



Moritz Haas
@mohaas.bsky.social
IMPRS-IS PhD student @ University of Tübingen with Ulrike von Luxburg and Bedartha Goswami. Mostly thinking about deep learning theory. Also interested in ML for climate science.
mohawastaken.github.io
mohawastaken.github.io
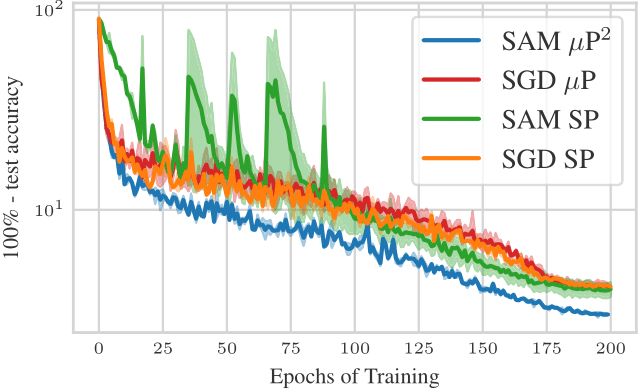
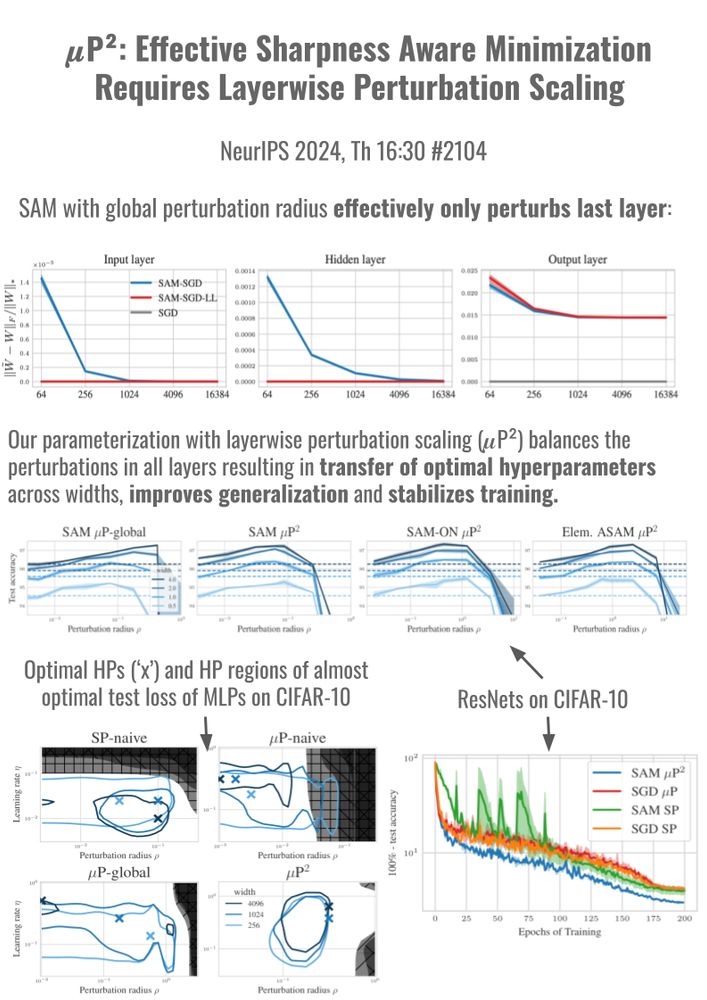
In experiments across MLPs and ResNets on CIFAR10 and ViTs on ImageNet1K, we show that 𝝁P² indeed jointly transfers optimal learning rate and perturbation radius across model scales and can improve training stability and generalization.
🧵 8/10

December 10, 2024 at 7:08 AM
In experiments across MLPs and ResNets on CIFAR10 and ViTs on ImageNet1K, we show that 𝝁P² indeed jointly transfers optimal learning rate and perturbation radius across model scales and can improve training stability and generalization.
🧵 8/10
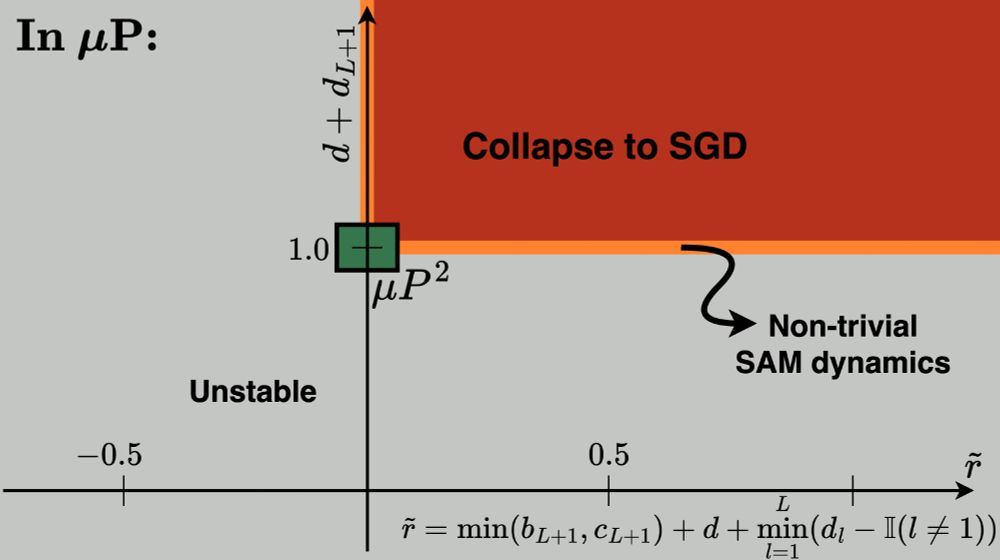
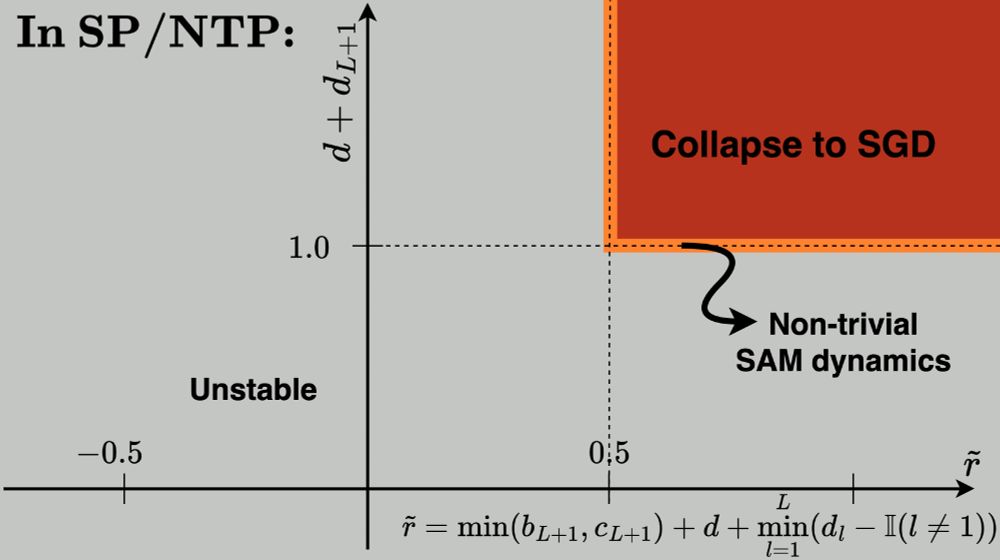
... there exists a ✨unique✨ parameterization with layerwise perturbation scaling that fulfills all of our constraints:
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
December 10, 2024 at 7:08 AM
... there exists a ✨unique✨ parameterization with layerwise perturbation scaling that fulfills all of our constraints:
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
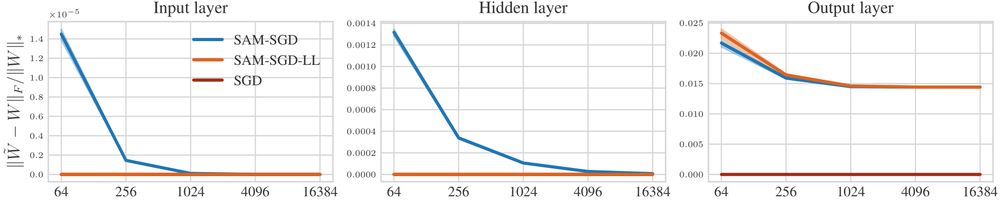
... we show that 𝝁P is not able to consistently improve generalization or to transfer SAM's perturbation radius, because it effectively only perturbs the last layer. ❌
💡So we need to allow layerwise perturbation scaling!
🧵 5/10
December 10, 2024 at 7:08 AM
... we show that 𝝁P is not able to consistently improve generalization or to transfer SAM's perturbation radius, because it effectively only perturbs the last layer. ❌
💡So we need to allow layerwise perturbation scaling!
🧵 5/10
Stable model scaling with width-independent dynamics?
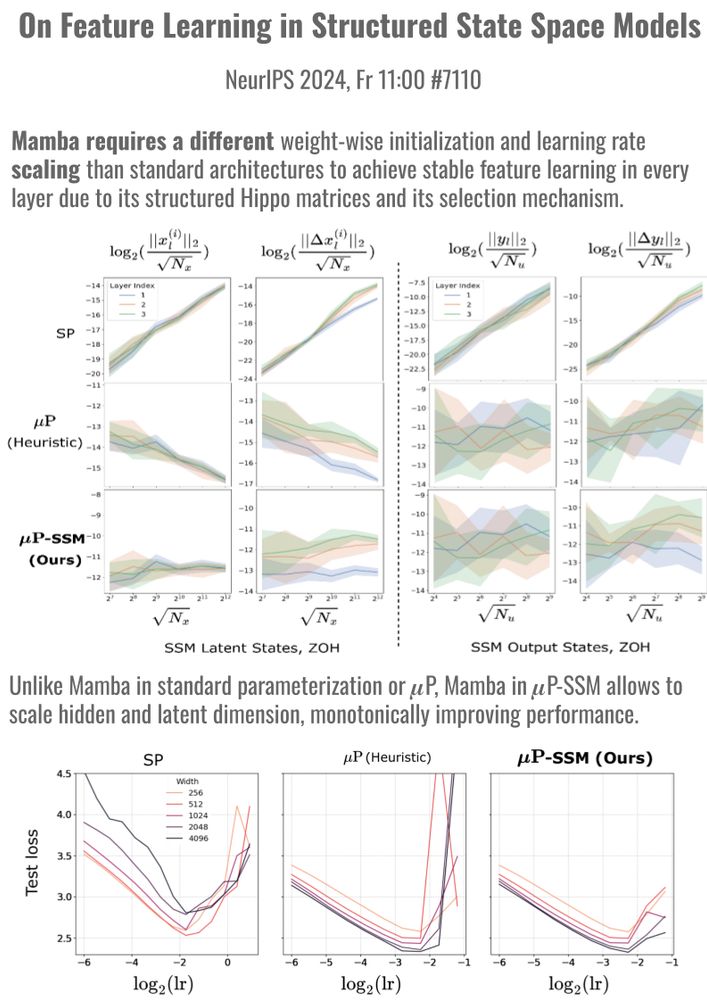
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
December 10, 2024 at 7:08 AM
Stable model scaling with width-independent dynamics?
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10