




Kyutai
@kyutai-labs.bsky.social
https://kyutai.org/ Open-Science AI Research Lab based in Paris
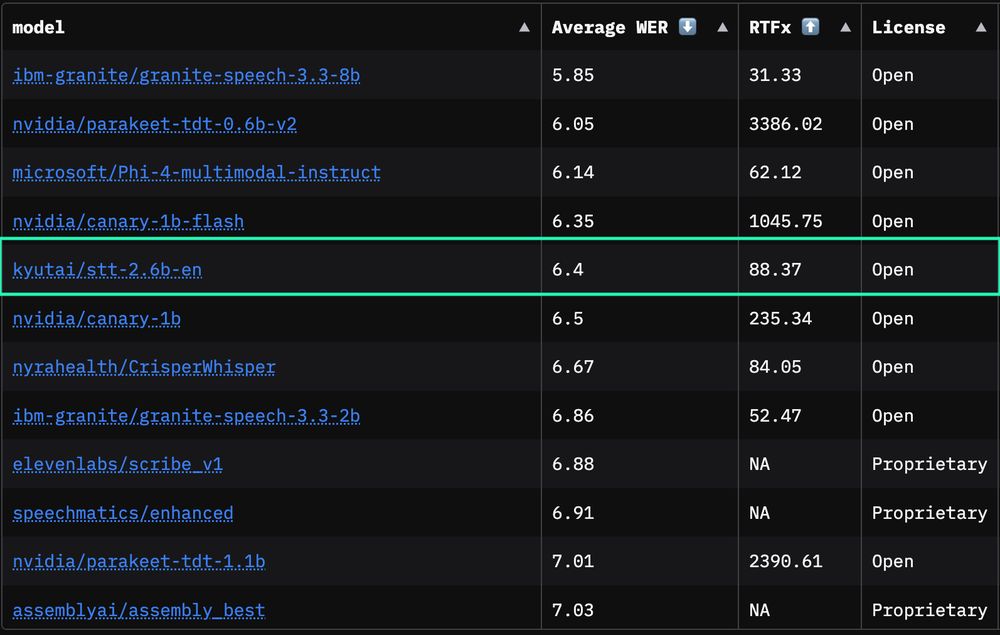
Our latest open-source speech-to-text model just claimed 1st place among streaming models and 5th place overall on the OpenASR leaderboard 🥇🎙️
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
June 27, 2025 at 10:31 AM
Our latest open-source speech-to-text model just claimed 1st place among streaming models and 5th place overall on the OpenASR leaderboard 🥇🎙️
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
Talk to unmute.sh 🔊, the most modular voice AI around. Empower any text LLM with voice, instantly, by wrapping it with our new speech-to-text and text-to-speech. Any personality, any voice. Interruptible, smart turn-taking. We’ll open-source everything within the next few weeks.
May 23, 2025 at 10:14 AM
Talk to unmute.sh 🔊, the most modular voice AI around. Empower any text LLM with voice, instantly, by wrapping it with our new speech-to-text and text-to-speech. Any personality, any voice. Interruptible, smart turn-taking. We’ll open-source everything within the next few weeks.
🚀 Thrilled to announce Helium 1, our new 2B-parameter LLM, now available alongside dactory, an open-source pipeline to reproduce its training dataset covering all 24 EU official languages. Helium sets new standards within its size class on European languages!

May 5, 2025 at 10:39 AM
🚀 Thrilled to announce Helium 1, our new 2B-parameter LLM, now available alongside dactory, an open-source pipeline to reproduce its training dataset covering all 24 EU official languages. Helium sets new standards within its size class on European languages!
Have you enjoyed talking to 🟢Moshi and dreamt of making your own speech to speech chat experience🧑🔬🤖? It's now possible with the moshi-finetune codebase! Plug your own dataset and change the voice/tone/personality of Moshi 💚🔌💿. An example after finetuning w/ only 20 hours of the DailyTalk dataset. 🧵
April 1, 2025 at 3:47 PM
Have you enjoyed talking to 🟢Moshi and dreamt of making your own speech to speech chat experience🧑🔬🤖? It's now possible with the moshi-finetune codebase! Plug your own dataset and change the voice/tone/personality of Moshi 💚🔌💿. An example after finetuning w/ only 20 hours of the DailyTalk dataset. 🧵
Meet MoshiVis🎙️🖼️, the first open-source real-time speech model that can talk about images!
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
March 21, 2025 at 2:39 PM
Meet MoshiVis🎙️🖼️, the first open-source real-time speech model that can talk about images!
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
Even Kavinsky 🎧🪩 can't break Hibiki! Just like Moshi, Hibiki is robust to extreme background conditions 💥🔊.
February 11, 2025 at 4:11 PM
Even Kavinsky 🎧🪩 can't break Hibiki! Just like Moshi, Hibiki is robust to extreme background conditions 💥🔊.
Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
February 7, 2025 at 8:22 AM
Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
Helium 2B running locally on an iPhone 16 Pro at ~28 tok/s, faster than you can read your loga lessons in French 🚀 All that thanks to mlx-swift with q4 quantization!
January 14, 2025 at 4:38 PM
Helium 2B running locally on an iPhone 16 Pro at ~28 tok/s, faster than you can read your loga lessons in French 🚀 All that thanks to mlx-swift with q4 quantization!
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/heliu...
huggingface.co/kyutai/heliu...

kyutai/helium-1-preview-2b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 13, 2025 at 5:50 PM
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/heliu...
huggingface.co/kyutai/heliu...