



@lafirespols.bsky.social
June 11, 2025 at 10:23 AM
“Gunfire”

June 11, 2025 at 7:40 AM
“Gunfire”
Reposted

OpenAI's new multi-modal image output, added to
GPT-4o and ChatGPT this morning, finally gave me the selfie with a bear I've always wanted simonwillison.net/2025/Mar/25/...
GPT-4o and ChatGPT this morning, finally gave me the selfie with a bear I've always wanted simonwillison.net/2025/Mar/25/...

Introducing 4o Image Generation
When OpenAI first announced GPT-4o [back in May 2024](https://simonwillison.net/2024/May/13/gpt-4o/) one of the most exciting features was true multi-modality in that it could both input _and_ output ...
simonwillison.net
March 25, 2025 at 9:12 PM
OpenAI's new multi-modal image output, added to
GPT-4o and ChatGPT this morning, finally gave me the selfie with a bear I've always wanted simonwillison.net/2025/Mar/25/...
GPT-4o and ChatGPT this morning, finally gave me the selfie with a bear I've always wanted simonwillison.net/2025/Mar/25/...
Reposted

Xavier transitioned and became Vivian Jenna Wilson. She is alive and well and lives in Japan.
No loving parent would ever write such a disgusting thing as this, and it speaks volumes.
No loving parent would ever write such a disgusting thing as this, and it speaks volumes.
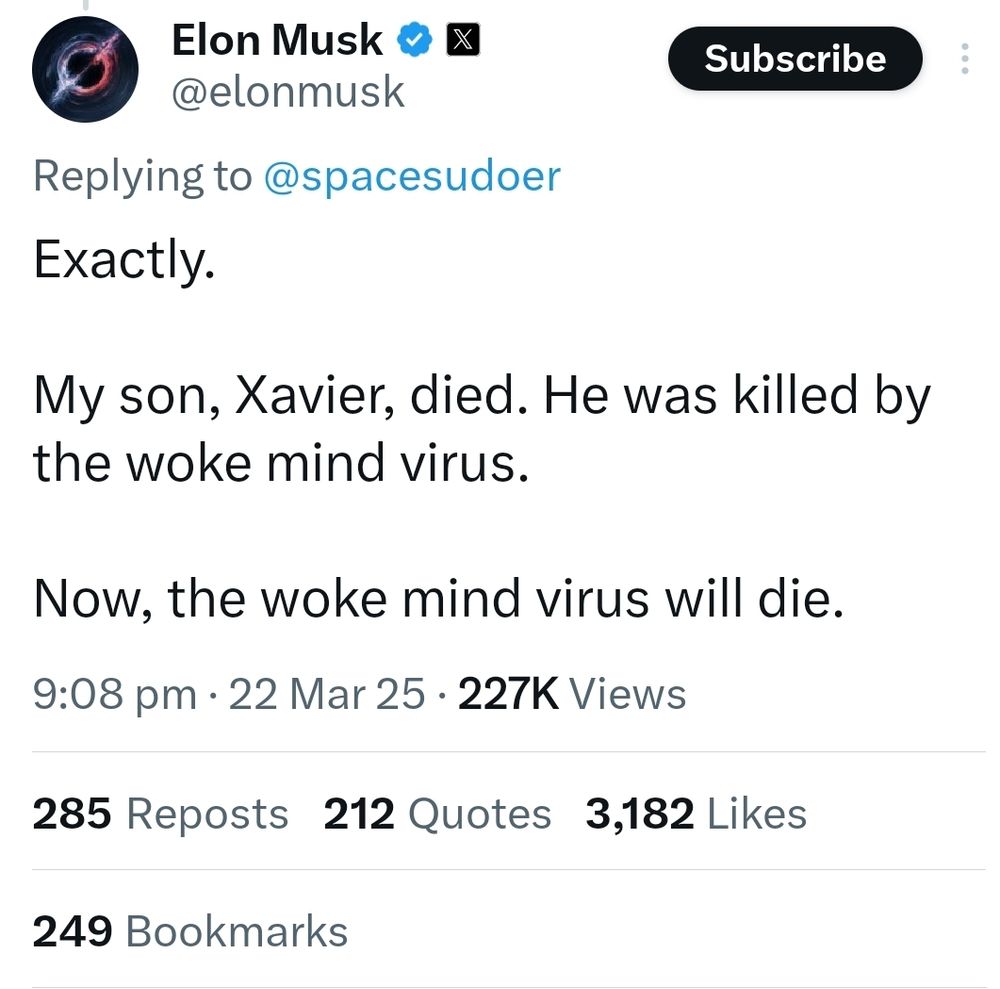
March 23, 2025 at 7:50 AM
Xavier transitioned and became Vivian Jenna Wilson. She is alive and well and lives in Japan.
No loving parent would ever write such a disgusting thing as this, and it speaks volumes.
No loving parent would ever write such a disgusting thing as this, and it speaks volumes.
Reposted

@rohanpaul_ai https://x.com/rohanpaul_ai/status/1897831567873261587 #x-rohanpaul_ai
LLMs use fixed strategies for all questions.
This is inefficient for complex reasoning. This paper introduces self-taught lookahead (STL). It improves value estimation in language models by learning ...
LLMs use fixed strategies for all questions.
This is inefficient for complex reasoning. This paper introduces self-taught lookahead (STL). It improves value estimation in language models by learning ...

March 7, 2025 at 2:30 AM
@rohanpaul_ai https://x.com/rohanpaul_ai/status/1897831567873261587 #x-rohanpaul_ai
LLMs use fixed strategies for all questions.
This is inefficient for complex reasoning. This paper introduces self-taught lookahead (STL). It improves value estimation in language models by learning ...
LLMs use fixed strategies for all questions.
This is inefficient for complex reasoning. This paper introduces self-taught lookahead (STL). It improves value estimation in language models by learning ...
Reposted

Clever test of AI reasoning ability adds the option "none of these" to the common MMLU benchmark, forcing the AI to consider options rather than just picking the best
The result is a big drop in accuracy for most models, though Reasoners (o3 & DeepSeek) hold up much better arxiv.org/pdf/2502.12896
The result is a big drop in accuracy for most models, though Reasoners (o3 & DeepSeek) hold up much better arxiv.org/pdf/2502.12896


February 20, 2025 at 4:34 PM
Clever test of AI reasoning ability adds the option "none of these" to the common MMLU benchmark, forcing the AI to consider options rather than just picking the best
The result is a big drop in accuracy for most models, though Reasoners (o3 & DeepSeek) hold up much better arxiv.org/pdf/2502.12896
The result is a big drop in accuracy for most models, though Reasoners (o3 & DeepSeek) hold up much better arxiv.org/pdf/2502.12896
Reposted

OpenAI’s newly launched Deep Research mirrors Google’s tool of the same name. Agents can now search for you.
Have we really thought what this will do to libraries and databases? What about those in analytical and research professions?
www.theverge.com/news/604902/...
Have we really thought what this will do to libraries and databases? What about those in analytical and research professions?
www.theverge.com/news/604902/...

ChatGPT’s agent can now do deep research for you
More accurate, and more resource intensive.
www.theverge.com
February 3, 2025 at 1:03 AM
OpenAI’s newly launched Deep Research mirrors Google’s tool of the same name. Agents can now search for you.
Have we really thought what this will do to libraries and databases? What about those in analytical and research professions?
www.theverge.com/news/604902/...
Have we really thought what this will do to libraries and databases? What about those in analytical and research professions?
www.theverge.com/news/604902/...
Reposted

This kind of deep research?
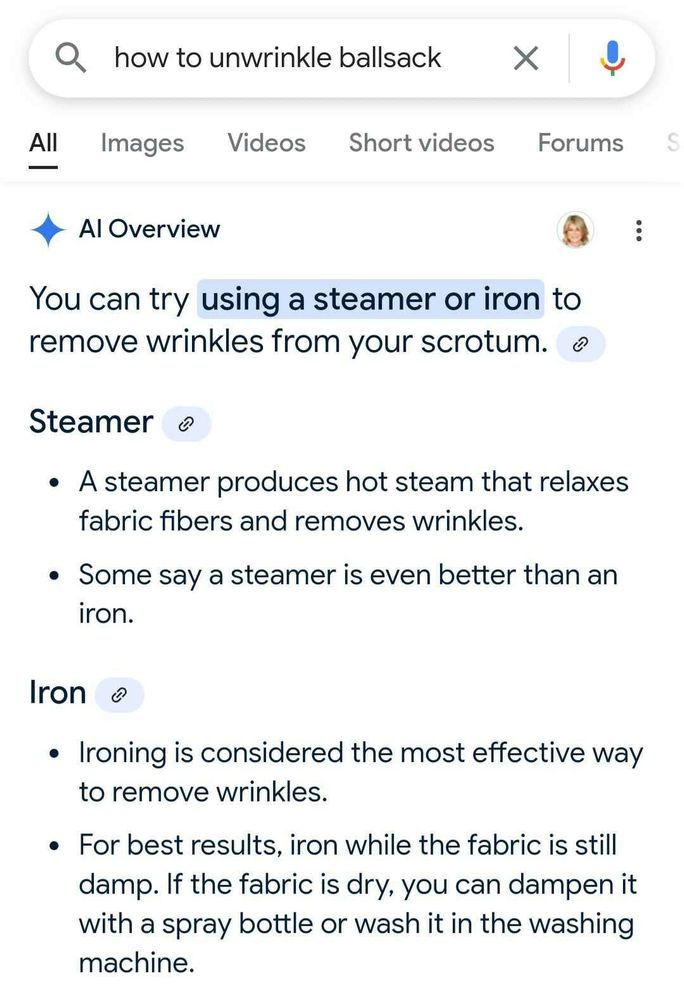
February 3, 2025 at 12:13 AM
This kind of deep research?
Reposted

@emollick
Nice way to test when #AI can replace human evaluators & judges, it compares if #llms align better with group consensus than individual human evaluators do
#GPT-4 & #Gemini pass the test in 8/10 tasks, but struggle with deep contextual understanding […]
[Original post on mstdn.social]
Nice way to test when #AI can replace human evaluators & judges, it compares if #llms align better with group consensus than individual human evaluators do
#GPT-4 & #Gemini pass the test in 8/10 tasks, but struggle with deep contextual understanding […]
[Original post on mstdn.social]

January 27, 2025 at 12:06 AM
@emollick
Nice way to test when #AI can replace human evaluators & judges, it compares if #llms align better with group consensus than individual human evaluators do
#GPT-4 & #Gemini pass the test in 8/10 tasks, but struggle with deep contextual understanding […]
[Original post on mstdn.social]
Nice way to test when #AI can replace human evaluators & judges, it compares if #llms align better with group consensus than individual human evaluators do
#GPT-4 & #Gemini pass the test in 8/10 tasks, but struggle with deep contextual understanding […]
[Original post on mstdn.social]