



Matteo Saponati
@matteosaponati.bsky.social
I am a research scientist in Machine Learning and Neuroscience. I am fascinated by life and intelligence, and I like to study complex systems. I love to play music and dance.
Postdoctoral Research Scientist @ ETH Zürich
↳ https://matteosaponati.github.io
Postdoctoral Research Scientist @ ETH Zürich
↳ https://matteosaponati.github.io
5/ Finally, we leveraged symmetry to improve Transformer training.
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️

February 18, 2025 at 12:22 PM
5/ Finally, we leveraged symmetry to improve Transformer training.
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️
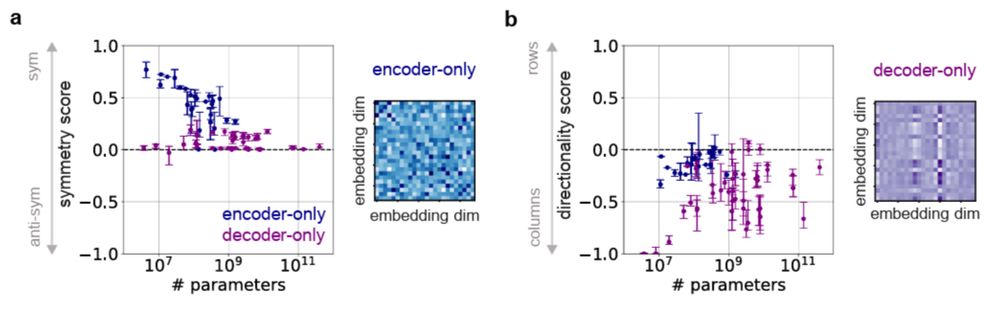
4/ We validate our analysis empirically showing that these patterns consistently emerge different language models and input modalities such as text, vision, and audio models.
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
February 18, 2025 at 12:22 PM
4/ We validate our analysis empirically showing that these patterns consistently emerge different language models and input modalities such as text, vision, and audio models.
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️