



Luke Sanford
@lcsanford.bsky.social
Assistant Prof. at Yale School of the Environment. Political economy of climate and environment, land use change, remote sensing, causal ML. https://sanford-lab.github.io/
Reposted by Luke Sanford

You can read find more about details at www.journals.uchicago.edu/doi/10.1086/... Thanks to all that helped along the way!

July 9, 2025 at 10:16 AM
You can read find more about details at www.journals.uchicago.edu/doi/10.1086/... Thanks to all that helped along the way!
Omg I did this in graduate school and it was the worst.
May 9, 2025 at 7:40 PM
Omg I did this in graduate school and it was the worst.
Here's what that image was supposed to look like:

March 18, 2025 at 12:12 AM
Here's what that image was supposed to look like:
We went for roads since it's easy to see how that measurement error could arise. Often we have no idea why RS + ML errors occur

March 18, 2025 at 12:10 AM
We went for roads since it's easy to see how that measurement error could arise. Often we have no idea why RS + ML errors occur
@bstewart.bsky.social and co-authors explore the same issue in text measurement models like LLMs and find something similar--even small measurement errors can lead to large biases in downstream causal tasks when they aren't orthogonal to treatment
March 18, 2025 at 12:10 AM
@bstewart.bsky.social and co-authors explore the same issue in text measurement models like LLMs and find something similar--even small measurement errors can lead to large biases in downstream causal tasks when they aren't orthogonal to treatment
@sandysum.bsky.social and co-authors test a different method to correct for the same source of bias across many remotely sensed variables and ground truth data and find this everywhere (www.nber.org/papers/w30861)

Parameter Recovery Using Remotely Sensed Variables
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research and to disseminating research findings among academics, public policy makers, an...
www.nber.org
March 18, 2025 at 12:10 AM
@sandysum.bsky.social and co-authors test a different method to correct for the same source of bias across many remotely sensed variables and ground truth data and find this everywhere (www.nber.org/papers/w30861)
Imagine you run a land tenure reform RCT, DV is tree cover. It turns out your treatment also causes more irrigated ag, which is mis-classified as treecover more often than rainfed ag (year-round greenness). Estimated treatment effect will be > that true treatment effect.
March 18, 2025 at 12:10 AM
Imagine you run a land tenure reform RCT, DV is tree cover. It turns out your treatment also causes more irrigated ag, which is mis-classified as treecover more often than rainfed ag (year-round greenness). Estimated treatment effect will be > that true treatment effect.
While that's our running example for the paper, definitely a broader issue here. We think assuming no correlation between measurement error and treatment is akin to the selection on observables assumption we usually require extraordinary evidence to believe. A couple examples below:
March 18, 2025 at 12:10 AM
While that's our running example for the paper, definitely a broader issue here. We think assuming no correlation between measurement error and treatment is akin to the selection on observables assumption we usually require extraordinary evidence to believe. A couple examples below:
9/9
Other great work in this area: www.nber.org/papers/w30861, arxiv.org/abs/2501.18577, arxiv.org/abs/2411.10959, arxiv.org/abs/2306.04746 focus on “predict-then-debias”—the right move if using off the shelf data. But if you’re training the ML model yourself, give our adversarial approach a try!
Other great work in this area: www.nber.org/papers/w30861, arxiv.org/abs/2501.18577, arxiv.org/abs/2411.10959, arxiv.org/abs/2306.04746 focus on “predict-then-debias”—the right move if using off the shelf data. But if you’re training the ML model yourself, give our adversarial approach a try!
Parameter Recovery Using Remotely Sensed Variables
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research and to disseminating research findings among academics, public policy makers, an...
www.nber.org
March 17, 2025 at 7:30 PM
9/9
Other great work in this area: www.nber.org/papers/w30861, arxiv.org/abs/2501.18577, arxiv.org/abs/2411.10959, arxiv.org/abs/2306.04746 focus on “predict-then-debias”—the right move if using off the shelf data. But if you’re training the ML model yourself, give our adversarial approach a try!
Other great work in this area: www.nber.org/papers/w30861, arxiv.org/abs/2501.18577, arxiv.org/abs/2411.10959, arxiv.org/abs/2306.04746 focus on “predict-then-debias”—the right move if using off the shelf data. But if you’re training the ML model yourself, give our adversarial approach a try!
8/9
Reach out if you want to debias some measurements in a particular application!
Reach out if you want to debias some measurements in a particular application!
March 17, 2025 at 7:30 PM
8/9
Reach out if you want to debias some measurements in a particular application!
Reach out if you want to debias some measurements in a particular application!
7/9
It’s easy to plug in any causal variable that might bias your ML-driven proxy. The adversary directly leverages your labeled data—so if you’re building custom measurement models with large-scale images (or text), you just tack on the adversary, retrain, and your bias vanishes.
8/9
It’s easy to plug in any causal variable that might bias your ML-driven proxy. The adversary directly leverages your labeled data—so if you’re building custom measurement models with large-scale images (or text), you just tack on the adversary, retrain, and your bias vanishes.
8/9

a cartoon of spongebob giving the thumbs up with the words too easy below him
ALT: a cartoon of spongebob giving the thumbs up with the words too easy below him
media.tenor.com
March 17, 2025 at 7:30 PM
7/9
It’s easy to plug in any causal variable that might bias your ML-driven proxy. The adversary directly leverages your labeled data—so if you’re building custom measurement models with large-scale images (or text), you just tack on the adversary, retrain, and your bias vanishes.
8/9
It’s easy to plug in any causal variable that might bias your ML-driven proxy. The adversary directly leverages your labeled data—so if you’re building custom measurement models with large-scale images (or text), you just tack on the adversary, retrain, and your bias vanishes.
8/9
6/9
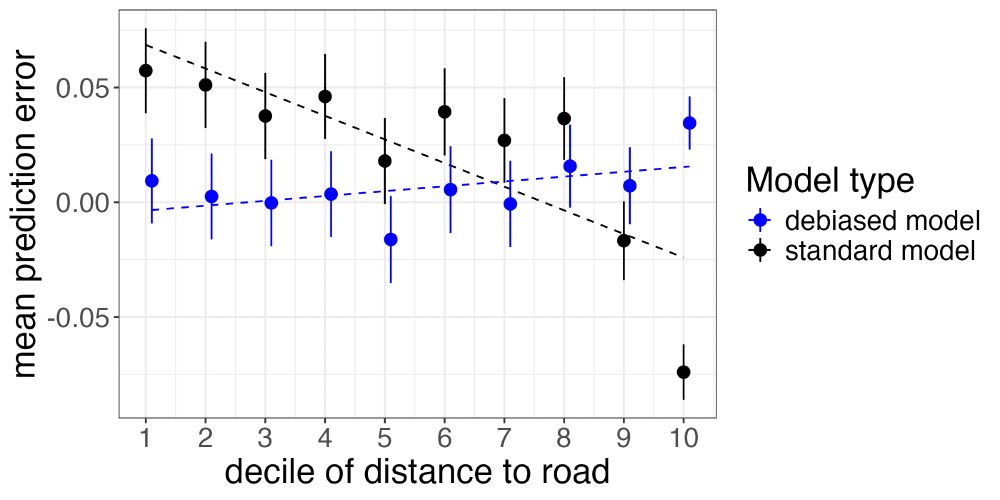
We then use a labeled forest cover data from high-resolution imagery. When comparing the ML predictions to ground-truth labels, a naive model under-estimates forest cover near roads. Our adversarial model, by contrast, recovers unbiased estimates, giving more reliable coefficients.
We then use a labeled forest cover data from high-resolution imagery. When comparing the ML predictions to ground-truth labels, a naive model under-estimates forest cover near roads. Our adversarial model, by contrast, recovers unbiased estimates, giving more reliable coefficients.
March 17, 2025 at 7:30 PM
6/9
We then use a labeled forest cover data from high-resolution imagery. When comparing the ML predictions to ground-truth labels, a naive model under-estimates forest cover near roads. Our adversarial model, by contrast, recovers unbiased estimates, giving more reliable coefficients.
We then use a labeled forest cover data from high-resolution imagery. When comparing the ML predictions to ground-truth labels, a naive model under-estimates forest cover near roads. Our adversarial model, by contrast, recovers unbiased estimates, giving more reliable coefficients.
5/9
We induce measurement error bias in a simulation of the effect of roads on forest cover. We show that a naive model yields biased estimates of this relationship, while an adversarial model gets it right.
We induce measurement error bias in a simulation of the effect of roads on forest cover. We show that a naive model yields biased estimates of this relationship, while an adversarial model gets it right.

March 17, 2025 at 7:30 PM
5/9
We induce measurement error bias in a simulation of the effect of roads on forest cover. We show that a naive model yields biased estimates of this relationship, while an adversarial model gets it right.
We induce measurement error bias in a simulation of the effect of roads on forest cover. We show that a naive model yields biased estimates of this relationship, while an adversarial model gets it right.
4/9
We also introduce a simple bias test: regress the ML prediction errors on your independent variable. If nonzero, you have measurement error bias. If you run that test while gathering ground-truth data, you can estimate how many labeled observations you’ll need to reject a target amount of bias.
We also introduce a simple bias test: regress the ML prediction errors on your independent variable. If nonzero, you have measurement error bias. If you run that test while gathering ground-truth data, you can estimate how many labeled observations you’ll need to reject a target amount of bias.

March 17, 2025 at 7:30 PM
4/9
We also introduce a simple bias test: regress the ML prediction errors on your independent variable. If nonzero, you have measurement error bias. If you run that test while gathering ground-truth data, you can estimate how many labeled observations you’ll need to reject a target amount of bias.
We also introduce a simple bias test: regress the ML prediction errors on your independent variable. If nonzero, you have measurement error bias. If you run that test while gathering ground-truth data, you can estimate how many labeled observations you’ll need to reject a target amount of bias.
3/9
Here’s how: a primary model predicts the outcome, while an adversarial model tries to predict the treatment using the prediction errors. As the adversary learns how to predict treatment, the primary model learns to make predictions where the errors contain no information about the treatment.
Here’s how: a primary model predicts the outcome, while an adversarial model tries to predict the treatment using the prediction errors. As the adversary learns how to predict treatment, the primary model learns to make predictions where the errors contain no information about the treatment.

March 17, 2025 at 7:30 PM
3/9
Here’s how: a primary model predicts the outcome, while an adversarial model tries to predict the treatment using the prediction errors. As the adversary learns how to predict treatment, the primary model learns to make predictions where the errors contain no information about the treatment.
Here’s how: a primary model predicts the outcome, while an adversarial model tries to predict the treatment using the prediction errors. As the adversary learns how to predict treatment, the primary model learns to make predictions where the errors contain no information about the treatment.
2/9
We are inspired by the algorithmic fairness literature. There, adversarial models force models to have balanced prediction errors across the dist. of a protected attribute (e.g. race). We adapt that approach, but instead of race, our “protected attribute” is the independent variable of interest.
We are inspired by the algorithmic fairness literature. There, adversarial models force models to have balanced prediction errors across the dist. of a protected attribute (e.g. race). We adapt that approach, but instead of race, our “protected attribute” is the independent variable of interest.
March 17, 2025 at 7:30 PM
2/9
We are inspired by the algorithmic fairness literature. There, adversarial models force models to have balanced prediction errors across the dist. of a protected attribute (e.g. race). We adapt that approach, but instead of race, our “protected attribute” is the independent variable of interest.
We are inspired by the algorithmic fairness literature. There, adversarial models force models to have balanced prediction errors across the dist. of a protected attribute (e.g. race). We adapt that approach, but instead of race, our “protected attribute” is the independent variable of interest.