



Luigi Acerbi
@lacerbi.bsky.social
Assoc. Prof. of Machine & Human Intelligence | Univ. Helsinki & Finnish Centre for AI (FCAI) | Bayesian ML & probabilistic modeling | https://lacerbi.github.io/
Do you like to train neural networks to solve all your nasty probabilistic inference and sequential design problems?
Do you love letter salads such as NPs, PFNs, NPE, SBI, BED?
Then no place is better than the Amortized ProbML workshop we are organizing at #ELLIS UnConference.
Do you love letter salads such as NPs, PFNs, NPE, SBI, BED?
Then no place is better than the Amortized ProbML workshop we are organizing at #ELLIS UnConference.

October 1, 2025 at 1:57 PM
Do you like to train neural networks to solve all your nasty probabilistic inference and sequential design problems?
Do you love letter salads such as NPs, PFNs, NPE, SBI, BED?
Then no place is better than the Amortized ProbML workshop we are organizing at #ELLIS UnConference.
Do you love letter salads such as NPs, PFNs, NPE, SBI, BED?
Then no place is better than the Amortized ProbML workshop we are organizing at #ELLIS UnConference.
Remember to follow the official rebuttal guide.

July 27, 2025 at 7:08 AM
Remember to follow the official rebuttal guide.
New blog post!
You can train a neural network to *just do things* -- such as *predict the optimum of a function*. But how do you get a big training dataset of "functions with known optima"?
Read the blog post to find out! (link 👇)
You can train a neural network to *just do things* -- such as *predict the optimum of a function*. But how do you get a big training dataset of "functions with known optima"?
Read the blog post to find out! (link 👇)

June 26, 2025 at 2:29 PM
New blog post!
You can train a neural network to *just do things* -- such as *predict the optimum of a function*. But how do you get a big training dataset of "functions with known optima"?
Read the blog post to find out! (link 👇)
You can train a neural network to *just do things* -- such as *predict the optimum of a function*. But how do you get a big training dataset of "functions with known optima"?
Read the blog post to find out! (link 👇)
1/ If you are at ICLR / AABI / AISTATS, check out work from our lab and collaborators on *inference everywhere anytime all at once*!
Go talk to my incredible PhD students @huangdaolang.bsky.social & @chengkunli.bsky.social + amazing collaborator Severi Rissanen.
@univhelsinkics.bsky.social FCAI
Go talk to my incredible PhD students @huangdaolang.bsky.social & @chengkunli.bsky.social + amazing collaborator Severi Rissanen.
@univhelsinkics.bsky.social FCAI

April 27, 2025 at 8:53 AM
1/ If you are at ICLR / AABI / AISTATS, check out work from our lab and collaborators on *inference everywhere anytime all at once*!
Go talk to my incredible PhD students @huangdaolang.bsky.social & @chengkunli.bsky.social + amazing collaborator Severi Rissanen.
@univhelsinkics.bsky.social FCAI
Go talk to my incredible PhD students @huangdaolang.bsky.social & @chengkunli.bsky.social + amazing collaborator Severi Rissanen.
@univhelsinkics.bsky.social FCAI
10/10
Read the full paper #AABI2025 Proceedings Track!
Work by @chengkunli.bsky.social, @abacabadabacaba.bsky.social, Petrus Mikkola, & yours truly.
📜 Paper: arxiv.org/abs/2504.11554
💻 Code: github.com/acerbilab/no...
📄 Overview: acerbilab.github.io/normalizing-...
Let us know what you think!
Read the full paper #AABI2025 Proceedings Track!
Work by @chengkunli.bsky.social, @abacabadabacaba.bsky.social, Petrus Mikkola, & yours truly.
📜 Paper: arxiv.org/abs/2504.11554
💻 Code: github.com/acerbilab/no...
📄 Overview: acerbilab.github.io/normalizing-...
Let us know what you think!

April 22, 2025 at 11:01 AM
10/10
Read the full paper #AABI2025 Proceedings Track!
Work by @chengkunli.bsky.social, @abacabadabacaba.bsky.social, Petrus Mikkola, & yours truly.
📜 Paper: arxiv.org/abs/2504.11554
💻 Code: github.com/acerbilab/no...
📄 Overview: acerbilab.github.io/normalizing-...
Let us know what you think!
Read the full paper #AABI2025 Proceedings Track!
Work by @chengkunli.bsky.social, @abacabadabacaba.bsky.social, Petrus Mikkola, & yours truly.
📜 Paper: arxiv.org/abs/2504.11554
💻 Code: github.com/acerbilab/no...
📄 Overview: acerbilab.github.io/normalizing-...
Let us know what you think!
9/10
In sum: NFR offers a practical way to perform Bayesian inference for expensive models by recycling existing log-likelihood evaluations (e.g., from MAP). You get a usable posterior *and* model evidence estimate directly!
Or, as GPT-4.5 put it, "Fast Flows, Not Slow Chains".
In sum: NFR offers a practical way to perform Bayesian inference for expensive models by recycling existing log-likelihood evaluations (e.g., from MAP). You get a usable posterior *and* model evidence estimate directly!
Or, as GPT-4.5 put it, "Fast Flows, Not Slow Chains".

April 22, 2025 at 11:01 AM
9/10
In sum: NFR offers a practical way to perform Bayesian inference for expensive models by recycling existing log-likelihood evaluations (e.g., from MAP). You get a usable posterior *and* model evidence estimate directly!
Or, as GPT-4.5 put it, "Fast Flows, Not Slow Chains".
In sum: NFR offers a practical way to perform Bayesian inference for expensive models by recycling existing log-likelihood evaluations (e.g., from MAP). You get a usable posterior *and* model evidence estimate directly!
Or, as GPT-4.5 put it, "Fast Flows, Not Slow Chains".
8/10 📊 Benchmarks
Across 5 increasingly gnarly and realistic problems, up to D=12 NFR, wins or ties every metric against strong baselines.
Across 5 increasingly gnarly and realistic problems, up to D=12 NFR, wins or ties every metric against strong baselines.

April 22, 2025 at 11:01 AM
8/10 📊 Benchmarks
Across 5 increasingly gnarly and realistic problems, up to D=12 NFR, wins or ties every metric against strong baselines.
Across 5 increasingly gnarly and realistic problems, up to D=12 NFR, wins or ties every metric against strong baselines.
7/10 3️⃣ Annealed optimization
We use annealed optimization (β‑tempering) so the model morphs smoothly from the base distribution to the target posterior.
We use annealed optimization (β‑tempering) so the model morphs smoothly from the base distribution to the target posterior.

April 22, 2025 at 11:01 AM
7/10 3️⃣ Annealed optimization
We use annealed optimization (β‑tempering) so the model morphs smoothly from the base distribution to the target posterior.
We use annealed optimization (β‑tempering) so the model morphs smoothly from the base distribution to the target posterior.
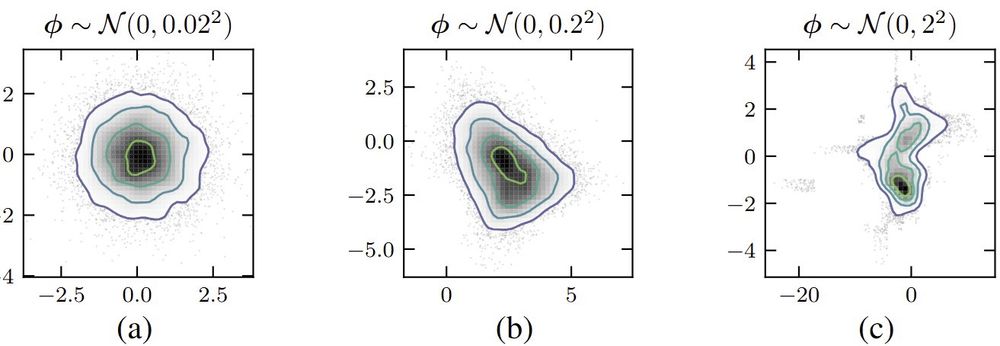
6/10 2️⃣ Prior over flows
We place a prior on flow parameters - 👉a prior over distributions👈 - to tame them!
This regularizes the learned posterior shape, preventing weird fits.
We place a prior on flow parameters - 👉a prior over distributions👈 - to tame them!
This regularizes the learned posterior shape, preventing weird fits.
April 22, 2025 at 11:01 AM
6/10 2️⃣ Prior over flows
We place a prior on flow parameters - 👉a prior over distributions👈 - to tame them!
This regularizes the learned posterior shape, preventing weird fits.
We place a prior on flow parameters - 👉a prior over distributions👈 - to tame them!
This regularizes the learned posterior shape, preventing weird fits.
5/10 1️⃣ Robust Tobit likelihood:
We censor values below a very-low-density threshold, focusing training on the high‑probability regions that matter.
We censor values below a very-low-density threshold, focusing training on the high‑probability regions that matter.

April 22, 2025 at 11:01 AM
5/10 1️⃣ Robust Tobit likelihood:
We censor values below a very-low-density threshold, focusing training on the high‑probability regions that matter.
We censor values below a very-low-density threshold, focusing training on the high‑probability regions that matter.
3/10
Our idea: Use a **Normalizing Flow** not just for density estimation, but as a *regression* model!
NFR directly fits the flow to existing log-density evaluations, learning the posterior shape *and* the normalizing constant C in one go.
Our idea: Use a **Normalizing Flow** not just for density estimation, but as a *regression* model!
NFR directly fits the flow to existing log-density evaluations, learning the posterior shape *and* the normalizing constant C in one go.

April 22, 2025 at 11:01 AM
3/10
Our idea: Use a **Normalizing Flow** not just for density estimation, but as a *regression* model!
NFR directly fits the flow to existing log-density evaluations, learning the posterior shape *and* the normalizing constant C in one go.
Our idea: Use a **Normalizing Flow** not just for density estimation, but as a *regression* model!
NFR directly fits the flow to existing log-density evaluations, learning the posterior shape *and* the normalizing constant C in one go.
1/10🔥 New paper alert in #AABI2025 Proceedings!
Normalizing Flow Regression (NFR) — an offline Bayesian inference method.
What if you could get a full posterior using *only* the evaluations you *already* have, maybe from optimization runs?
Normalizing Flow Regression (NFR) — an offline Bayesian inference method.
What if you could get a full posterior using *only* the evaluations you *already* have, maybe from optimization runs?

April 22, 2025 at 11:01 AM
1/10🔥 New paper alert in #AABI2025 Proceedings!
Normalizing Flow Regression (NFR) — an offline Bayesian inference method.
What if you could get a full posterior using *only* the evaluations you *already* have, maybe from optimization runs?
Normalizing Flow Regression (NFR) — an offline Bayesian inference method.
What if you could get a full posterior using *only* the evaluations you *already* have, maybe from optimization runs?
2/ ... if you actually want to learn more about the paper, we also put together a webpage with the key takeaways:
acerbilab.github.io/amortized-co...
acerbilab.github.io/amortized-co...

April 8, 2025 at 3:28 PM
2/ ... if you actually want to learn more about the paper, we also put together a webpage with the key takeaways:
acerbilab.github.io/amortized-co...
acerbilab.github.io/amortized-co...
1/ We asked GPT-4.5 -- allegedly the model with the best sense of humor, according to the site we do not talk about here -- to write a comic about our recent AISTATS paper on the Amortized Conditioning Engine (ACE). Then gpt-4o drew it.
You judge the result...
(text continues 👇)
You judge the result...
(text continues 👇)

April 8, 2025 at 3:28 PM
1/ We asked GPT-4.5 -- allegedly the model with the best sense of humor, according to the site we do not talk about here -- to write a comic about our recent AISTATS paper on the Amortized Conditioning Engine (ACE). Then gpt-4o drew it.
You judge the result...
(text continues 👇)
You judge the result...
(text continues 👇)
1/ Just saw this paper using our PyVBMC (acerbilab.github.io/pyvbmc/) in structural engineering.
Nice to see sample-efficient Bayesian inference for expensive computational models used in the wild!
(Although we feel a bit more pressure to triple-check that our implementation has no bugs...)
Nice to see sample-efficient Bayesian inference for expensive computational models used in the wild!
(Although we feel a bit more pressure to triple-check that our implementation has no bugs...)

April 7, 2025 at 2:03 PM
1/ Just saw this paper using our PyVBMC (acerbilab.github.io/pyvbmc/) in structural engineering.
Nice to see sample-efficient Bayesian inference for expensive computational models used in the wild!
(Although we feel a bit more pressure to triple-check that our implementation has no bugs...)
Nice to see sample-efficient Bayesian inference for expensive computational models used in the wild!
(Although we feel a bit more pressure to triple-check that our implementation has no bugs...)

I read the Race ending first. Spoiler: Humans do not fare well. That's the Director's Cut.
Then started the "Slowdown" ending and, erm, superintelligences need to speak in English in Slack and cannot steganography their way out?
Yep, this is the Studio Cut.
Then started the "Slowdown" ending and, erm, superintelligences need to speak in English in Slack and cannot steganography their way out?
Yep, this is the Studio Cut.

April 4, 2025 at 1:42 PM
I read the Race ending first. Spoiler: Humans do not fare well. That's the Director's Cut.
Then started the "Slowdown" ending and, erm, superintelligences need to speak in English in Slack and cannot steganography their way out?
Yep, this is the Studio Cut.
Then started the "Slowdown" ending and, erm, superintelligences need to speak in English in Slack and cannot steganography their way out?
Yep, this is the Studio Cut.
Besides Deep Research, I just saw this but had not the time to try it: paperfinder.allen.ai/chat
I just tried your prompt and it seems it found something, but for example it did not ignore reviews, and not sure about the highly-cited.
I just tried your prompt and it seems it found something, but for example it did not ignore reviews, and not sure about the highly-cited.

March 29, 2025 at 4:53 PM
Besides Deep Research, I just saw this but had not the time to try it: paperfinder.allen.ai/chat
I just tried your prompt and it seems it found something, but for example it did not ignore reviews, and not sure about the highly-cited.
I just tried your prompt and it seems it found something, but for example it did not ignore reviews, and not sure about the highly-cited.

As an aside, Nowadays I first look at livebench or similar researcher driven benchmarks. These tend to correlate with real capabilities a bit more (still, unless the model builders cheat, everything correlates with everything, except perhaps small models which may break outside test envs).

March 29, 2025 at 10:17 AM
As an aside, Nowadays I first look at livebench or similar researcher driven benchmarks. These tend to correlate with real capabilities a bit more (still, unless the model builders cheat, everything correlates with everything, except perhaps small models which may break outside test envs).

1/ No AGI yet, but native image generation is showing massive improvements - see the new ChatGPT feature.
We still cannot quite generate correct plots for slides and papers just by asking nicely, but this is way better than anything we had before.
We still cannot quite generate correct plots for slides and papers just by asking nicely, but this is way better than anything we had before.

March 26, 2025 at 7:17 AM
1/ No AGI yet, but native image generation is showing massive improvements - see the new ChatGPT feature.
We still cannot quite generate correct plots for slides and papers just by asking nicely, but this is way better than anything we had before.
We still cannot quite generate correct plots for slides and papers just by asking nicely, but this is way better than anything we had before.
9/ Technically, ACE is a Transformer Diagonal Prediction Map with explicit latents and priors + GMM or categorical outputs. Though we predict 1D marginals independently, we can still sample from joint distributions *autoregressively* when needed. And predictions are calibrated!

March 6, 2025 at 10:32 AM
9/ Technically, ACE is a Transformer Diagonal Prediction Map with explicit latents and priors + GMM or categorical outputs. Though we predict 1D marginals independently, we can still sample from joint distributions *autoregressively* when needed. And predictions are calibrated!
8/ Ex 3: Simulation-based inference. ACE can infer posterior distributions over model parameters AND generate predictive data. We tested it on several simulator models, matching or beating specialized SBI methods (inevitable comparison table👇).

March 6, 2025 at 10:32 AM
8/ Ex 3: Simulation-based inference. ACE can infer posterior distributions over model parameters AND generate predictive data. We tested it on several simulator models, matching or beating specialized SBI methods (inevitable comparison table👇).
7/ We can even put a prior on where the optimum x* might be, or its value y*, from domain knowledge. ACE updates that prior with observed data in a single forward pass, showing significant performance boosts—especially with stronger priors—, comparable to dedicated approaches.

March 6, 2025 at 10:32 AM
7/ We can even put a prior on where the optimum x* might be, or its value y*, from domain knowledge. ACE updates that prior with observed data in a single forward pass, showing significant performance boosts—especially with stronger priors—, comparable to dedicated approaches.