



Viet Anh Khoa Tran
@ktran.de
PhD student on Dendritic Learning/NeuroAI with Willem Wybo,
at Emre Neftci's lab (@fz-juelich.de).
ktran.de
at Emre Neftci's lab (@fz-juelich.de).
ktran.de
No, the loss is complementary to the traditional view-inv. contrastive loss, and we also use augmentations for the modulation-inv. positives.
And this is with end-to-end backprop (for now).
And this is with end-to-end backprop (for now).
October 25, 2025 at 5:39 PM
No, the loss is complementary to the traditional view-inv. contrastive loss, and we also use augmentations for the modulation-inv. positives.
And this is with end-to-end backprop (for now).
And this is with end-to-end backprop (for now).
Thanks Guillaume!
Exactly, only the ff params are learned during contrastive learning, and we "replay" different, frozen modulations for different positives, as we expect that an unlabeled class-c sample would yield an is-c positive under modulation c, and a is-not-c' positive under modulation c'.
Exactly, only the ff params are learned during contrastive learning, and we "replay" different, frozen modulations for different positives, as we expect that an unlabeled class-c sample would yield an is-c positive under modulation c, and a is-not-c' positive under modulation c'.
October 25, 2025 at 3:52 PM
Thanks Guillaume!
Exactly, only the ff params are learned during contrastive learning, and we "replay" different, frozen modulations for different positives, as we expect that an unlabeled class-c sample would yield an is-c positive under modulation c, and a is-not-c' positive under modulation c'.
Exactly, only the ff params are learned during contrastive learning, and we "replay" different, frozen modulations for different positives, as we expect that an unlabeled class-c sample would yield an is-c positive under modulation c, and a is-not-c' positive under modulation c'.
This is research from the new Dendritic Learning Group at PGI-15 (@fz-juelich.de).
A huge thanks to my supervisor Willem Wybo and our institute head Emre Neftci!
📄 Preprint: arxiv.org/abs/2505.14125
🚀 Project page: ktran.de/papers/tmcl/
Supported by (@fzj-jsc.bsky.social) and WestAI.
(6/6)
A huge thanks to my supervisor Willem Wybo and our institute head Emre Neftci!
📄 Preprint: arxiv.org/abs/2505.14125
🚀 Project page: ktran.de/papers/tmcl/
Supported by (@fzj-jsc.bsky.social) and WestAI.
(6/6)

Contrastive Consolidation of Top-Down Modulations Achieves Sparsely Supervised Continual Learning
Biological brains learn continually from a stream of unlabeled data, while integrating specialized information from sparsely labeled examples without compromising their ability to generalize. Meanwhil...
arxiv.org
June 10, 2025 at 1:17 PM
This is research from the new Dendritic Learning Group at PGI-15 (@fz-juelich.de).
A huge thanks to my supervisor Willem Wybo and our institute head Emre Neftci!
📄 Preprint: arxiv.org/abs/2505.14125
🚀 Project page: ktran.de/papers/tmcl/
Supported by (@fzj-jsc.bsky.social) and WestAI.
(6/6)
A huge thanks to my supervisor Willem Wybo and our institute head Emre Neftci!
📄 Preprint: arxiv.org/abs/2505.14125
🚀 Project page: ktran.de/papers/tmcl/
Supported by (@fzj-jsc.bsky.social) and WestAI.
(6/6)
This research opens up an exciting possibility: predictive coding as a fundamental cortical learning mechanism, guided by area-specific modulations that act as high-level control over the learning process. (5/6)
June 10, 2025 at 1:17 PM
This research opens up an exciting possibility: predictive coding as a fundamental cortical learning mechanism, guided by area-specific modulations that act as high-level control over the learning process. (5/6)
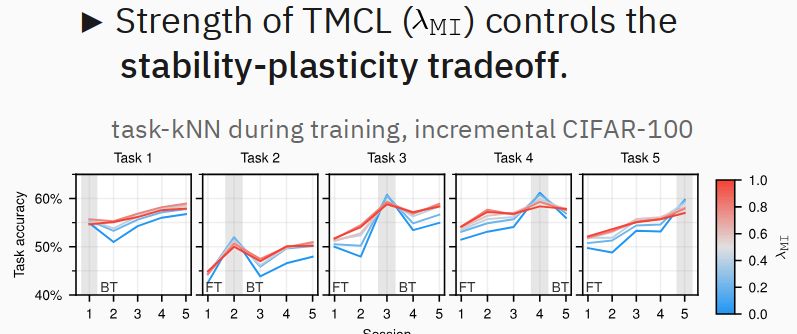
Furthermore, we can dynamically adjust the stability-plasticity trade-off by adapting the strength of the modulation invariance term. (4/6)
June 10, 2025 at 1:17 PM
Furthermore, we can dynamically adjust the stability-plasticity trade-off by adapting the strength of the modulation invariance term. (4/6)
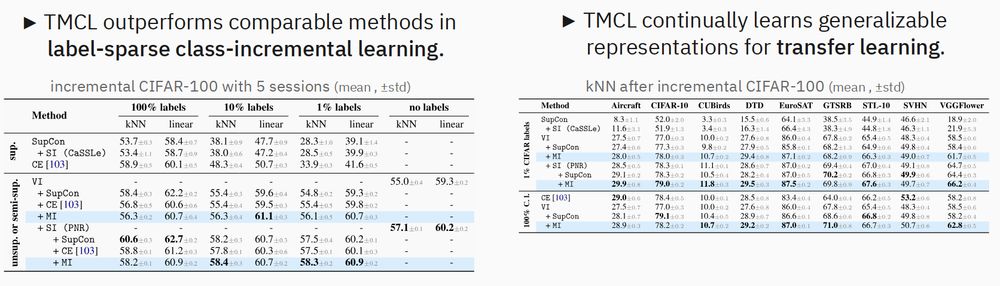
Key finding: With only 1% labels, our method outperforms comparable continual learning algorithms both on the continual task and when transferred to other tasks.
Therefore, we continually learn generalizable representations, unlike conventional, class-collapsing methods (e.g. Cross-Entropy). (3/6)
Therefore, we continually learn generalizable representations, unlike conventional, class-collapsing methods (e.g. Cross-Entropy). (3/6)
June 10, 2025 at 1:17 PM
Key finding: With only 1% labels, our method outperforms comparable continual learning algorithms both on the continual task and when transferred to other tasks.
Therefore, we continually learn generalizable representations, unlike conventional, class-collapsing methods (e.g. Cross-Entropy). (3/6)
Therefore, we continually learn generalizable representations, unlike conventional, class-collapsing methods (e.g. Cross-Entropy). (3/6)
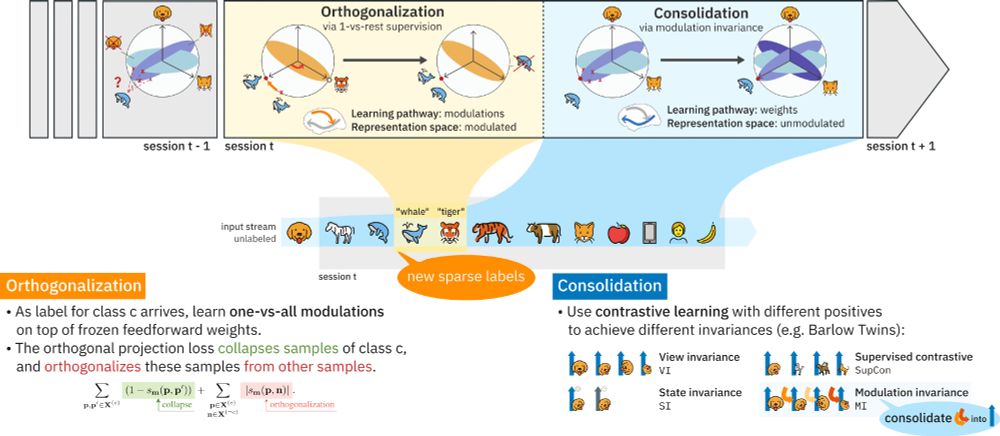
Feedforward weights learn via view-invariant self-supervised learning, mimicking predictive coding. Top-down class modulations, informed by new labels, orthogonalize same-class representations. These are then consolidated into the feedforward pathway through modulation invariance. (2/6)
June 10, 2025 at 1:17 PM
Feedforward weights learn via view-invariant self-supervised learning, mimicking predictive coding. Top-down class modulations, informed by new labels, orthogonalize same-class representations. These are then consolidated into the feedforward pathway through modulation invariance. (2/6)
Feedforward weights learn via view-invariant self-supervised learning, mimicking predictive coding. Top-down class modulations, informed by new labels, orthogonalize same-class representations. These are then consolidated into the feedforward pathway through modulation invariance. (2/6)
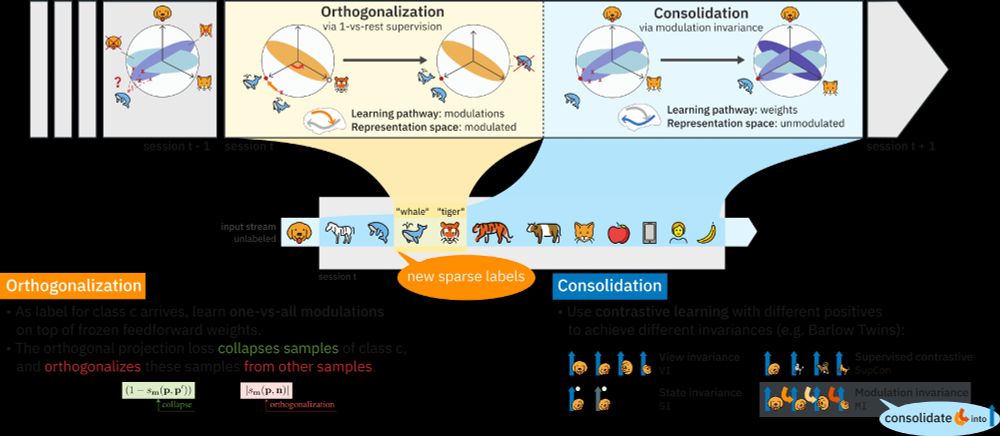
June 10, 2025 at 1:13 PM
Feedforward weights learn via view-invariant self-supervised learning, mimicking predictive coding. Top-down class modulations, informed by new labels, orthogonalize same-class representations. These are then consolidated into the feedforward pathway through modulation invariance. (2/6)