


Matt Perich
@mattperich.bsky.social
Neuroscience, engineering, AI, music. Asst. Professor / PI at University of Montréal and Mila.
This one from Fig 2 of POYO is a bit clearer; still a relatively small effect but this is in a simple task where single session models are pushing saturation, with 75%+ performance. I would hypothesize that if we subsampled single sessions to even smaller sets we'd get more gains from pre-training.
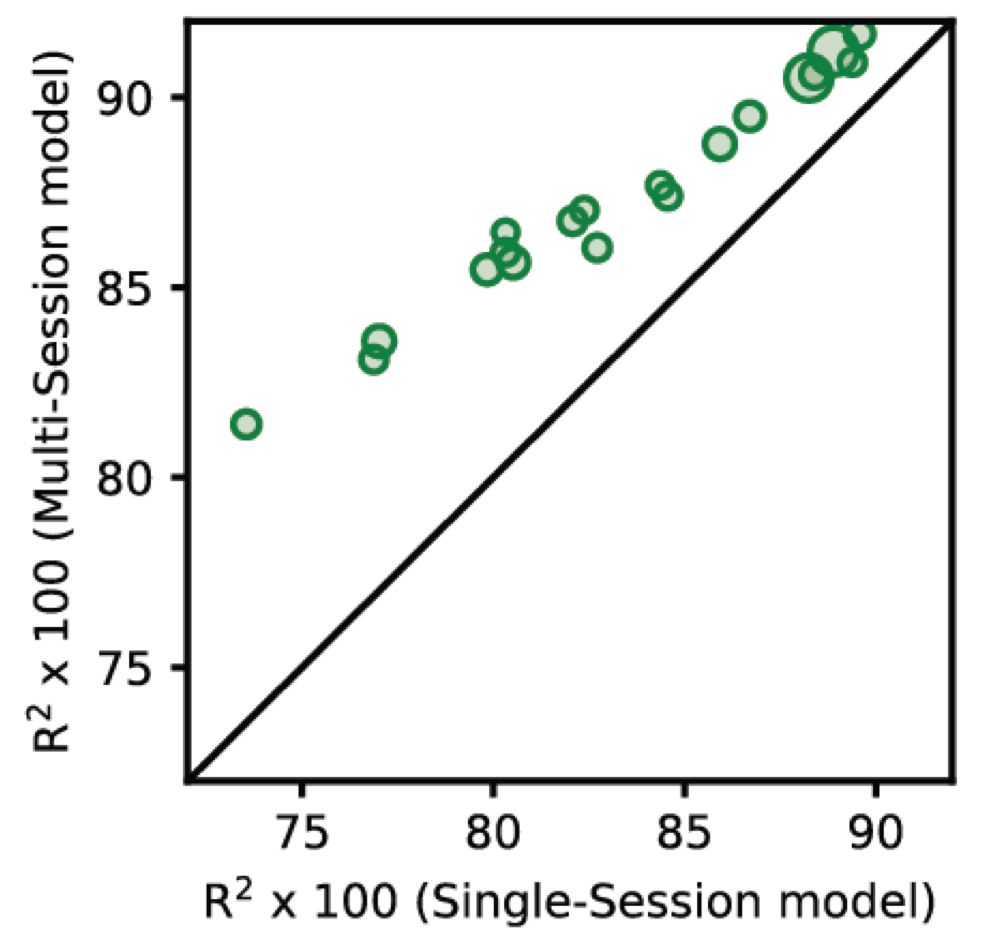
January 6, 2025 at 9:14 PM
This one from Fig 2 of POYO is a bit clearer; still a relatively small effect but this is in a simple task where single session models are pushing saturation, with 75%+ performance. I would hypothesize that if we subsampled single sessions to even smaller sets we'd get more gains from pre-training.