



Matteo Saponati
@matteosaponati.bsky.social
I am a research scientist in Machine Learning and Neuroscience. I am fascinated by life and intelligence, and I like to study complex systems. I love to play music and dance.
Postdoctoral Research Scientist @ ETH Zürich
↳ https://matteosaponati.github.io
Postdoctoral Research Scientist @ ETH Zürich
↳ https://matteosaponati.github.io
really great work! nice to see some feedback control :)
May 29, 2025 at 10:52 AM
really great work! nice to see some feedback control :)
uh! Very interesting, great work! nice to see that feedback control approaches are getting more famous :)
May 29, 2025 at 10:50 AM
uh! Very interesting, great work! nice to see that feedback control approaches are getting more famous :)
April 16, 2025 at 10:31 AM
fantastic post, and tasty food for thoughts.
shamelessly adding here that many different types of STDP come about from minimizing a prediction of the future loss function with spikes :)
hopefully another case of successful predictions.
www.nature.com/articles/s41...
shamelessly adding here that many different types of STDP come about from minimizing a prediction of the future loss function with spikes :)
hopefully another case of successful predictions.
www.nature.com/articles/s41...

Sequence anticipation and spike-timing-dependent plasticity emerge from a predictive learning rule - Nature Communications
Prediction of future inputs is a key computational task for the brain. Here, the authors proposed a predictive learning rule in neurons that leads to anticipation and recall of inputs, and that reprod...
www.nature.com
March 23, 2025 at 9:49 AM
fantastic post, and tasty food for thoughts.
shamelessly adding here that many different types of STDP come about from minimizing a prediction of the future loss function with spikes :)
hopefully another case of successful predictions.
www.nature.com/articles/s41...
shamelessly adding here that many different types of STDP come about from minimizing a prediction of the future loss function with spikes :)
hopefully another case of successful predictions.
www.nature.com/articles/s41...
7/ I would like to thank Pascal Sager for all the training, the writing, the discussion, and whatnot, Pau Vilimelis Aceituno for the hours spent on refining the math, Thilo Stadelmann and Benjamin Grewe for their great contribution and supervision, and all the people at INI.
cheers 💜
cheers 💜
a cartoon of two robots standing next to each other and the words `` bye '' .
ALT: a cartoon of two robots standing next to each other and the words `` bye '' .
media.tenor.com
February 18, 2025 at 12:22 PM
7/ I would like to thank Pascal Sager for all the training, the writing, the discussion, and whatnot, Pau Vilimelis Aceituno for the hours spent on refining the math, Thilo Stadelmann and Benjamin Grewe for their great contribution and supervision, and all the people at INI.
cheers 💜
cheers 💜
6/ TL;DR
- Self-attention matrices in Transformers show universal structural differences based on training.
- Bidirectional models → Symmetric self-attention
- Autoregressive models → Directional, column-dominant
- Using symmetry as an inductive bias improves training.
⬇️
- Self-attention matrices in Transformers show universal structural differences based on training.
- Bidirectional models → Symmetric self-attention
- Autoregressive models → Directional, column-dominant
- Using symmetry as an inductive bias improves training.
⬇️
February 18, 2025 at 12:22 PM
6/ TL;DR
- Self-attention matrices in Transformers show universal structural differences based on training.
- Bidirectional models → Symmetric self-attention
- Autoregressive models → Directional, column-dominant
- Using symmetry as an inductive bias improves training.
⬇️
- Self-attention matrices in Transformers show universal structural differences based on training.
- Bidirectional models → Symmetric self-attention
- Autoregressive models → Directional, column-dominant
- Using symmetry as an inductive bias improves training.
⬇️
5/ Finally, we leveraged symmetry to improve Transformer training.
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️

February 18, 2025 at 12:22 PM
5/ Finally, we leveraged symmetry to improve Transformer training.
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️
- Initializing self-attention matrices symmetrically improves training efficiency for bidirectional models, leading to faster convergence.
This suggest that imposing structures at initialization can enhance training dynamics.
⬇️
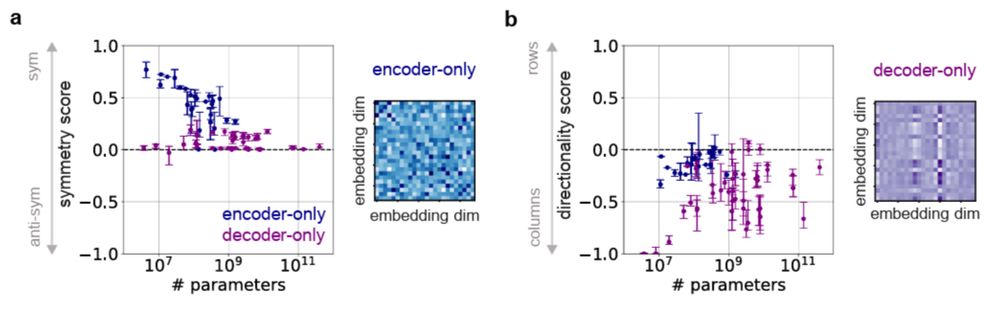
4/ We validate our analysis empirically showing that these patterns consistently emerge different language models and input modalities such as text, vision, and audio models.
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
February 18, 2025 at 12:22 PM
4/ We validate our analysis empirically showing that these patterns consistently emerge different language models and input modalities such as text, vision, and audio models.
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
- ModernBERT, GPT, LLaMA3, Mistral, etc
- Text, vision, and audio models
- Different model sizes, and architectures
⬇️
3/ We demonstrate that the self-attention matrices behaves differently for different training objectives:
- Bidirectional training (BERT-style) induces symmetric self-attention structures.
- Autoregressive training (GPT-style) induces directional structures with column dominance.
⬇️
- Bidirectional training (BERT-style) induces symmetric self-attention structures.
- Autoregressive training (GPT-style) induces directional structures with column dominance.
⬇️
February 18, 2025 at 12:22 PM
3/ We demonstrate that the self-attention matrices behaves differently for different training objectives:
- Bidirectional training (BERT-style) induces symmetric self-attention structures.
- Autoregressive training (GPT-style) induces directional structures with column dominance.
⬇️
- Bidirectional training (BERT-style) induces symmetric self-attention structures.
- Autoregressive training (GPT-style) induces directional structures with column dominance.
⬇️
2/ Self-attention is the backbone of Transformer models, but how does training shape the internal structure of self-attention matrices?
We introduce a mathematical framework to study these matrices and uncover fundamental differences in how they are updated during gradient descent.
⬇️
We introduce a mathematical framework to study these matrices and uncover fundamental differences in how they are updated during gradient descent.
⬇️
February 18, 2025 at 12:22 PM
2/ Self-attention is the backbone of Transformer models, but how does training shape the internal structure of self-attention matrices?
We introduce a mathematical framework to study these matrices and uncover fundamental differences in how they are updated during gradient descent.
⬇️
We introduce a mathematical framework to study these matrices and uncover fundamental differences in how they are updated during gradient descent.
⬇️
Hey Dan! I would like to be added :)
January 7, 2025 at 8:46 PM
Hey Dan! I would like to be added :)