




Meg T (she/her/hers)
@megthescientist.bsky.social
Bio x ML @ Romero lab, @dukeubme.bsky.social
@ml4proteins.bsky.social co-organizer
@ml4proteins.bsky.social co-organizer
Excited to be at the Carolina Biophysics Symposium the next two days to hear and talk about protein eng and design in many therapeutic and green science spaces!! Special thanks to our friends at
@unc-bcbp.bsky.social for organizing! Gonna be an exciting time!
cbs.web.unc.edu
@unc-bcbp.bsky.social for organizing! Gonna be an exciting time!
cbs.web.unc.edu

November 6, 2025 at 12:45 PM
Excited to be at the Carolina Biophysics Symposium the next two days to hear and talk about protein eng and design in many therapeutic and green science spaces!! Special thanks to our friends at
@unc-bcbp.bsky.social for organizing! Gonna be an exciting time!
cbs.web.unc.edu
@unc-bcbp.bsky.social for organizing! Gonna be an exciting time!
cbs.web.unc.edu
Something happy, amongst all that is happening in the world today:
Our first valentines 2 years ago, went to breakfast then on a tour of an HTC cluster!! It was this biochemist’s first time seeing a server room😅 then legos. Hate being in grad school at 2 different places now, but still love you!
Our first valentines 2 years ago, went to breakfast then on a tour of an HTC cluster!! It was this biochemist’s first time seeing a server room😅 then legos. Hate being in grad school at 2 different places now, but still love you!




February 14, 2025 at 11:11 AM
Something happy, amongst all that is happening in the world today:
Our first valentines 2 years ago, went to breakfast then on a tour of an HTC cluster!! It was this biochemist’s first time seeing a server room😅 then legos. Hate being in grad school at 2 different places now, but still love you!
Our first valentines 2 years ago, went to breakfast then on a tour of an HTC cluster!! It was this biochemist’s first time seeing a server room😅 then legos. Hate being in grad school at 2 different places now, but still love you!
Duke (student), UW-Madison (affiliate, not paid), NSF💀

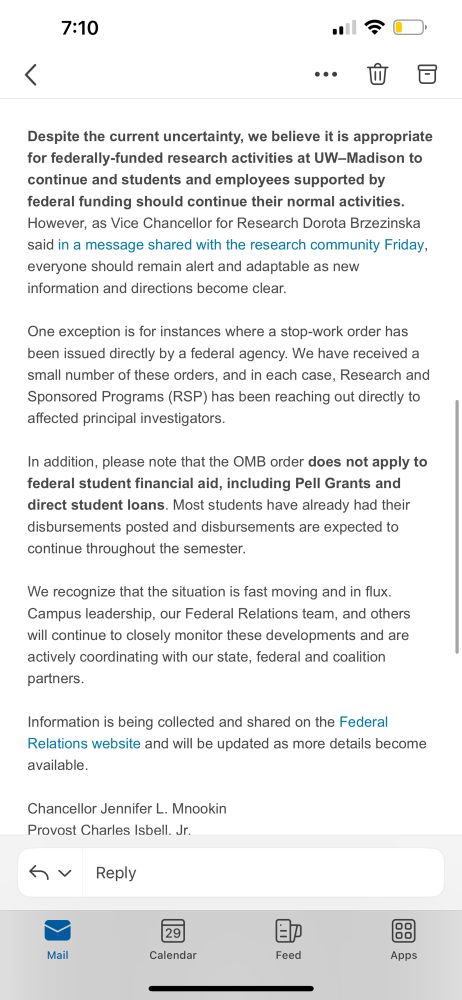

January 29, 2025 at 12:11 PM
Duke (student), UW-Madison (affiliate, not paid), NSF💀
Interesting.

January 29, 2025 at 12:32 AM
Interesting.
And finally— some very interesting future directions:

December 16, 2024 at 6:55 AM
And finally— some very interesting future directions:
•then trained off different linear regression models with embeddings of language model vs manually curated features; surprisingly did better on manual curation of features


December 16, 2024 at 6:55 AM
•then trained off different linear regression models with embeddings of language model vs manually curated features; surprisingly did better on manual curation of features
•Introduced “global stability” vs “coopertivity”, where partially open states (varying opening energies) are “less” cooperative
•supported w/ natural domains sharing similar global stability but diff conformational dynamics; to be more open & “less cooperative”, likely indicates hydrophobic chains
•supported w/ natural domains sharing similar global stability but diff conformational dynamics; to be more open & “less cooperative”, likely indicates hydrophobic chains


December 16, 2024 at 6:55 AM
•Introduced “global stability” vs “coopertivity”, where partially open states (varying opening energies) are “less” cooperative
•supported w/ natural domains sharing similar global stability but diff conformational dynamics; to be more open & “less cooperative”, likely indicates hydrophobic chains
•supported w/ natural domains sharing similar global stability but diff conformational dynamics; to be more open & “less cooperative”, likely indicates hydrophobic chains
•these “fluctuations” betw “hidden” conformations are not always captured in experiments
•coupling H/DX with mass spec, can capture ideas about stability and protein domains and their “opening energy” profile; tells you about partially unfolded status but not specifically where at in the protein
•coupling H/DX with mass spec, can capture ideas about stability and protein domains and their “opening energy” profile; tells you about partially unfolded status but not specifically where at in the protein

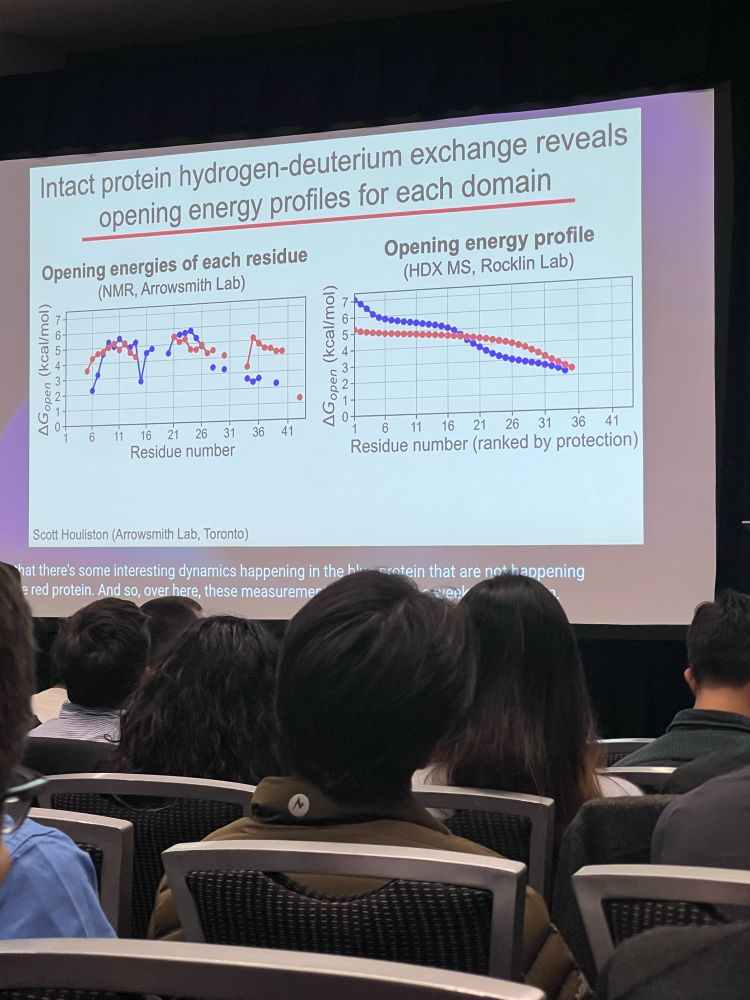
December 16, 2024 at 6:55 AM
•these “fluctuations” betw “hidden” conformations are not always captured in experiments
•coupling H/DX with mass spec, can capture ideas about stability and protein domains and their “opening energy” profile; tells you about partially unfolded status but not specifically where at in the protein
•coupling H/DX with mass spec, can capture ideas about stability and protein domains and their “opening energy” profile; tells you about partially unfolded status but not specifically where at in the protein
To wrap up part 1 (next part to be shared tomorrow) was @grocklin.bsky.social who asked “how do protein sequences determine folding energy landscapes”
•important to understand b/c partial folding/unfolding can have biological relevance to function
•important to understand b/c partial folding/unfolding can have biological relevance to function


December 16, 2024 at 6:55 AM
To wrap up part 1 (next part to be shared tomorrow) was @grocklin.bsky.social who asked “how do protein sequences determine folding energy landscapes”
•important to understand b/c partial folding/unfolding can have biological relevance to function
•important to understand b/c partial folding/unfolding can have biological relevance to function
•evo-tuning on low likelihood wild types improved performance
•evo-tuning on high likelihood wild types harmed performance
•thus model fitness is truly a matter of preference
•much more also to dive into with their paper
•evo-tuning on high likelihood wild types harmed performance
•thus model fitness is truly a matter of preference
•much more also to dive into with their paper


December 16, 2024 at 6:29 AM
•evo-tuning on low likelihood wild types improved performance
•evo-tuning on high likelihood wild types harmed performance
•thus model fitness is truly a matter of preference
•much more also to dive into with their paper
•evo-tuning on high likelihood wild types harmed performance
•thus model fitness is truly a matter of preference
•much more also to dive into with their paper
•found that pseudo log-likelihoods vs spearmen’s of a DMS supports that low likelihood of wild-type sequences will struggle to predict beneficial vs harmful mutations, both with MLM (ESM2) and autoregressive (ProGen2) ; want to avoid phylogenetic effects instead of getting actual fitness signals

December 16, 2024 at 6:29 AM
•found that pseudo log-likelihoods vs spearmen’s of a DMS supports that low likelihood of wild-type sequences will struggle to predict beneficial vs harmful mutations, both with MLM (ESM2) and autoregressive (ProGen2) ; want to avoid phylogenetic effects instead of getting actual fitness signals
•instead, preds of mutation effect relies on likelihoods on wildtype/ non-mutated protein (to help in cases of low-likelihood species to not bias towards over-represented homologs found across all life)
•also, token distributions are taught in training
•also, token distributions are taught in training


December 16, 2024 at 6:29 AM
•instead, preds of mutation effect relies on likelihoods on wildtype/ non-mutated protein (to help in cases of low-likelihood species to not bias towards over-represented homologs found across all life)
•also, token distributions are taught in training
•also, token distributions are taught in training
•introduced “zero shot prediction” as a question of guessing a bioassay’s outcome by likelihoods of pLMs
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)

December 16, 2024 at 6:29 AM
•introduced “zero shot prediction” as a question of guessing a bioassay’s outcome by likelihoods of pLMs
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)
Following up was a 2nd contributed talk of work of @amyxlu.bsky.social and Cade Gordon: pLM model fitness is a matter of preference

December 16, 2024 at 6:29 AM
Following up was a 2nd contributed talk of work of @amyxlu.bsky.social and Cade Gordon: pLM model fitness is a matter of preference
•function-conditioning of proteins showed relevant biological characteristics, such as:
•Non-sequence adjacent learning of active site side chains
•also saw good hydrophobicity trends w transmembranes
•lots more to unpack in both the PLAID and CHEAP papers
•Non-sequence adjacent learning of active site side chains
•also saw good hydrophobicity trends w transmembranes
•lots more to unpack in both the PLAID and CHEAP papers

December 16, 2024 at 5:57 AM
•function-conditioning of proteins showed relevant biological characteristics, such as:
•Non-sequence adjacent learning of active site side chains
•also saw good hydrophobicity trends w transmembranes
•lots more to unpack in both the PLAID and CHEAP papers
•Non-sequence adjacent learning of active site side chains
•also saw good hydrophobicity trends w transmembranes
•lots more to unpack in both the PLAID and CHEAP papers
•inference uses CHEAP decoder to get corresponding AAs to obtain both seq and struc at same time
•then compared diversity vs quality across protein length (64-512)
• compared to other models, PLAID showed less degradation in its performance w/ increased protein length
•then compared diversity vs quality across protein length (64-512)
• compared to other models, PLAID showed less degradation in its performance w/ increased protein length

December 16, 2024 at 5:57 AM
•inference uses CHEAP decoder to get corresponding AAs to obtain both seq and struc at same time
•then compared diversity vs quality across protein length (64-512)
• compared to other models, PLAID showed less degradation in its performance w/ increased protein length
•then compared diversity vs quality across protein length (64-512)
• compared to other models, PLAID showed less degradation in its performance w/ increased protein length
•…b/c the task of jointly sampling is biased by the amount of struc vs seq data available
•but, ESMFold latent space represents a joint embedding of sequence structure
•thus can train a latent diffusion objective on the joint embedding space, which is compressed by CHEAP encoder (shorturl.at/fshN4)
•but, ESMFold latent space represents a joint embedding of sequence structure
•thus can train a latent diffusion objective on the joint embedding space, which is compressed by CHEAP encoder (shorturl.at/fshN4)

December 16, 2024 at 5:57 AM
•…b/c the task of jointly sampling is biased by the amount of struc vs seq data available
•but, ESMFold latent space represents a joint embedding of sequence structure
•thus can train a latent diffusion objective on the joint embedding space, which is compressed by CHEAP encoder (shorturl.at/fshN4)
•but, ESMFold latent space represents a joint embedding of sequence structure
•thus can train a latent diffusion objective on the joint embedding space, which is compressed by CHEAP encoder (shorturl.at/fshN4)
•framed discussion on how generative modeling of protein struc is still limited
•structure-based methods are often backbone only
• Sequence-based methods are required to fill in side chains
•all atoms methods go between struc preds and inverse folding
•often not multimodal, don’t jointly sample…
•structure-based methods are often backbone only
• Sequence-based methods are required to fill in side chains
•all atoms methods go between struc preds and inverse folding
•often not multimodal, don’t jointly sample…


December 16, 2024 at 5:57 AM
•framed discussion on how generative modeling of protein struc is still limited
•structure-based methods are often backbone only
• Sequence-based methods are required to fill in side chains
•all atoms methods go between struc preds and inverse folding
•often not multimodal, don’t jointly sample…
•structure-based methods are often backbone only
• Sequence-based methods are required to fill in side chains
•all atoms methods go between struc preds and inverse folding
•often not multimodal, don’t jointly sample…
Next up we heard a contributed talk from @amyxlu.bsky.social on PLAID (Protein LAtent Induced Diffusion)

December 16, 2024 at 5:57 AM
Next up we heard a contributed talk from @amyxlu.bsky.social on PLAID (Protein LAtent Induced Diffusion)
•get involved by checking out proposals on zenodo

December 16, 2024 at 3:33 AM
•get involved by checking out proposals on zenodo
•3 reasons it works well to gather more biological data (highlighted in pictures)
•types of questions it is or could probe in the future
•types of questions it is or could probe in the future




December 16, 2024 at 3:33 AM
•3 reasons it works well to gather more biological data (highlighted in pictures)
•types of questions it is or could probe in the future
•types of questions it is or could probe in the future
•also motivated the “protein function landscape” and how current model training, fine tuning and inference helps within the same protein family/functions, but fails to extrapolate to functions close in space
•introduced GROQ-seq and utility of HT-experiments
•data quality across multiple locations
•introduced GROQ-seq and utility of HT-experiments
•data quality across multiple locations




December 16, 2024 at 3:33 AM
•also motivated the “protein function landscape” and how current model training, fine tuning and inference helps within the same protein family/functions, but fails to extrapolate to functions close in space
•introduced GROQ-seq and utility of HT-experiments
•data quality across multiple locations
•introduced GROQ-seq and utility of HT-experiments
•data quality across multiple locations
•defined what were the keys to success for AF2-3 innovation
•some in field ask what will be the “next AF moment in biology”
•pivoted that question and motivated towards thinking abt a new way to ask about biological data collection process to solve new problems in biology
•some in field ask what will be the “next AF moment in biology”
•pivoted that question and motivated towards thinking abt a new way to ask about biological data collection process to solve new problems in biology



December 16, 2024 at 3:33 AM
•defined what were the keys to success for AF2-3 innovation
•some in field ask what will be the “next AF moment in biology”
•pivoted that question and motivated towards thinking abt a new way to ask about biological data collection process to solve new problems in biology
•some in field ask what will be the “next AF moment in biology”
•pivoted that question and motivated towards thinking abt a new way to ask about biological data collection process to solve new problems in biology
•Switched gears to @erika-alden.bsky.social and Align to Innovate!!
•she also switched gears from mathematical sims in astrophysics to biology and later on proteins ;)
•mission: “interface of biology, automation, and machine learning to rapidly convert the life sciences to a data-first discipline”
•she also switched gears from mathematical sims in astrophysics to biology and later on proteins ;)
•mission: “interface of biology, automation, and machine learning to rapidly convert the life sciences to a data-first discipline”


December 16, 2024 at 3:33 AM
•Switched gears to @erika-alden.bsky.social and Align to Innovate!!
•she also switched gears from mathematical sims in astrophysics to biology and later on proteins ;)
•mission: “interface of biology, automation, and machine learning to rapidly convert the life sciences to a data-first discipline”
•she also switched gears from mathematical sims in astrophysics to biology and later on proteins ;)
•mission: “interface of biology, automation, and machine learning to rapidly convert the life sciences to a data-first discipline”
Paper in Nature, Github

December 16, 2024 at 3:06 AM
Paper in Nature, Github