




Kyutai
@kyutai-labs.bsky.social
https://kyutai.org/ Open-Science AI Research Lab based in Paris
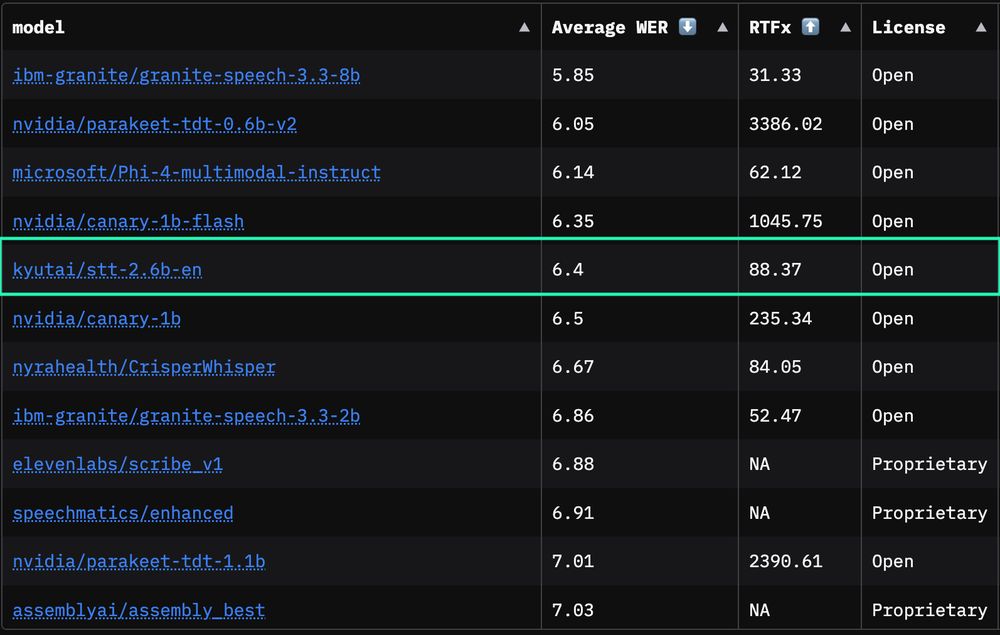
Our latest open-source speech-to-text model just claimed 1st place among streaming models and 5th place overall on the OpenASR leaderboard 🥇🎙️
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
June 27, 2025 at 10:31 AM
Our latest open-source speech-to-text model just claimed 1st place among streaming models and 5th place overall on the OpenASR leaderboard 🥇🎙️
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
The text LLM’s response is passed to our TTS, conditioned on a 10s voice sample. We’ll provide access to the voice cloning model in a controlled way. The TTS is also streaming *in text*, reducing the latency by starting to speak even before the full text response is generated.
May 23, 2025 at 10:14 AM
The text LLM’s response is passed to our TTS, conditioned on a 10s voice sample. We’ll provide access to the voice cloning model in a controlled way. The TTS is also streaming *in text*, reducing the latency by starting to speak even before the full text response is generated.
Unmute’s speech-to-text is streaming, accurate, and includes a semantic VAD that predicts whether you’ve actually finished speaking or if you’re just pausing mid-sentence, meaning it’s low-latency but doesn’t interrupt you.
May 23, 2025 at 10:14 AM
Unmute’s speech-to-text is streaming, accurate, and includes a semantic VAD that predicts whether you’ve actually finished speaking or if you’re just pausing mid-sentence, meaning it’s low-latency but doesn’t interrupt you.
Talk to unmute.sh 🔊, the most modular voice AI around. Empower any text LLM with voice, instantly, by wrapping it with our new speech-to-text and text-to-speech. Any personality, any voice. Interruptible, smart turn-taking. We’ll open-source everything within the next few weeks.
May 23, 2025 at 10:14 AM
Talk to unmute.sh 🔊, the most modular voice AI around. Empower any text LLM with voice, instantly, by wrapping it with our new speech-to-text and text-to-speech. Any personality, any voice. Interruptible, smart turn-taking. We’ll open-source everything within the next few weeks.
🚀 Thrilled to announce Helium 1, our new 2B-parameter LLM, now available alongside dactory, an open-source pipeline to reproduce its training dataset covering all 24 EU official languages. Helium sets new standards within its size class on European languages!

May 5, 2025 at 10:39 AM
🚀 Thrilled to announce Helium 1, our new 2B-parameter LLM, now available alongside dactory, an open-source pipeline to reproduce its training dataset covering all 24 EU official languages. Helium sets new standards within its size class on European languages!
Have you enjoyed talking to 🟢Moshi and dreamt of making your own speech to speech chat experience🧑🔬🤖? It's now possible with the moshi-finetune codebase! Plug your own dataset and change the voice/tone/personality of Moshi 💚🔌💿. An example after finetuning w/ only 20 hours of the DailyTalk dataset. 🧵
April 1, 2025 at 3:47 PM
Have you enjoyed talking to 🟢Moshi and dreamt of making your own speech to speech chat experience🧑🔬🤖? It's now possible with the moshi-finetune codebase! Plug your own dataset and change the voice/tone/personality of Moshi 💚🔌💿. An example after finetuning w/ only 20 hours of the DailyTalk dataset. 🧵
🧰 Fully open-source
We’re releasing a preprint, model weights and a benchmark dataset for spoken visual question answering:
📄 Preprint arxiv.org/abs/2503.15633
🧠 Dataset huggingface.co/datasets/kyu...
🧾 Model weights huggingface.co/kyutai/moshi...
🧪 Inference code github.com/kyutai-labs/...
We’re releasing a preprint, model weights and a benchmark dataset for spoken visual question answering:
📄 Preprint arxiv.org/abs/2503.15633
🧠 Dataset huggingface.co/datasets/kyu...
🧾 Model weights huggingface.co/kyutai/moshi...
🧪 Inference code github.com/kyutai-labs/...
March 21, 2025 at 2:39 PM
🧰 Fully open-source
We’re releasing a preprint, model weights and a benchmark dataset for spoken visual question answering:
📄 Preprint arxiv.org/abs/2503.15633
🧠 Dataset huggingface.co/datasets/kyu...
🧾 Model weights huggingface.co/kyutai/moshi...
🧪 Inference code github.com/kyutai-labs/...
We’re releasing a preprint, model weights and a benchmark dataset for spoken visual question answering:
📄 Preprint arxiv.org/abs/2503.15633
🧠 Dataset huggingface.co/datasets/kyu...
🧾 Model weights huggingface.co/kyutai/moshi...
🧪 Inference code github.com/kyutai-labs/...
🧠 How it works
MoshiVis builds on Moshi, our speech-to-speech LLM — now enhanced with vision.
206M lightweight parameters on top of a frozen Moshi give it the power to discuss images while still remaining real-time on consumer-grade hardware.
MoshiVis builds on Moshi, our speech-to-speech LLM — now enhanced with vision.
206M lightweight parameters on top of a frozen Moshi give it the power to discuss images while still remaining real-time on consumer-grade hardware.
March 21, 2025 at 2:39 PM
🧠 How it works
MoshiVis builds on Moshi, our speech-to-speech LLM — now enhanced with vision.
206M lightweight parameters on top of a frozen Moshi give it the power to discuss images while still remaining real-time on consumer-grade hardware.
MoshiVis builds on Moshi, our speech-to-speech LLM — now enhanced with vision.
206M lightweight parameters on top of a frozen Moshi give it the power to discuss images while still remaining real-time on consumer-grade hardware.
March 21, 2025 at 2:39 PM
Meet MoshiVis🎙️🖼️, the first open-source real-time speech model that can talk about images!
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
March 21, 2025 at 2:39 PM
Meet MoshiVis🎙️🖼️, the first open-source real-time speech model that can talk about images!
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
Even Kavinsky 🎧🪩 can't break Hibiki! Just like Moshi, Hibiki is robust to extreme background conditions 💥🔊.
February 11, 2025 at 4:11 PM
Even Kavinsky 🎧🪩 can't break Hibiki! Just like Moshi, Hibiki is robust to extreme background conditions 💥🔊.
Hibiki’s smaller alternative, Hibiki-M, runs on-device in real time. Hibiki-M was obtained by distilling the full model into a smaller version with only 1.7B parameters. On an iPhone 16 Pro, Hibiki-M runs in real-time for more than a minute as shown by Tom.
February 7, 2025 at 8:22 AM
Hibiki’s smaller alternative, Hibiki-M, runs on-device in real time. Hibiki-M was obtained by distilling the full model into a smaller version with only 1.7B parameters. On an iPhone 16 Pro, Hibiki-M runs in real-time for more than a minute as shown by Tom.
To train Hibiki, we generated bilingual data of simultaneous interpretation where a word only appears in the target when it's predictable from the source. We developed a new method based on an off-the-shelf text translation system and using a TTS system with constraints on word locations.

February 7, 2025 at 8:22 AM
To train Hibiki, we generated bilingual data of simultaneous interpretation where a word only appears in the target when it's predictable from the source. We developed a new method based on an off-the-shelf text translation system and using a TTS system with constraints on word locations.
Based on objective and human evaluations, Hibiki outperforms previous systems for quality, naturalness and speaker similarity and approaches human interpreters.
Here is an example of a live conference interpretation.
Here is an example of a live conference interpretation.
February 7, 2025 at 8:22 AM
Based on objective and human evaluations, Hibiki outperforms previous systems for quality, naturalness and speaker similarity and approaches human interpreters.
Here is an example of a live conference interpretation.
Here is an example of a live conference interpretation.
Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
February 7, 2025 at 8:22 AM
Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
Helium 2B running locally on an iPhone 16 Pro at ~28 tok/s, faster than you can read your loga lessons in French 🚀 All that thanks to mlx-swift with q4 quantization!
January 14, 2025 at 4:38 PM
Helium 2B running locally on an iPhone 16 Pro at ~28 tok/s, faster than you can read your loga lessons in French 🚀 All that thanks to mlx-swift with q4 quantization!
Helium currently supports 6 languages (English, French, German, Italian, Portuguese and Spanish) and will be extended to more languages shortly. Here is a summary of Helium's performance on multilingual benchmarks.

January 13, 2025 at 5:50 PM
Helium currently supports 6 languages (English, French, German, Italian, Portuguese and Spanish) and will be extended to more languages shortly. Here is a summary of Helium's performance on multilingual benchmarks.