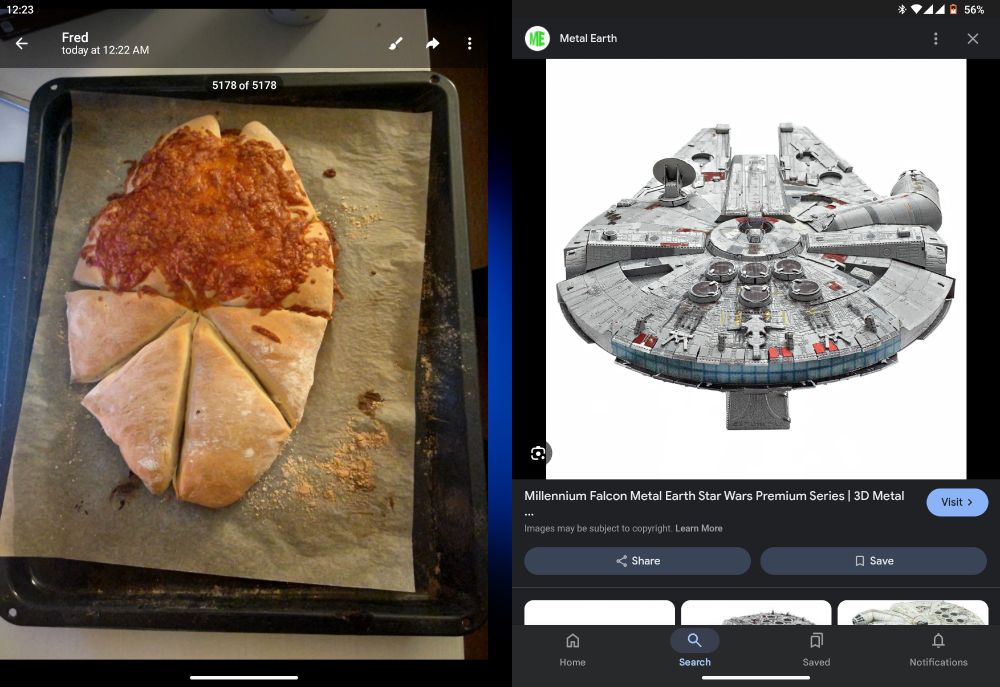
Impulsive decision: midnight Millennium bread 😂
December 11, 2024 at 12:01 AM
Impulsive decision: midnight Millennium bread 😂
When I tickle my wife's feet
December 9, 2024 at 11:25 PM
When I tickle my wife's feet
Oh man...
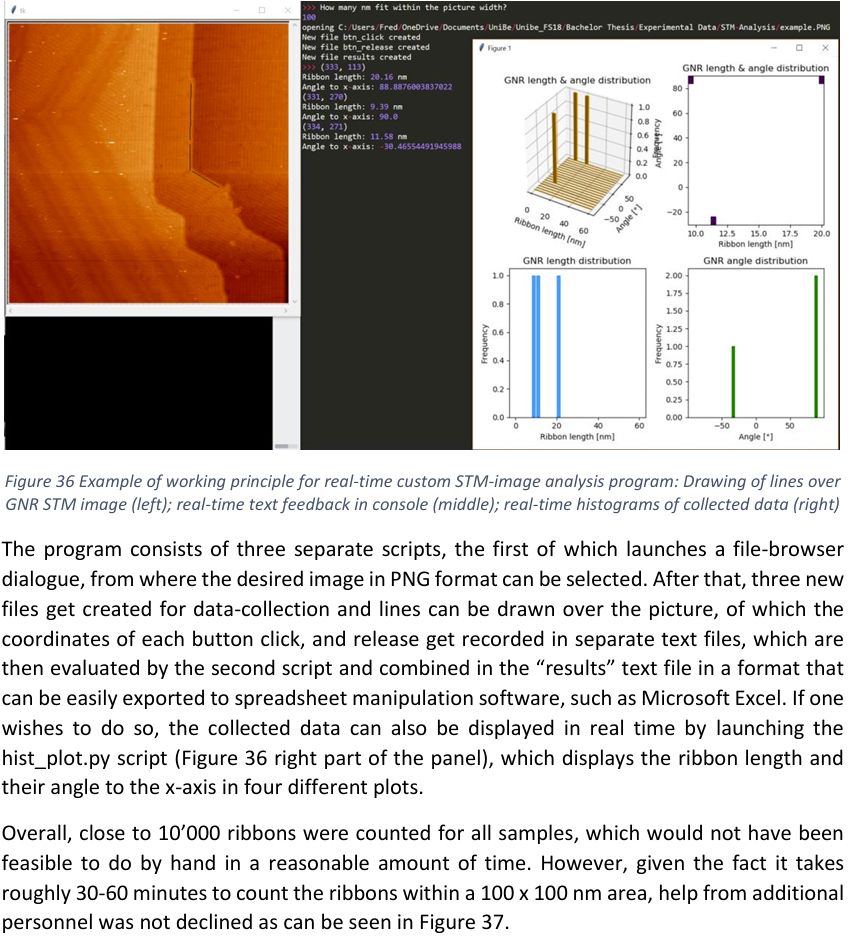
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
December 7, 2024 at 6:31 PM
Oh man...
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
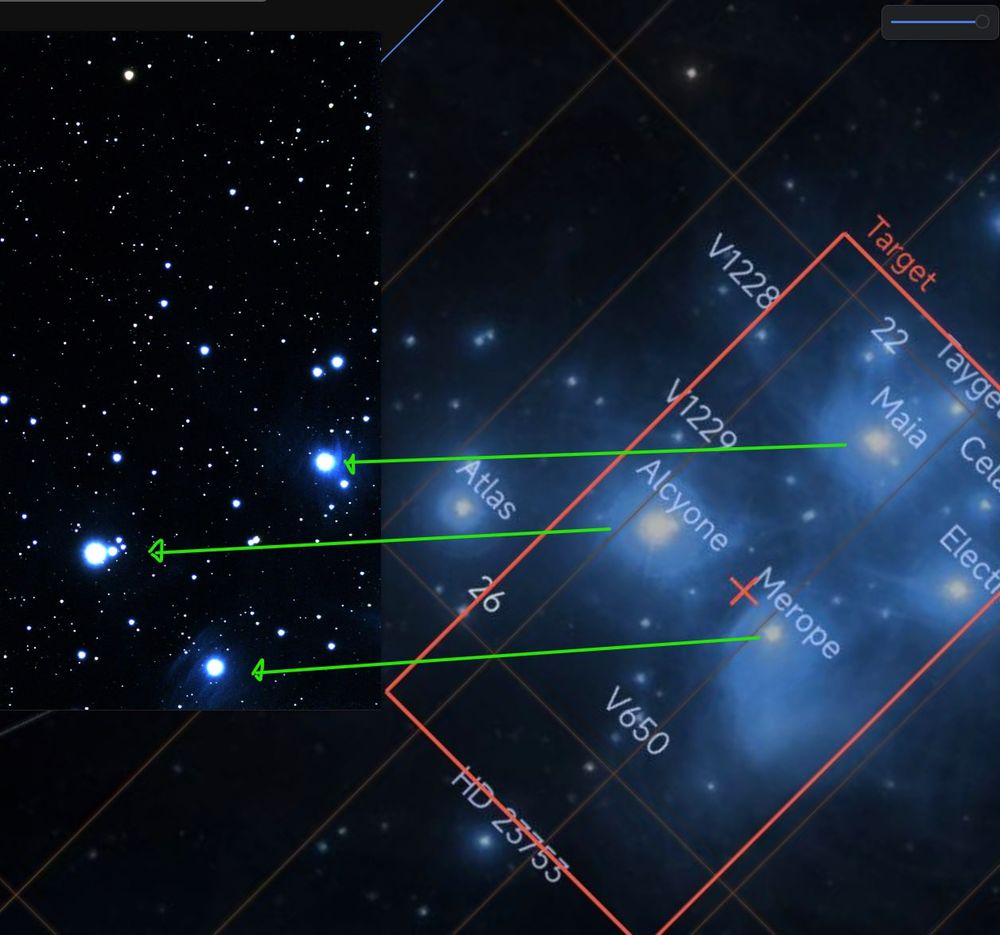
First attempt at astrophotography with Seestar S50
10min integration of pleiades & postprocessing by @ninasch.bsky.social
10min integration of pleiades & postprocessing by @ninasch.bsky.social

December 5, 2024 at 11:28 PM
First attempt at astrophotography with Seestar S50
10min integration of pleiades & postprocessing by @ninasch.bsky.social
10min integration of pleiades & postprocessing by @ninasch.bsky.social

Every time I want to make a small change and re-build the docker image...

November 25, 2024 at 9:28 PM
Every time I want to make a small change and re-build the docker image...
So...
Jetstream saves data in fixed-size blocks (default is 8MB).
I suppose one could set up a watcher script, and move done blocks to a different storage tier, then symlink those files to the original directory to achieve tiered storage for Jetstream?
Jetstream saves data in fixed-size blocks (default is 8MB).
I suppose one could set up a watcher script, and move done blocks to a different storage tier, then symlink those files to the original directory to achieve tiered storage for Jetstream?

November 24, 2024 at 7:39 PM
So...
Jetstream saves data in fixed-size blocks (default is 8MB).
I suppose one could set up a watcher script, and move done blocks to a different storage tier, then symlink those files to the original directory to achieve tiered storage for Jetstream?
Jetstream saves data in fixed-size blocks (default is 8MB).
I suppose one could set up a watcher script, and move done blocks to a different storage tier, then symlink those files to the original directory to achieve tiered storage for Jetstream?
And here's the local replay
November 22, 2024 at 10:44 PM
And here's the local replay
Here's a Nomad job to:
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance



November 22, 2024 at 10:44 PM
Here's a Nomad job to:
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance
About myself:
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting

November 20, 2024 at 11:40 PM
About myself:
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
After reviewing whatever logs I still have about this, it seems like one of the volume nodes OOM'd at the time, resulting in insufficient replication (010), which is why the filesystem's CSI driver refused to write (no more writable volumes).
So, now bumped up the volume nodes' RAM.
So, now bumped up the volume nodes' RAM.

November 19, 2024 at 10:52 PM
After reviewing whatever logs I still have about this, it seems like one of the volume nodes OOM'd at the time, resulting in insufficient replication (010), which is why the filesystem's CSI driver refused to write (no more writable volumes).
So, now bumped up the volume nodes' RAM.
So, now bumped up the volume nodes' RAM.
Huh?
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???



November 19, 2024 at 10:21 PM
Huh?
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???
"We have docker registry at home"
The docker registry at home haha:
The docker registry at home haha:

November 16, 2024 at 2:04 PM
"We have docker registry at home"
The docker registry at home haha:
The docker registry at home haha: