



Moritz Haas
@mohaas.bsky.social
IMPRS-IS PhD student @ University of Tübingen with Ulrike von Luxburg and Bedartha Goswami. Mostly thinking about deep learning theory. Also interested in ML for climate science.
mohawastaken.github.io
mohawastaken.github.io
This is joint work with wonderful collaborators @leenacvankadara.bsky.social , @cevherlions.bsky.social and Jin Xu during our time at Amazon.
🧵 10/10
🧵 10/10
arxiv.org
December 10, 2024 at 7:08 AM
This is joint work with wonderful collaborators @leenacvankadara.bsky.social , @cevherlions.bsky.social and Jin Xu during our time at Amazon.
🧵 10/10
🧵 10/10
How achieve correct scaling with arbitrary gradient-based perturbation rules? 🤔
✨In 𝝁P, scale perturbations like updates in every layer.✨
💡Gradients and incoming activations generally scale LLN-like, as they are correlated.
➡️ Perturbations and updates have similar scaling properties.
🧵 9/10
December 10, 2024 at 7:08 AM
How achieve correct scaling with arbitrary gradient-based perturbation rules? 🤔
✨In 𝝁P, scale perturbations like updates in every layer.✨
💡Gradients and incoming activations generally scale LLN-like, as they are correlated.
➡️ Perturbations and updates have similar scaling properties.
🧵 9/10
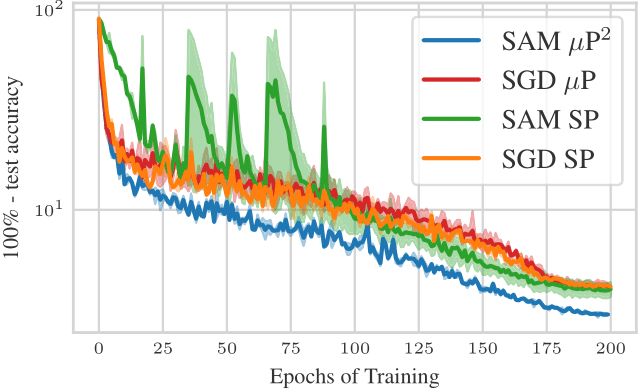
In experiments across MLPs and ResNets on CIFAR10 and ViTs on ImageNet1K, we show that 𝝁P² indeed jointly transfers optimal learning rate and perturbation radius across model scales and can improve training stability and generalization.
🧵 8/10

December 10, 2024 at 7:08 AM
In experiments across MLPs and ResNets on CIFAR10 and ViTs on ImageNet1K, we show that 𝝁P² indeed jointly transfers optimal learning rate and perturbation radius across model scales and can improve training stability and generalization.
🧵 8/10
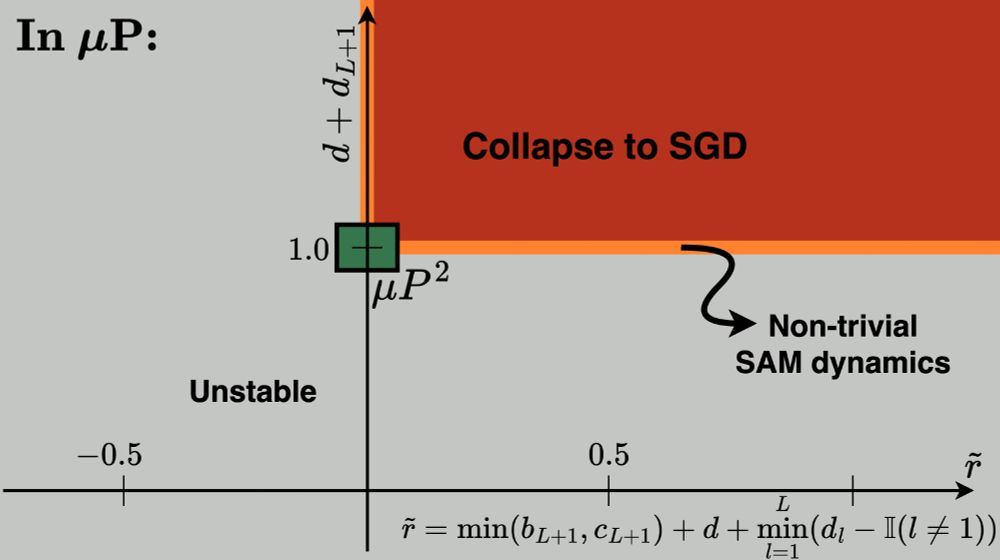
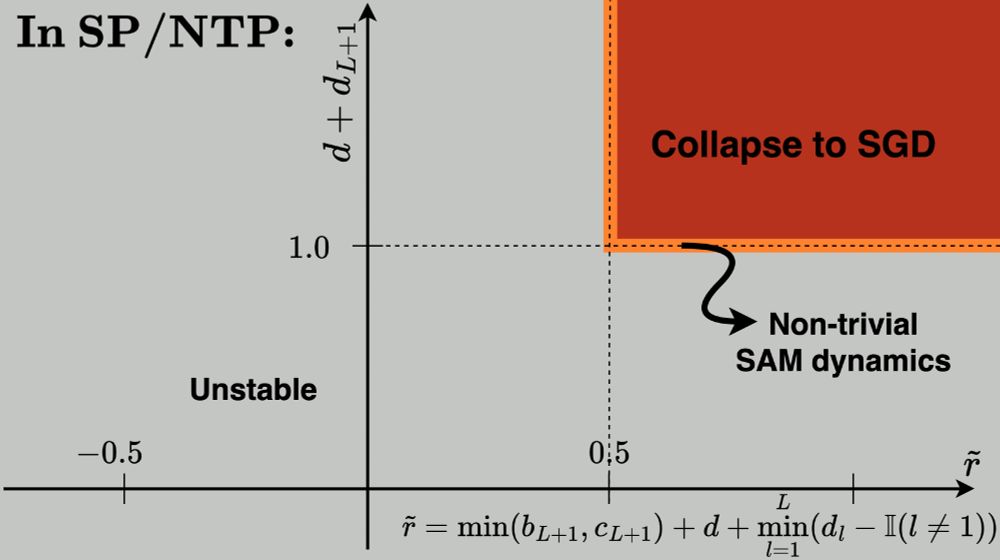
... there exists a ✨unique✨ parameterization with layerwise perturbation scaling that fulfills all of our constraints:
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
December 10, 2024 at 7:08 AM
... there exists a ✨unique✨ parameterization with layerwise perturbation scaling that fulfills all of our constraints:
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
Hence, we study arbitrary layerwise learning rate, initialization variance and perturbation scaling.
For us, an ideal parametrization should fulfill: updates and perturbations of all weights should have a non-vanishing and non-exploding effect on the output function. 💡
We show that ...
🧵 6/10
For us, an ideal parametrization should fulfill: updates and perturbations of all weights should have a non-vanishing and non-exploding effect on the output function. 💡
We show that ...
🧵 6/10
December 10, 2024 at 7:08 AM
Hence, we study arbitrary layerwise learning rate, initialization variance and perturbation scaling.
For us, an ideal parametrization should fulfill: updates and perturbations of all weights should have a non-vanishing and non-exploding effect on the output function. 💡
We show that ...
🧵 6/10
For us, an ideal parametrization should fulfill: updates and perturbations of all weights should have a non-vanishing and non-exploding effect on the output function. 💡
We show that ...
🧵 6/10
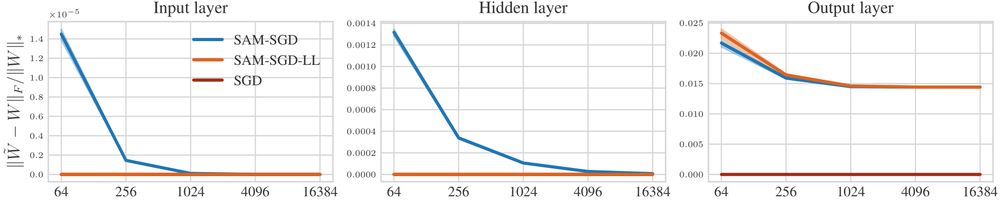
... we show that 𝝁P is not able to consistently improve generalization or to transfer SAM's perturbation radius, because it effectively only perturbs the last layer. ❌
💡So we need to allow layerwise perturbation scaling!
🧵 5/10
December 10, 2024 at 7:08 AM
... we show that 𝝁P is not able to consistently improve generalization or to transfer SAM's perturbation radius, because it effectively only perturbs the last layer. ❌
💡So we need to allow layerwise perturbation scaling!
🧵 5/10
The maximal update parametrization (𝝁P) by arxiv.org/abs/2011.14522 is a layerwise scaling rule of learning rates and initialization variances that yields width-independent dynamics and learning rate transfer for SGD and Adam in common architectures. But for standard SAM, ...
🧵 4/10
🧵 4/10

Feature Learning in Infinite-Width Neural Networks
As its width tends to infinity, a deep neural network's behavior under gradient descent can become simplified and predictable (e.g. given by the Neural Tangent Kernel (NTK)), if it is parametrized app...
arxiv.org
December 10, 2024 at 7:08 AM
The maximal update parametrization (𝝁P) by arxiv.org/abs/2011.14522 is a layerwise scaling rule of learning rates and initialization variances that yields width-independent dynamics and learning rate transfer for SGD and Adam in common architectures. But for standard SAM, ...
🧵 4/10
🧵 4/10
SAM and model scale are widely observed to improve generalization across datasets and architectures. But can we understand how to optimally scale in a principled way? 📈🤔
🧵 3/10
🧵 3/10
December 10, 2024 at 7:08 AM
SAM and model scale are widely observed to improve generalization across datasets and architectures. But can we understand how to optimally scale in a principled way? 📈🤔
🧵 3/10
🧵 3/10
Short thread for effective SAM scaling here.
arxiv.org/pdf/2411.00075
A thread on our Mamba scaling will be coming soon by
🔜 @leenacvankadara.bsky.social
🧵2/10
arxiv.org/pdf/2411.00075
A thread on our Mamba scaling will be coming soon by
🔜 @leenacvankadara.bsky.social
🧵2/10
arxiv.org
December 10, 2024 at 7:08 AM
Short thread for effective SAM scaling here.
arxiv.org/pdf/2411.00075
A thread on our Mamba scaling will be coming soon by
🔜 @leenacvankadara.bsky.social
🧵2/10
arxiv.org/pdf/2411.00075
A thread on our Mamba scaling will be coming soon by
🔜 @leenacvankadara.bsky.social
🧵2/10
I'd love to be added :)
November 28, 2024 at 7:28 PM
I'd love to be added :)