




Michael Kirchhof (ICML)
@mkirchhof.bsky.social
Research Scientist at Apple for uncertainty quantification.
🚀 Consider a hypothetical hardware storing a bank with three memory levels:
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]

October 6, 2025 at 4:06 PM
🚀 Consider a hypothetical hardware storing a bank with three memory levels:
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]
💡Information access is controllable with memories.
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]

October 6, 2025 at 4:06 PM
💡Information access is controllable with memories.
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]
💡Memories capture long-tail knowledge.
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]

October 6, 2025 at 4:06 PM
💡Memories capture long-tail knowledge.
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]
🤔 Which tasks benefit more from memory?
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]

October 6, 2025 at 4:06 PM
🤔 Which tasks benefit more from memory?
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]
💡Accuracy improves with larger fetched memory and total memory bank sizes.
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]

October 6, 2025 at 4:06 PM
💡Accuracy improves with larger fetched memory and total memory bank sizes.
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]
🤔 Which parametric memories work best?
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]

October 6, 2025 at 4:06 PM
🤔 Which parametric memories work best?
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]
LLMs are currently this one big parameter block that stores all sort of facts. In our new preprint, we add context-specific memory parameters to the model, and pretrain the model along with a big bank of memories.
📑 arxiv.org/abs/2510.02375
[1/10]🧵
📑 arxiv.org/abs/2510.02375
[1/10]🧵
October 6, 2025 at 4:06 PM
LLMs are currently this one big parameter block that stores all sort of facts. In our new preprint, we add context-specific memory parameters to the model, and pretrain the model along with a big bank of memories.
📑 arxiv.org/abs/2510.02375
[1/10]🧵
📑 arxiv.org/abs/2510.02375
[1/10]🧵
Many treat uncertainty = a number. At Apple, we're rethinking this: LLMs should output strings that reveal all information of their internal distributions. We find that Reasoning, SFT, CoT can't do it - yet. To get there, we introduce the SelfReflect benchmark.
arxiv.org/pdf/2505.20295
arxiv.org/pdf/2505.20295

October 1, 2025 at 9:53 AM
Many treat uncertainty = a number. At Apple, we're rethinking this: LLMs should output strings that reveal all information of their internal distributions. We find that Reasoning, SFT, CoT can't do it - yet. To get there, we introduce the SelfReflect benchmark.
arxiv.org/pdf/2505.20295
arxiv.org/pdf/2505.20295
I'll present my view on the future of uncertainties in LLMs and vision models at @icmlconf.bsky.social, in penal discussions, posters, and workshops. Reach out if you wanna chat :)
Here's everything from me and other folks at Apple: machinelearning.apple.com/updates/appl...
Here's everything from me and other folks at Apple: machinelearning.apple.com/updates/appl...

July 13, 2025 at 11:47 PM
I'll present my view on the future of uncertainties in LLMs and vision models at @icmlconf.bsky.social, in penal discussions, posters, and workshops. Reach out if you wanna chat :)
Here's everything from me and other folks at Apple: machinelearning.apple.com/updates/appl...
Here's everything from me and other folks at Apple: machinelearning.apple.com/updates/appl...
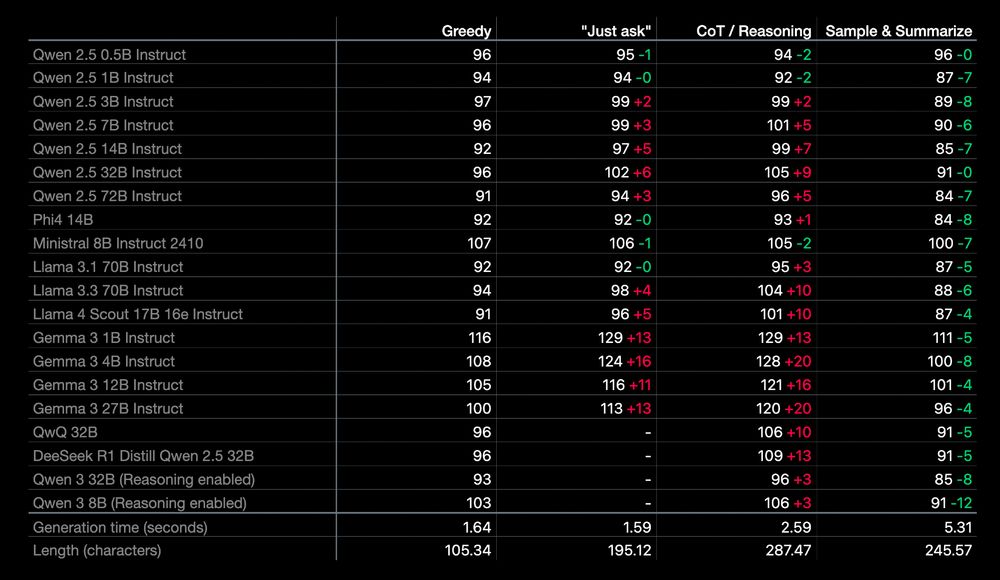
RQ2: Can LLMs produce such strings that describe their own distributions? We test the most recent LLMs of various sizes, with and without reasoning, with different prompts and CoT. None of them is able to honestly reveal the LLM’s internal distribution. 🧵7/9
July 3, 2025 at 9:08 AM
RQ2: Can LLMs produce such strings that describe their own distributions? We test the most recent LLMs of various sizes, with and without reasoning, with different prompts and CoT. None of them is able to honestly reveal the LLM’s internal distribution. 🧵7/9
We put SelfReflect to the test (plus a whole landscape of other metrics we’ve explored). Our final metric is able to distinguish even almost-good from good summaries and pick up implicit distributional statements. We find it aligns with human judgements. So let’s use it: 🧵6/9

July 3, 2025 at 9:08 AM
We put SelfReflect to the test (plus a whole landscape of other metrics we’ve explored). Our final metric is able to distinguish even almost-good from good summaries and pick up implicit distributional statements. We find it aligns with human judgements. So let’s use it: 🧵6/9
RQ 1: How can we measure if a string does that? The idea of our SelfReflect metric is that the summary string should imply the same follow-up responses as the original distribution; theoretically speaking it should be a predictively sufficient statistic of the distribution. 🧵5/9

July 3, 2025 at 9:08 AM
RQ 1: How can we measure if a string does that? The idea of our SelfReflect metric is that the summary string should imply the same follow-up responses as the original distribution; theoretically speaking it should be a predictively sufficient statistic of the distribution. 🧵5/9
So we want a string that summarizes the LLM’s internal distribution. Both what options it deems possible, but also how likely each is. In other words, we want the string to contain the same information as the LLM’s internal distribution over strings. 🧵4/9

July 3, 2025 at 9:08 AM
So we want a string that summarizes the LLM’s internal distribution. Both what options it deems possible, but also how likely each is. In other words, we want the string to contain the same information as the LLM’s internal distribution over strings. 🧵4/9
LLMs output strings, and strings are incredibly expressive. In fact, they are so expressive that a single string can describe _a whole distribution over_ strings. Such a string would give a perfect insight into what the LLM is certain and uncertain about. 🧵3/9

July 3, 2025 at 9:08 AM
LLMs output strings, and strings are incredibly expressive. In fact, they are so expressive that a single string can describe _a whole distribution over_ strings. Such a string would give a perfect insight into what the LLM is certain and uncertain about. 🧵3/9
Quick Recap: When you think of LLM uncertainties, you probably think of taking an LLM output and adding a correctness percentage, or a statement like “I’m not sure, but...”. But is this really all we can do? We argue we should aim to solve this problem by making it harder. 🧵2/9

July 3, 2025 at 9:08 AM
Quick Recap: When you think of LLM uncertainties, you probably think of taking an LLM output and adding a correctness percentage, or a statement like “I’m not sure, but...”. But is this really all we can do? We argue we should aim to solve this problem by making it harder. 🧵2/9
Can LLMs access and describe their own internal distributions? With my colleagues at Apple, I invite you to take a leap forward and make LLM uncertainty quantification what it can be.
📄 arxiv.org/abs/2505.20295
💻 github.com/apple/ml-sel...
🧵1/9
📄 arxiv.org/abs/2505.20295
💻 github.com/apple/ml-sel...
🧵1/9
July 3, 2025 at 9:08 AM
Can LLMs access and describe their own internal distributions? With my colleagues at Apple, I invite you to take a leap forward and make LLM uncertainty quantification what it can be.
📄 arxiv.org/abs/2505.20295
💻 github.com/apple/ml-sel...
🧵1/9
📄 arxiv.org/abs/2505.20295
💻 github.com/apple/ml-sel...
🧵1/9
I‘ll talk today about our latest research on uncertainty quantification at Apple (papers are 2 weeks old) and what I see as the future for UQ in vision and LLMs. See you at 102B, 4:30pm! PS: Lmk if you wanna chat :)

June 11, 2025 at 3:00 PM
I‘ll talk today about our latest research on uncertainty quantification at Apple (papers are 2 weeks old) and what I see as the future for UQ in vision and LLMs. See you at 102B, 4:30pm! PS: Lmk if you wanna chat :)
At the end of my PhD, I reflected on uncertainty quantification research, and what might change with chatbots and LLM agents. This was now accepted as position paper at @icmlconf.bsky.social. Some of those future topics are already picking up pace, so have an evening read ☕ arxiv.org/abs/2505.22655

May 29, 2025 at 7:30 AM
At the end of my PhD, I reflected on uncertainty quantification research, and what might change with chatbots and LLM agents. This was now accepted as position paper at @icmlconf.bsky.social. Some of those future topics are already picking up pace, so have an evening read ☕ arxiv.org/abs/2505.22655
Aleatoric and epistemic uncertainty are clear-cut concepts, right? ... right? 😵💫 In our new ICLR blogpost we let different schools of thought speak and contradict each other, and revisit chatbots where “the character of aleatory ‘transforms’ into epistemic” iclr-blogposts.github.io/2025/blog/re...

May 8, 2025 at 8:18 AM
Aleatoric and epistemic uncertainty are clear-cut concepts, right? ... right? 😵💫 In our new ICLR blogpost we let different schools of thought speak and contradict each other, and revisit chatbots where “the character of aleatory ‘transforms’ into epistemic” iclr-blogposts.github.io/2025/blog/re...
Wow, OpenAI's o1 has a whopping 93% ECE on Humanity's Last Exam. So if you just prompt o1 to tell you how sure it is about its answer, it will basically produce gibberish. And that's how most users will ask for uncertainties. We have work to do!

January 24, 2025 at 9:41 AM
Wow, OpenAI's o1 has a whopping 93% ECE on Humanity's Last Exam. So if you just prompt o1 to tell you how sure it is about its answer, it will basically produce gibberish. And that's how most users will ask for uncertainties. We have work to do!
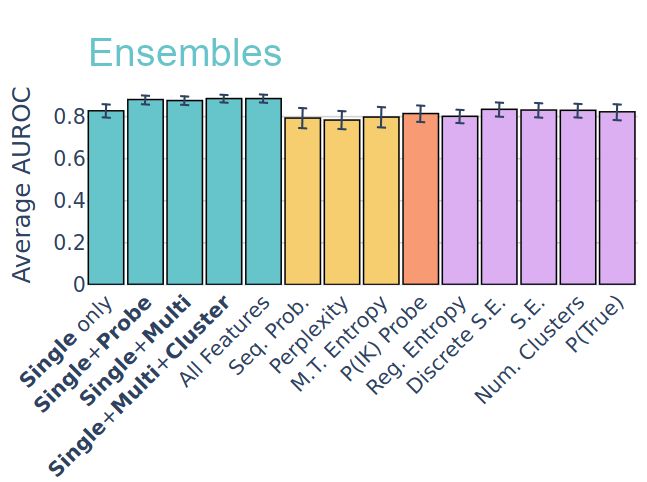
So we put this hypothesis to a test and combined multiple uncertainty estimators. Turns out that ensembles of different estimators consistently outperform the individual ones! That backs the hypothesis, and allows to build cheap yet strong uncertainty estimation ensembles. 🧵4/5

December 13, 2024 at 12:37 PM
So we put this hypothesis to a test and combined multiple uncertainty estimators. Turns out that ensembles of different estimators consistently outperform the individual ones! That backs the hypothesis, and allows to build cheap yet strong uncertainty estimation ensembles. 🧵4/5
But although they perform similarly overall, they differ in many examples. Their rank correlation is surprisingly low. This is an observational evidence that they are capturing uncertainty via different cues... 🧵3/5

December 13, 2024 at 12:37 PM
But although they perform similarly overall, they differ in many examples. Their rank correlation is surprisingly low. This is an observational evidence that they are capturing uncertainty via different cues... 🧵3/5
First, we've checked whether uncertainty estimators that sample multiple answers, like semantic entropy, perform better than single sample methods like token log likelihood. We find that the performance is surprisingly similar on most datasets. 🧵2/5

December 13, 2024 at 12:37 PM
First, we've checked whether uncertainty estimators that sample multiple answers, like semantic entropy, perform better than single sample methods like token log likelihood. We find that the performance is surprisingly similar on most datasets. 🧵2/5
Many LLM uncertainty estimators perform similarly, but does that mean they do the same? No! We find that they use different cues, and combining them gives even better performance. 🧵1/5
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
December 13, 2024 at 12:37 PM
Many LLM uncertainty estimators perform similarly, but does that mean they do the same? No! We find that they use different cues, and combining them gives even better performance. 🧵1/5
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
We observe this confounder not only for Rougle-L, but also for SQuAD and BERTScore. And across all 7 LLMs we test. The takeaway? Don't use Rouge-L, use an LLM as a grader. Side finding: LLM uncertainty estimators perform closer to one another than we previously thought. 🧵3/4

December 12, 2024 at 11:36 AM
We observe this confounder not only for Rougle-L, but also for SQuAD and BERTScore. And across all 7 LLMs we test. The takeaway? Don't use Rouge-L, use an LLM as a grader. Side finding: LLM uncertainty estimators perform closer to one another than we previously thought. 🧵3/4