



Florian Huber
@me-datapoint.bsky.social
Professor for data science at HSD, @zdd-hsd.bsky.social
| ML fan & critic | current research mostly #datascience, #machinelearning, #cheminformatics #dataviz #nlp | ✨ #openscience #openaccess #rse | living data point 🚲
| ML fan & critic | current research mostly #datascience, #machinelearning, #cheminformatics #dataviz #nlp | ✨ #openscience #openaccess #rse | living data point 🚲
Special thanks to @julianpollmann.bsky.social and Niek de Jonge for code and code reviews!
GitHub: github.com/matchms/matc...
#opensource #RSE #researchsoftwareengineering
GitHub: github.com/matchms/matc...
#opensource #RSE #researchsoftwareengineering

GitHub - matchms/matchms: Python library for processing (tandem) mass spectrometry data and for computing spectral similarities.
Python library for processing (tandem) mass spectrometry data and for computing spectral similarities. - matchms/matchms
github.com
October 6, 2025 at 4:00 PM
Special thanks to @julianpollmann.bsky.social and Niek de Jonge for code and code reviews!
GitHub: github.com/matchms/matc...
#opensource #RSE #researchsoftwareengineering
GitHub: github.com/matchms/matc...
#opensource #RSE #researchsoftwareengineering
Great post!
We also noted the same thing, which triggered us to point out some pitfalls of various fingerprints --> www.biorxiv.org/content/10.1...
We also noted the same thing, which triggered us to point out some pitfalls of various fingerprints --> www.biorxiv.org/content/10.1...
www.biorxiv.org
July 17, 2025 at 11:40 AM
Great post!
We also noted the same thing, which triggered us to point out some pitfalls of various fingerprints --> www.biorxiv.org/content/10.1...
We also noted the same thing, which triggered us to point out some pitfalls of various fingerprints --> www.biorxiv.org/content/10.1...
4/4
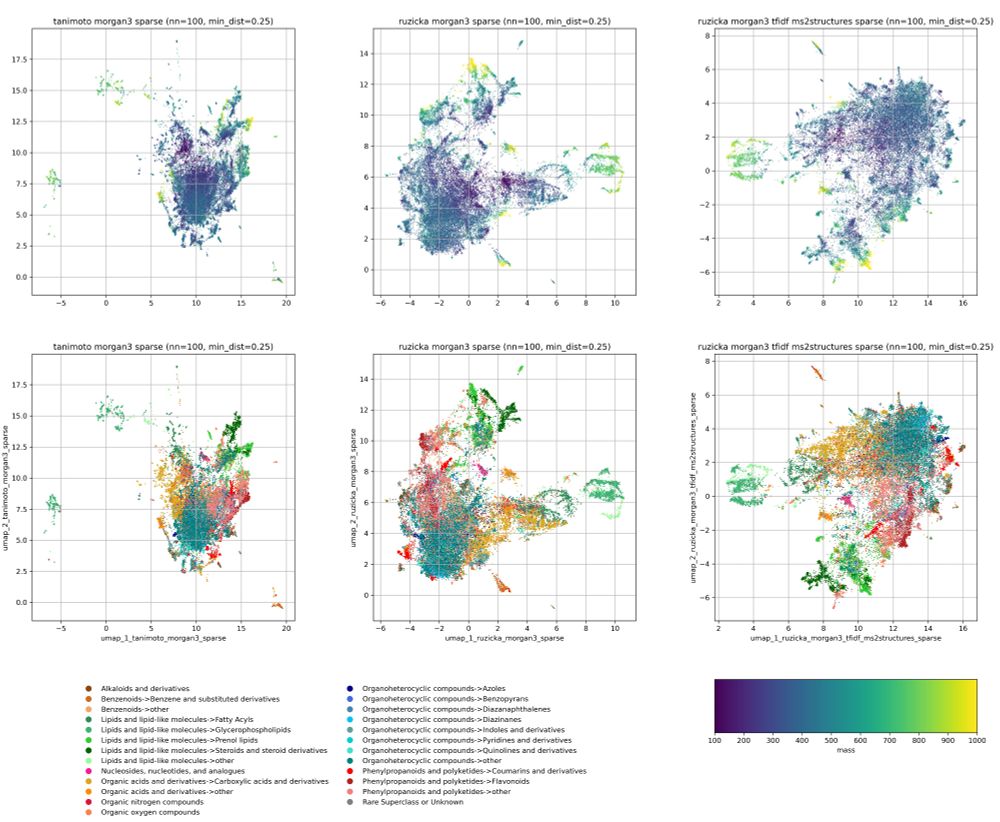
We also highlight options for count fingerprints, such as log-counts and IDF weighted counts. The latter can be used to adjust the bit importance to a dataset of your choice.
An example use-case are chemical space visualizations.
Preprint: www.biorxiv.org/content/10.1...
We also highlight options for count fingerprints, such as log-counts and IDF weighted counts. The latter can be used to adjust the bit importance to a dataset of your choice.
An example use-case are chemical space visualizations.
Preprint: www.biorxiv.org/content/10.1...
June 23, 2025 at 9:22 AM
4/4
We also highlight options for count fingerprints, such as log-counts and IDF weighted counts. The latter can be used to adjust the bit importance to a dataset of your choice.
An example use-case are chemical space visualizations.
Preprint: www.biorxiv.org/content/10.1...
We also highlight options for count fingerprints, such as log-counts and IDF weighted counts. The latter can be used to adjust the bit importance to a dataset of your choice.
An example use-case are chemical space visualizations.
Preprint: www.biorxiv.org/content/10.1...
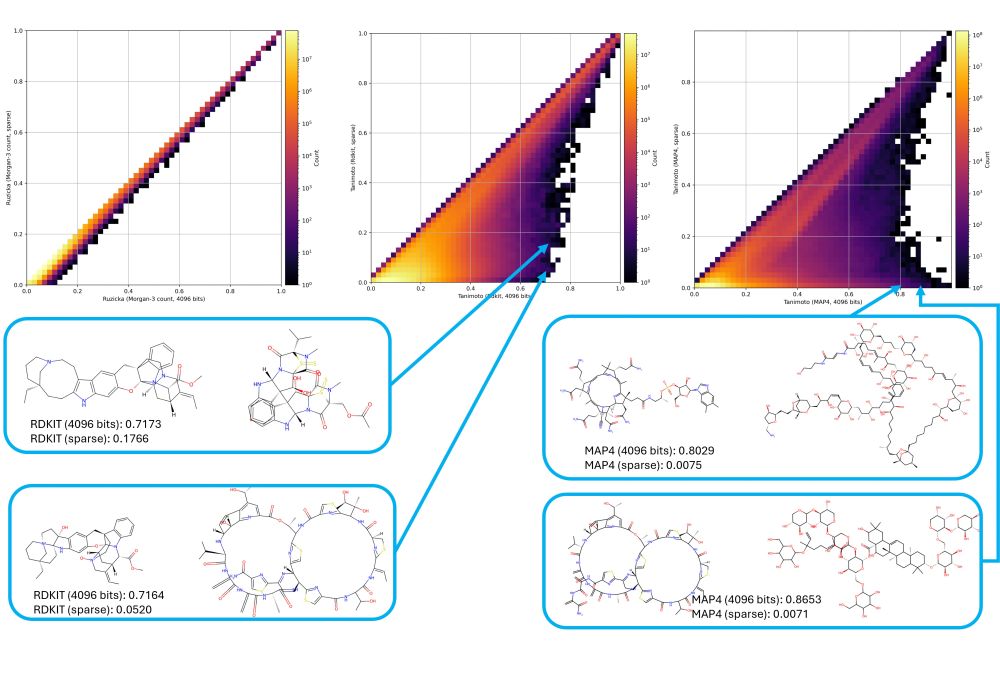
3/4
A huge issue is bit collisions.
Fingerprints with a high bit occupation (RDKit, MAP4) often lead to (1) arbitrary misinterpretations, (2) shifts to high Tanimoto scores, (3) very different handling of small and large molecules.
--> Consider using sparse fingerprints!
--> Morgan >> MAP4 / RDKit
A huge issue is bit collisions.
Fingerprints with a high bit occupation (RDKit, MAP4) often lead to (1) arbitrary misinterpretations, (2) shifts to high Tanimoto scores, (3) very different handling of small and large molecules.
--> Consider using sparse fingerprints!
--> Morgan >> MAP4 / RDKit
June 23, 2025 at 9:22 AM
3/4
A huge issue is bit collisions.
Fingerprints with a high bit occupation (RDKit, MAP4) often lead to (1) arbitrary misinterpretations, (2) shifts to high Tanimoto scores, (3) very different handling of small and large molecules.
--> Consider using sparse fingerprints!
--> Morgan >> MAP4 / RDKit
A huge issue is bit collisions.
Fingerprints with a high bit occupation (RDKit, MAP4) often lead to (1) arbitrary misinterpretations, (2) shifts to high Tanimoto scores, (3) very different handling of small and large molecules.
--> Consider using sparse fingerprints!
--> Morgan >> MAP4 / RDKit
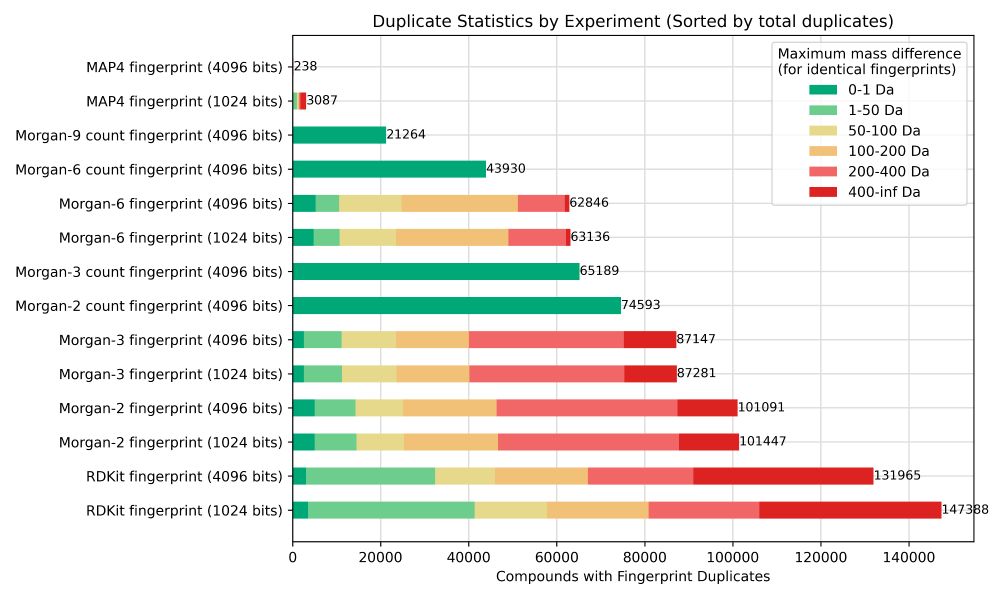
2/4
We focused on weaknesses of the fingerprints.
Many show frequent duplicates, so same fingerprint for different compounds. Most problematic: this can include *very* different compounds ending up with identical fingerprints.
- MAP4 >> Morgan-type >> daylight
- count >> binary
#cheminformatics
We focused on weaknesses of the fingerprints.
Many show frequent duplicates, so same fingerprint for different compounds. Most problematic: this can include *very* different compounds ending up with identical fingerprints.
- MAP4 >> Morgan-type >> daylight
- count >> binary
#cheminformatics
June 23, 2025 at 9:22 AM
2/4
We focused on weaknesses of the fingerprints.
Many show frequent duplicates, so same fingerprint for different compounds. Most problematic: this can include *very* different compounds ending up with identical fingerprints.
- MAP4 >> Morgan-type >> daylight
- count >> binary
#cheminformatics
We focused on weaknesses of the fingerprints.
Many show frequent duplicates, so same fingerprint for different compounds. Most problematic: this can include *very* different compounds ending up with identical fingerprints.
- MAP4 >> Morgan-type >> daylight
- count >> binary
#cheminformatics