




Medhini Narasimhan
@medhini.bsky.social
Researcher @Google Deepmind working on Veo.
UC Berkeley/BAIR PhD, UIUC MS/CS
medhini.github.io
UC Berkeley/BAIR PhD, UIUC MS/CS
medhini.github.io
Reposted by Medhini Narasimhan

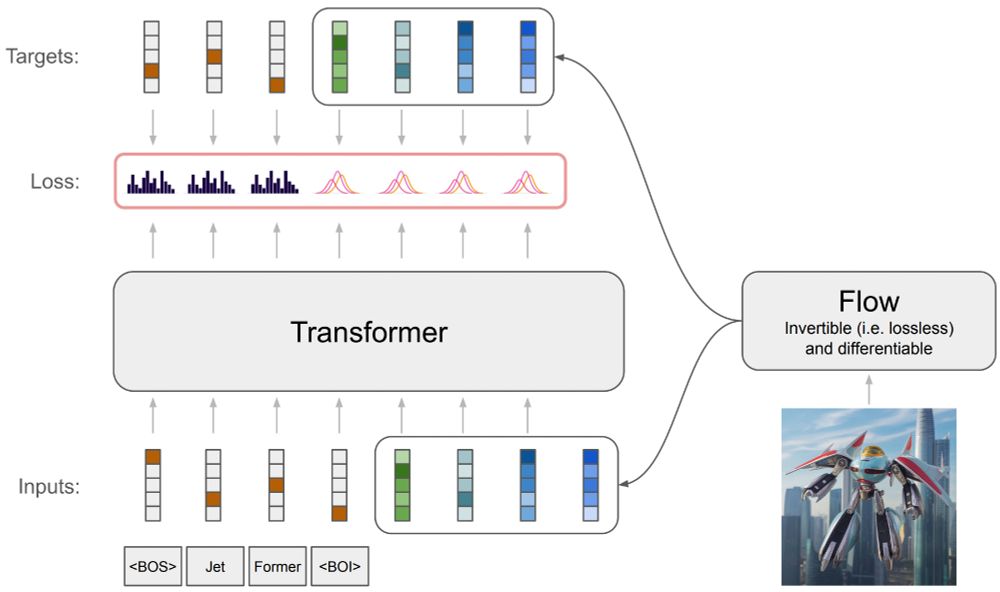
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
Reposted by Medhini Narasimhan

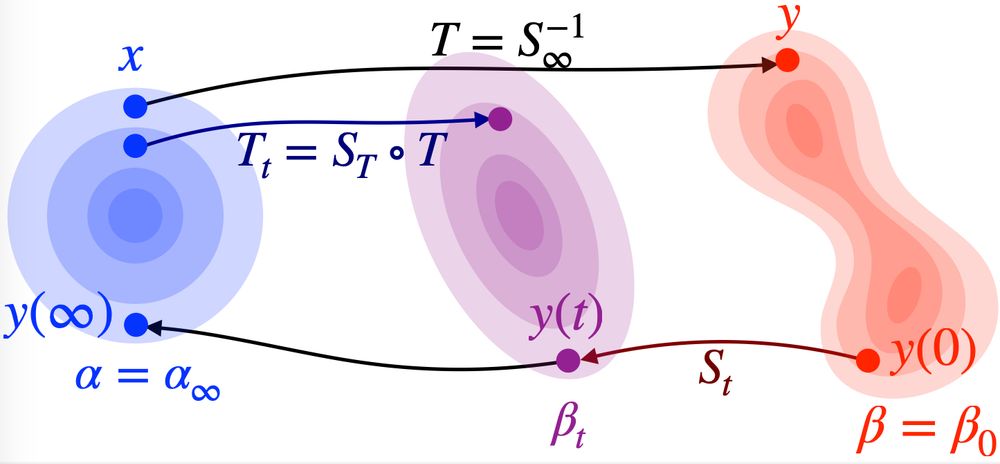
The link between diffusion models and optimal transport is still a bit of an enigma to me.
One thing that's clear: different diffusion models trained on similar datasets tend to recover similar mappings. If these are generally not OT, in what sense are they optimal instead?
One thing that's clear: different diffusion models trained on similar datasets tend to recover similar mappings. If these are generally not OT, in what sense are they optimal instead?

I wrote a summary of the main ingredients of the neat proof by Hugo Lavenant that diffusion models do not generally define optimal transport. github.com/mathematical...
November 30, 2024 at 12:56 PM
The link between diffusion models and optimal transport is still a bit of an enigma to me.
One thing that's clear: different diffusion models trained on similar datasets tend to recover similar mappings. If these are generally not OT, in what sense are they optimal instead?
One thing that's clear: different diffusion models trained on similar datasets tend to recover similar mappings. If these are generally not OT, in what sense are they optimal instead?