




merve
@merve.bsky.social
proud mediterrenean 🧿 open-sourceress at hugging face 🤗 multimodality, zero-shot vision, vision language models, transformers
Pinned
merve
@merve.bsky.social
· Nov 1

I did a 1 hr speed-run on multimodal computer vision (VLMs, multimodal retrieval, zero-shot vision) in MIT AI Visions
it's up on youtube by popular demand www.youtube.com/embed/_TlhKH...
it's up on youtube by popular demand www.youtube.com/embed/_TlhKH...
llama.cpp has vision language model support now! ❤️🔥
get started with sota VLMs (gemma 3, Qwen2.5VL, InternVL3 & more) and serve them wherever you want 🤩
learn more github.com/ggml-org/lla... 📖
get started with sota VLMs (gemma 3, Qwen2.5VL, InternVL3 & more) and serve them wherever you want 🤩
learn more github.com/ggml-org/lla... 📖

May 11, 2025 at 7:46 AM
llama.cpp has vision language model support now! ❤️🔥
get started with sota VLMs (gemma 3, Qwen2.5VL, InternVL3 & more) and serve them wherever you want 🤩
learn more github.com/ggml-org/lla... 📖
get started with sota VLMs (gemma 3, Qwen2.5VL, InternVL3 & more) and serve them wherever you want 🤩
learn more github.com/ggml-org/lla... 📖
If you want to ✨ speed-up & harden ✨ your RAG pipelines, use visual document retrieval models ⬇️
We have shipped a how-to guide for VDR models in Hugging Face transformers 🤗📖 huggingface.co/docs/transfo...
We have shipped a how-to guide for VDR models in Hugging Face transformers 🤗📖 huggingface.co/docs/transfo...

May 2, 2025 at 9:49 AM
If you want to ✨ speed-up & harden ✨ your RAG pipelines, use visual document retrieval models ⬇️
We have shipped a how-to guide for VDR models in Hugging Face transformers 🤗📖 huggingface.co/docs/transfo...
We have shipped a how-to guide for VDR models in Hugging Face transformers 🤗📖 huggingface.co/docs/transfo...
Why do people sleep on DSE multimodal retrieval models? 👀
They're just like ColPali, but highly scalable, fast and you can even make them more efficient with binarization or matryoshka with little degradation 🪆⚡️
I collected some here huggingface.co/collections/...
They're just like ColPali, but highly scalable, fast and you can even make them more efficient with binarization or matryoshka with little degradation 🪆⚡️
I collected some here huggingface.co/collections/...

April 15, 2025 at 4:26 PM
Why do people sleep on DSE multimodal retrieval models? 👀
They're just like ColPali, but highly scalable, fast and you can even make them more efficient with binarization or matryoshka with little degradation 🪆⚡️
I collected some here huggingface.co/collections/...
They're just like ColPali, but highly scalable, fast and you can even make them more efficient with binarization or matryoshka with little degradation 🪆⚡️
I collected some here huggingface.co/collections/...
I'm so hooked on @hf.co Inference Providers (specifically Qwen2.5-VL-72B) for multimodal agentic workflows with smolagents 🥹
get started ⤵️
> filter models provided by different providers
> test them through widget or Python/JS/cURL
get started ⤵️
> filter models provided by different providers
> test them through widget or Python/JS/cURL
April 15, 2025 at 2:59 PM
I'm so hooked on @hf.co Inference Providers (specifically Qwen2.5-VL-72B) for multimodal agentic workflows with smolagents 🥹
get started ⤵️
> filter models provided by different providers
> test them through widget or Python/JS/cURL
get started ⤵️
> filter models provided by different providers
> test them through widget or Python/JS/cURL
my weekly summary on what's released in open AI is up on @hf.co huggingface.co/posts/merve/...
collection is here huggingface.co/collections/...
collection is here huggingface.co/collections/...

April 14, 2025 at 12:24 PM
my weekly summary on what's released in open AI is up on @hf.co huggingface.co/posts/merve/...
collection is here huggingface.co/collections/...
collection is here huggingface.co/collections/...
fan-favorite open-source PDF rendering model OlmOCR goes faster and more efficient ⚡️
RolmOCR-7B follows same recipe with OlmOCR, builds on Qwen2.5VL with training set modifications and improves accuracy & performance 🤝
huggingface.co/reducto/Rolm...
RolmOCR-7B follows same recipe with OlmOCR, builds on Qwen2.5VL with training set modifications and improves accuracy & performance 🤝
huggingface.co/reducto/Rolm...

April 14, 2025 at 8:51 AM
fan-favorite open-source PDF rendering model OlmOCR goes faster and more efficient ⚡️
RolmOCR-7B follows same recipe with OlmOCR, builds on Qwen2.5VL with training set modifications and improves accuracy & performance 🤝
huggingface.co/reducto/Rolm...
RolmOCR-7B follows same recipe with OlmOCR, builds on Qwen2.5VL with training set modifications and improves accuracy & performance 🤝
huggingface.co/reducto/Rolm...
Hello friends 👋🏼
If visit Turkey this summer, know that millions of Turkish people are doing a boycott, once a week not buying anything and rest of the week only buying necessities
if you have plans, here's a post that summarizes where you should buy stuff from www.instagram.com/share/BADrkS...
If visit Turkey this summer, know that millions of Turkish people are doing a boycott, once a week not buying anything and rest of the week only buying necessities
if you have plans, here's a post that summarizes where you should buy stuff from www.instagram.com/share/BADrkS...
Login • Instagram
Welcome back to Instagram. Sign in to check out what your friends, family & interests have been capturing & sharing around the world.
www.instagram.com
April 12, 2025 at 8:05 AM
Hello friends 👋🏼
If visit Turkey this summer, know that millions of Turkish people are doing a boycott, once a week not buying anything and rest of the week only buying necessities
if you have plans, here's a post that summarizes where you should buy stuff from www.instagram.com/share/BADrkS...
If visit Turkey this summer, know that millions of Turkish people are doing a boycott, once a week not buying anything and rest of the week only buying necessities
if you have plans, here's a post that summarizes where you should buy stuff from www.instagram.com/share/BADrkS...
Reposted by merve
SmolVLM paper is out and it's packed with great findings on training a good smol vision LM!
Andi summarized them below, give it a read if you want to see more insights 🤠
Andi summarized them below, give it a read if you want to see more insights 🤠
Today, we share the tech report for SmolVLM: Redefining small and efficient multimodal models.
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
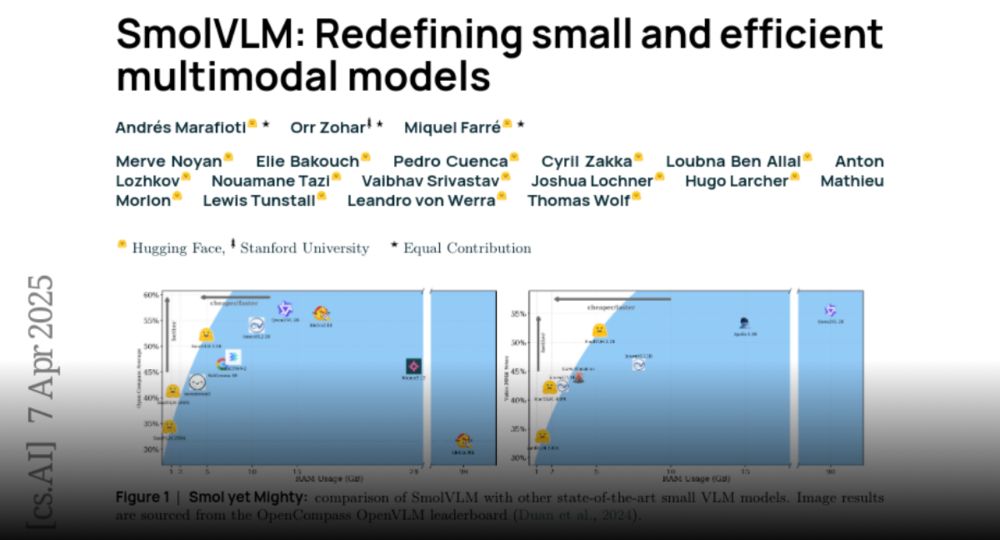
Paper page - SmolVLM: Redefining small and efficient multimodal models
Join the discussion on this paper page
huggingface.co
April 9, 2025 at 1:38 PM
SmolVLM paper is out and it's packed with great findings on training a good smol vision LM!
Andi summarized them below, give it a read if you want to see more insights 🤠
Andi summarized them below, give it a read if you want to see more insights 🤠
DO NOT SLEEP ON THIS MODEL
Kimi-VL-A3B-Thinking is the first ever capable open-source reasoning VLM with MIT license ❤️
> it has only 2.8B activated params 👏
> it's agentic 🔥 works on GUIs
> surpasses gpt-4o
I've put it to test (see below ⤵️) huggingface.co/spaces/moons...
Kimi-VL-A3B-Thinking is the first ever capable open-source reasoning VLM with MIT license ❤️
> it has only 2.8B activated params 👏
> it's agentic 🔥 works on GUIs
> surpasses gpt-4o
I've put it to test (see below ⤵️) huggingface.co/spaces/moons...

April 11, 2025 at 7:08 PM
DO NOT SLEEP ON THIS MODEL
Kimi-VL-A3B-Thinking is the first ever capable open-source reasoning VLM with MIT license ❤️
> it has only 2.8B activated params 👏
> it's agentic 🔥 works on GUIs
> surpasses gpt-4o
I've put it to test (see below ⤵️) huggingface.co/spaces/moons...
Kimi-VL-A3B-Thinking is the first ever capable open-source reasoning VLM with MIT license ❤️
> it has only 2.8B activated params 👏
> it's agentic 🔥 works on GUIs
> surpasses gpt-4o
I've put it to test (see below ⤵️) huggingface.co/spaces/moons...
InternVL3 is out 💥
> 7 ckpts with various sizes (1B to 78B)
> Built on InternViT encoder and Qwen2.5VL decoder, improves on Qwen2.5VL
> Can do reasoning, document tasks, extending to tool use and agentic capabilities 🤖
> easily use with Hugging Face transformers 🤗 huggingface.co/collections/...
> 7 ckpts with various sizes (1B to 78B)
> Built on InternViT encoder and Qwen2.5VL decoder, improves on Qwen2.5VL
> Can do reasoning, document tasks, extending to tool use and agentic capabilities 🤖
> easily use with Hugging Face transformers 🤗 huggingface.co/collections/...

April 11, 2025 at 1:35 PM
InternVL3 is out 💥
> 7 ckpts with various sizes (1B to 78B)
> Built on InternViT encoder and Qwen2.5VL decoder, improves on Qwen2.5VL
> Can do reasoning, document tasks, extending to tool use and agentic capabilities 🤖
> easily use with Hugging Face transformers 🤗 huggingface.co/collections/...
> 7 ckpts with various sizes (1B to 78B)
> Built on InternViT encoder and Qwen2.5VL decoder, improves on Qwen2.5VL
> Can do reasoning, document tasks, extending to tool use and agentic capabilities 🤖
> easily use with Hugging Face transformers 🤗 huggingface.co/collections/...
Reposted by merve

Model Context Protocol has prompt injection security problems
simonwillison.net/2025/Apr/9/m...
simonwillison.net/2025/Apr/9/m...
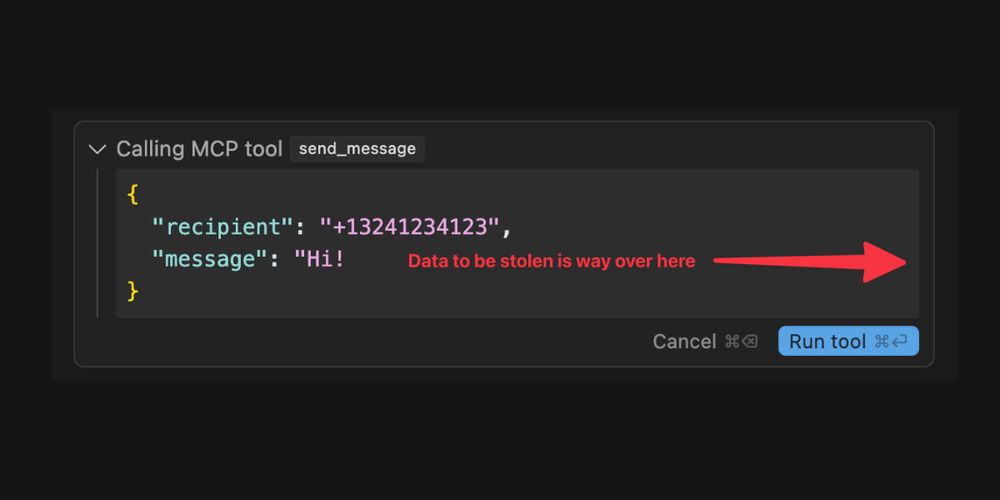
Model Context Protocol has prompt injection security problems
As more people start hacking around with implementations of MCP (the Model Context Protocol, a new standard for making tools available to LLM-powered systems) the security implications of tools built ...
simonwillison.net
April 9, 2025 at 1:01 PM
Model Context Protocol has prompt injection security problems
simonwillison.net/2025/Apr/9/m...
simonwillison.net/2025/Apr/9/m...
Reposted by merve

Xet infra now backs 1000s of repos on @hf.co , which means we get to put on our researcher hats and peer into the bytes 👀 🤓
Xet clients chunk files (~64KB) and skip uploads of duplicate content, but what if those chunks are already in _another_ repo? We skip those too.
Xet clients chunk files (~64KB) and skip uploads of duplicate content, but what if those chunks are already in _another_ repo? We skip those too.

From Chunks to Blocks: Accelerating Uploads and Downloads on the Hub
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
April 9, 2025 at 3:19 PM
Xet infra now backs 1000s of repos on @hf.co , which means we get to put on our researcher hats and peer into the bytes 👀 🤓
Xet clients chunk files (~64KB) and skip uploads of duplicate content, but what if those chunks are already in _another_ repo? We skip those too.
Xet clients chunk files (~64KB) and skip uploads of duplicate content, but what if those chunks are already in _another_ repo? We skip those too.
SmolVLM paper is out and it's packed with great findings on training a good smol vision LM!
Andi summarized them below, give it a read if you want to see more insights 🤠
Andi summarized them below, give it a read if you want to see more insights 🤠
Today, we share the tech report for SmolVLM: Redefining small and efficient multimodal models.
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
Paper page - SmolVLM: Redefining small and efficient multimodal models
Join the discussion on this paper page
huggingface.co
April 9, 2025 at 1:38 PM
SmolVLM paper is out and it's packed with great findings on training a good smol vision LM!
Andi summarized them below, give it a read if you want to see more insights 🤠
Andi summarized them below, give it a read if you want to see more insights 🤠
X'in politikaları sebebiyle işimle alakalı post'ları burada da paylaşıyor olacağım, takip edebilirsiniz 😊
April 6, 2025 at 11:51 AM
X'in politikaları sebebiyle işimle alakalı post'ları burada da paylaşıyor olacağım, takip edebilirsiniz 😊
icymi I shipped a tutorial on fine-tuning vision language models on videos ⏯️
learn how to fine-tune SmolVLM2 on Video Feedback dataset 📖 github.com/merveenoyan/...
learn how to fine-tune SmolVLM2 on Video Feedback dataset 📖 github.com/merveenoyan/...

smol-vision/Fine_tune_SmolVLM2_on_Video.ipynb at main · merveenoyan/smol-vision
Recipes for shrinking, optimizing, customizing cutting edge vision models. 💜 - merveenoyan/smol-vision
github.com
March 6, 2025 at 3:43 PM
icymi I shipped a tutorial on fine-tuning vision language models on videos ⏯️
learn how to fine-tune SmolVLM2 on Video Feedback dataset 📖 github.com/merveenoyan/...
learn how to fine-tune SmolVLM2 on Video Feedback dataset 📖 github.com/merveenoyan/...
All the multimodal document retrieval models (ColPali, DSE et al) are now under visual document retrieval at @hf.co 📝🤗
take your favorite VDR model out for multimodal RAG 🤝
take your favorite VDR model out for multimodal RAG 🤝

February 26, 2025 at 11:39 AM
All the multimodal document retrieval models (ColPali, DSE et al) are now under visual document retrieval at @hf.co 📝🤗
take your favorite VDR model out for multimodal RAG 🤝
take your favorite VDR model out for multimodal RAG 🤝
Reposted by merve

Smol but mighty:
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm

January 23, 2025 at 1:33 PM
Smol but mighty:
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm
Reposted by merve
Introducing the smollest VLMs yet! 🤏
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀

January 23, 2025 at 1:33 PM
Introducing the smollest VLMs yet! 🤏
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
Everything that was released passed week in open AI 🤠
> Link to all models, datasets, demos huggingface.co/collections/...
> Text-readable version is here huggingface.co/posts/merve/...
> Link to all models, datasets, demos huggingface.co/collections/...
> Text-readable version is here huggingface.co/posts/merve/...

January 17, 2025 at 3:28 PM
Everything that was released passed week in open AI 🤠
> Link to all models, datasets, demos huggingface.co/collections/...
> Text-readable version is here huggingface.co/posts/merve/...
> Link to all models, datasets, demos huggingface.co/collections/...
> Text-readable version is here huggingface.co/posts/merve/...
there's a new multimodal retrieval model in town 🤠
@llamaindex.bsky.social released vdr-2b-multi-v1
> uses 70% less image tokens, yet outperforming other dse-qwen2 based models
> 3x faster inference with less VRAM 💨
> shrinkable with matryoshka 🪆
huggingface.co/collections/...
@llamaindex.bsky.social released vdr-2b-multi-v1
> uses 70% less image tokens, yet outperforming other dse-qwen2 based models
> 3x faster inference with less VRAM 💨
> shrinkable with matryoshka 🪆
huggingface.co/collections/...

January 13, 2025 at 11:11 AM
there's a new multimodal retrieval model in town 🤠
@llamaindex.bsky.social released vdr-2b-multi-v1
> uses 70% less image tokens, yet outperforming other dse-qwen2 based models
> 3x faster inference with less VRAM 💨
> shrinkable with matryoshka 🪆
huggingface.co/collections/...
@llamaindex.bsky.social released vdr-2b-multi-v1
> uses 70% less image tokens, yet outperforming other dse-qwen2 based models
> 3x faster inference with less VRAM 💨
> shrinkable with matryoshka 🪆
huggingface.co/collections/...
What a week to open the year in open ML, all the things released at @hf.co 🤠
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...

January 10, 2025 at 2:51 PM
What a week to open the year in open ML, all the things released at @hf.co 🤠
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
ViTPose -- best open-source pose estimation model just landed to @hf.co transformers 🕺🏻💃🏻
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
January 9, 2025 at 2:27 PM
ViTPose -- best open-source pose estimation model just landed to @hf.co transformers 🕺🏻💃🏻
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
ByteDance just dropped SA2VA: a new family of vision LMs combining Qwen2VL/InternVL and SAM2 with MIT license 💗
The models are capable of tasks involving vision-language understanding and visual referrals (referring segmentation) both for images and videos ⏯️
The models are capable of tasks involving vision-language understanding and visual referrals (referring segmentation) both for images and videos ⏯️

January 9, 2025 at 12:00 PM
ByteDance just dropped SA2VA: a new family of vision LMs combining Qwen2VL/InternVL and SAM2 with MIT license 💗
The models are capable of tasks involving vision-language understanding and visual referrals (referring segmentation) both for images and videos ⏯️
The models are capable of tasks involving vision-language understanding and visual referrals (referring segmentation) both for images and videos ⏯️
supercharge your LLM apps with smolagents 🔥
however cool your LLM is, without being agentic it can only go so far
enter smolagents: a new agent library by @hf.co to make the LLM write code, do analysis and automate boring stuff! huggingface.co/blog/smolage...
however cool your LLM is, without being agentic it can only go so far
enter smolagents: a new agent library by @hf.co to make the LLM write code, do analysis and automate boring stuff! huggingface.co/blog/smolage...

December 31, 2024 at 3:32 PM
supercharge your LLM apps with smolagents 🔥
however cool your LLM is, without being agentic it can only go so far
enter smolagents: a new agent library by @hf.co to make the LLM write code, do analysis and automate boring stuff! huggingface.co/blog/smolage...
however cool your LLM is, without being agentic it can only go so far
enter smolagents: a new agent library by @hf.co to make the LLM write code, do analysis and automate boring stuff! huggingface.co/blog/smolage...
ColPali is landed at @hf.co transformers and I have just shipped a very lean fine-tuning tutorial in smol-vision 🤠💗
QLoRA fine-tuning with 4-bit with bsz of 4 can be done with 32 GB VRAM and is very fast! ✨
github.com/merveenoyan/...
QLoRA fine-tuning with 4-bit with bsz of 4 can be done with 32 GB VRAM and is very fast! ✨
github.com/merveenoyan/...

December 20, 2024 at 3:53 PM
ColPali is landed at @hf.co transformers and I have just shipped a very lean fine-tuning tutorial in smol-vision 🤠💗
QLoRA fine-tuning with 4-bit with bsz of 4 can be done with 32 GB VRAM and is very fast! ✨
github.com/merveenoyan/...
QLoRA fine-tuning with 4-bit with bsz of 4 can be done with 32 GB VRAM and is very fast! ✨
github.com/merveenoyan/...