


Laurits Skov
@lauritsskov.bsky.social
I study Neanderthals, Denisovans and the effect of their DNA surviving in present day humans. Assistant professor at section for molecular ecology and evolution at Globe Institute Copenhagen, Denmark.
And thanks to Lidia Gonfaus for making this beautiful illustration! :)
May 5, 2025 at 2:26 PM
And thanks to Lidia Gonfaus for making this beautiful illustration! :)
We hope this method will be useful to people and look forward to hearing your feedback!
May 5, 2025 at 1:34 PM
We hope this method will be useful to people and look forward to hearing your feedback!
We also found cases where hybrid decoding recovers a putative neanderthal fragment that was split in two by posterior decoding and where only half was found by viterbi decoding.

May 5, 2025 at 1:34 PM
We also found cases where hybrid decoding recovers a putative neanderthal fragment that was split in two by posterior decoding and where only half was found by viterbi decoding.
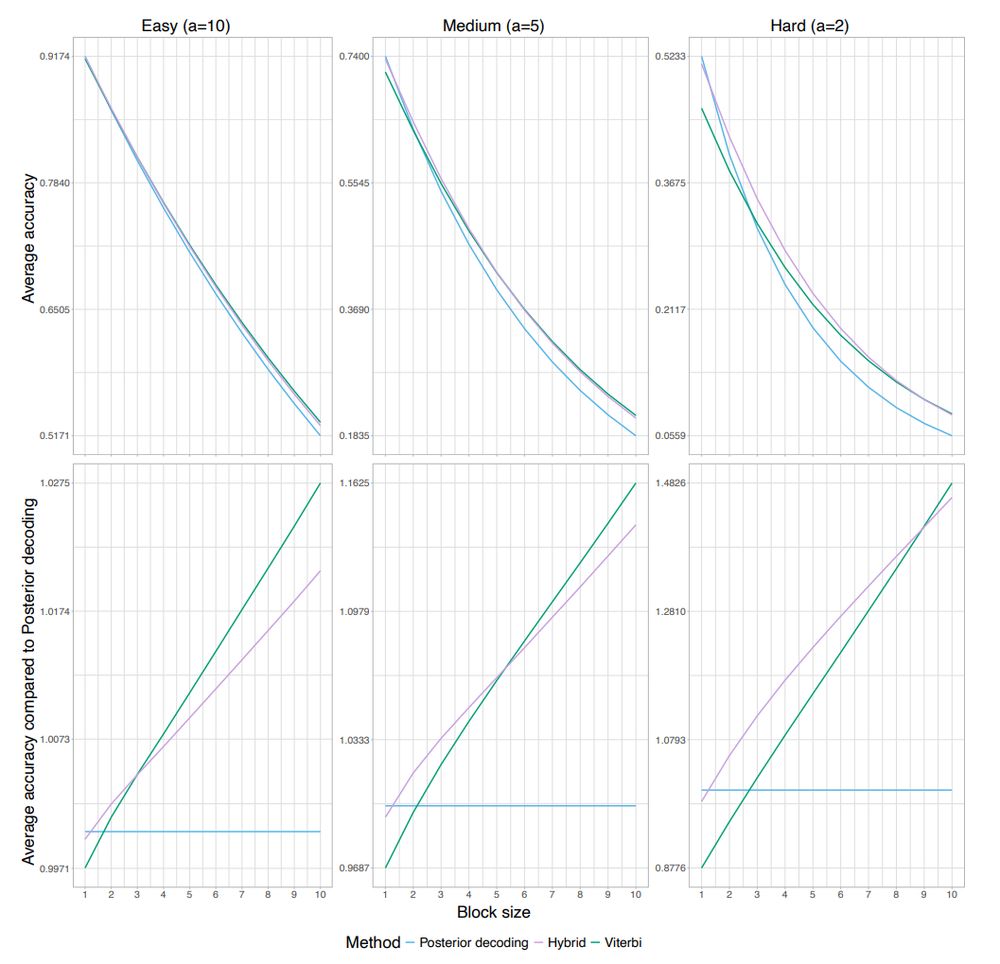
In practice this hybrid decoding has the highest accuracy when it comes to intermediate sized fragments. For short fragment posterior decoding is best and for long fragments viterbi is best.
May 5, 2025 at 1:34 PM
In practice this hybrid decoding has the highest accuracy when it comes to intermediate sized fragments. For short fragment posterior decoding is best and for long fragments viterbi is best.
We recommend picking the alpha closest to the 45 degree line (ideally you want to be as close to the top right corner as possible). We call these plots Artemis plots because of the bow like shape!

May 5, 2025 at 1:34 PM
We recommend picking the alpha closest to the 45 degree line (ideally you want to be as close to the top right corner as possible). We call these plots Artemis plots because of the bow like shape!
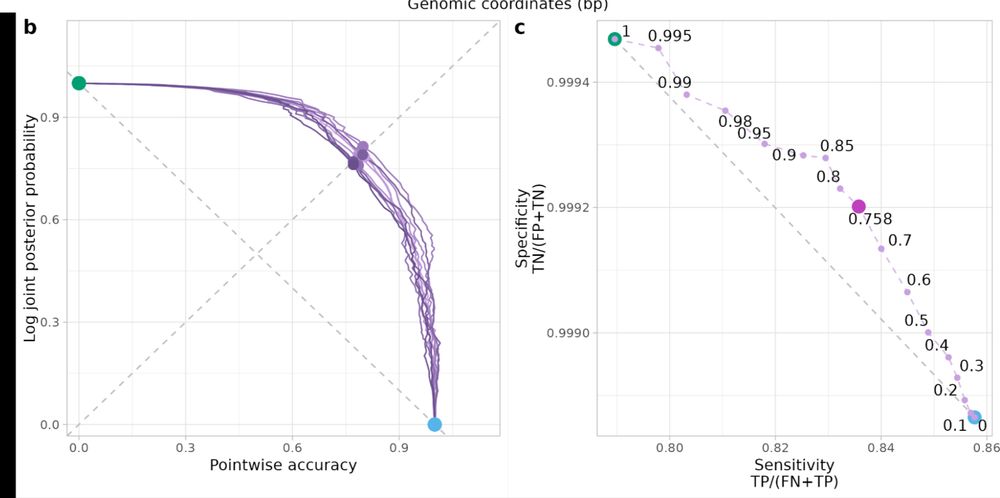
If you simulate data from your emission and transition parameters you can calculate point wise accuracy/joint posterior probability and sensitivity/specificity plots for each alpha and pick the best one!
May 5, 2025 at 1:34 PM
If you simulate data from your emission and transition parameters you can calculate point wise accuracy/joint posterior probability and sensitivity/specificity plots for each alpha and pick the best one!
The best alpha will depend on the specific emission and transition parameters. Also an alpha of 0.5 does not nescessaraly mark the halfway point between the two methods. There we propose a simulation approach for picking the appropriate alpha for your analyse.
May 5, 2025 at 1:34 PM
The best alpha will depend on the specific emission and transition parameters. Also an alpha of 0.5 does not nescessaraly mark the halfway point between the two methods. There we propose a simulation approach for picking the appropriate alpha for your analyse.
If only there was a way to have your cake and eat it too! Inspired by previous work we propose a weighted mean of posterior and viterbi decoding controlled by a parameter alpha. When alpha = 0 you get posterior decoding and when alpha = 1 you get viterbi. When alpha is intermediate you get a mix.

May 5, 2025 at 1:34 PM
If only there was a way to have your cake and eat it too! Inspired by previous work we propose a weighted mean of posterior and viterbi decoding controlled by a parameter alpha. When alpha = 0 you get posterior decoding and when alpha = 1 you get viterbi. When alpha is intermediate you get a mix.
Posterior decoding maximixes the local probability - that is the pointwise accuracy. This leads to more short fragments being recovered but also a higher false positive rate.
May 5, 2025 at 1:34 PM
Posterior decoding maximixes the local probability - that is the pointwise accuracy. This leads to more short fragments being recovered but also a higher false positive rate.
Viterbi decoding maximixes the global probability of the hidden state path. While leading to high accuracy this decoding tends to not switch states as often as it should and many short segments will be lost.
May 5, 2025 at 1:34 PM
Viterbi decoding maximixes the global probability of the hidden state path. While leading to high accuracy this decoding tends to not switch states as often as it should and many short segments will be lost.
This part of the manuscript has to do with finding the best decoded path for a hidden markov model so let's talk the two most used: Viterbi and posterior decoding
May 5, 2025 at 1:34 PM
This part of the manuscript has to do with finding the best decoded path for a hidden markov model so let's talk the two most used: Viterbi and posterior decoding
If you haven't already you can go follow the amazing:
@moicoll.bsky.social , @zeniabaek.bsky.social and @asgerhobolth.bsky.social :)
@moicoll.bsky.social , @zeniabaek.bsky.social and @asgerhobolth.bsky.social :)
May 2, 2025 at 2:20 PM
If you haven't already you can go follow the amazing:
@moicoll.bsky.social , @zeniabaek.bsky.social and @asgerhobolth.bsky.social :)
@moicoll.bsky.social , @zeniabaek.bsky.social and @asgerhobolth.bsky.social :)
The analytical is based on finite markov chain embedding :) The bimodal longest has to do with fact that in sometimes the longest fragments breaks in two!
May 1, 2025 at 9:39 PM
The analytical is based on finite markov chain embedding :) The bimodal longest has to do with fact that in sometimes the longest fragments breaks in two!
This was a great collaboration with Moisès Coll Macià, Zenia Elise Damgaard Bæk and Asger Hobolth :)
May 1, 2025 at 1:13 PM
This was a great collaboration with Moisès Coll Macià, Zenia Elise Damgaard Bæk and Asger Hobolth :)
While this approach is useful for obtaining summary statistics it is not good at finding a single good hidden state path through the genome like Viterbi/posterior decoding. We have some thought on that too but that is for another thread!
May 1, 2025 at 1:13 PM
While this approach is useful for obtaining summary statistics it is not good at finding a single good hidden state path through the genome like Viterbi/posterior decoding. We have some thought on that too but that is for another thread!
This sampling approach is easy to implement and can be used for all HMMs commenly used! One could calculate what the distribution of long IBD fragments are between two ancient individuals, how much time you are in a given TMRCA state for PSMC or sample paths through the Li
-Stephens copying model.
-Stephens copying model.
May 1, 2025 at 1:13 PM
This sampling approach is easy to implement and can be used for all HMMs commenly used! One could calculate what the distribution of long IBD fragments are between two ancient individuals, how much time you are in a given TMRCA state for PSMC or sample paths through the Li
-Stephens copying model.
-Stephens copying model.
We also show that our estimates of Neanderthal ancestry is consistent with f4 ratio estimates and we recover the signal of different archaic fragment length distributions across continental groups! We explored the explanations for this signal previously (www.nature.com/articles/s41...)

May 1, 2025 at 1:13 PM
We also show that our estimates of Neanderthal ancestry is consistent with f4 ratio estimates and we recover the signal of different archaic fragment length distributions across continental groups! We explored the explanations for this signal previously (www.nature.com/articles/s41...)
You can even get close to the true fragment length distribution. Black vertical line is true mean fragment length and black curve is expected theoretical distribution. Colored dotted vertical lines are means for each decoding type

May 1, 2025 at 1:13 PM
You can even get close to the true fragment length distribution. Black vertical line is true mean fragment length and black curve is expected theoretical distribution. Colored dotted vertical lines are means for each decoding type
We show that by sampling hidden state sequences you can accurately recover summmary statistics (black dotted line) such as: How much of our genome is archaic? How many archaic fragments of DNA is there? How long is the longest fragment? You can even do it analytically! (red curve)

May 1, 2025 at 1:13 PM
We show that by sampling hidden state sequences you can accurately recover summmary statistics (black dotted line) such as: How much of our genome is archaic? How many archaic fragments of DNA is there? How long is the longest fragment? You can even do it analytically! (red curve)
Another strategy is to sample many decoded paths conditioned on the data. The benefit of this is that sometimes you find the short fragments! And instead of one decoded path you have many sampled paths from which you can calculate any summary statistic you want (with confidence intervals!)

May 1, 2025 at 1:13 PM
Another strategy is to sample many decoded paths conditioned on the data. The benefit of this is that sometimes you find the short fragments! And instead of one decoded path you have many sampled paths from which you can calculate any summary statistic you want (with confidence intervals!)
Decoding is not perfect and we cannot find all the archaic DNA fragments our genomes - especially when they are short. For decoding people typically use Viterbi decoding (more accurate but misses many archaic fragments) or Posterior decoding (less accurate but finds more archaic fragments)
May 1, 2025 at 1:13 PM
Decoding is not perfect and we cannot find all the archaic DNA fragments our genomes - especially when they are short. For decoding people typically use Viterbi decoding (more accurate but misses many archaic fragments) or Posterior decoding (less accurate but finds more archaic fragments)