



Kostas Anagnostou
@kostasanagnostou.bsky.social
Lead Rendering Engineer at Playground Games working on Fable. Always open for graphics questions or mentoring people who want to get in the industry. I tweet about graphics mostly. Views my own. Blog: https://interplayoflight.wordpress.com/
Did a quick and dirty implementation of a spatial hash structure to speedup RTAO, ray results are stored in cells indexed by pos/normal/cell size and after storing a few rays occlusion can be queried from the cell instead of raytracing it. 3x faster raytraced AO for that scene with no denoising.
November 11, 2025 at 11:30 PM
Did a quick and dirty implementation of a spatial hash structure to speedup RTAO, ray results are stored in cells indexed by pos/normal/cell size and after storing a few rays occlusion can be queried from the cell instead of raytracing it. 3x faster raytraced AO for that scene with no denoising.
VRS does free up GPU resources though (SM and VGPR), and in such cases, we could run an async compute job over the gbuffer pass to make use of it. 3/3
November 2, 2025 at 4:58 PM
VRS does free up GPU resources though (SM and VGPR), and in such cases, we could run an async compute job over the gbuffer pass to make use of it. 3/3
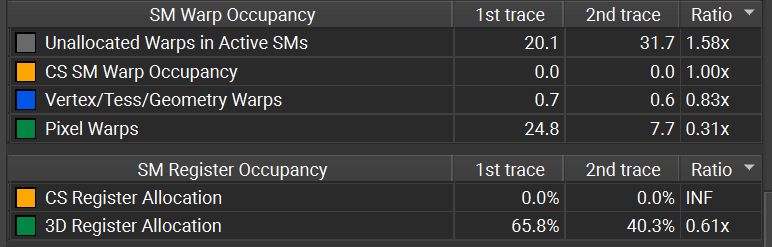
The reason for not doing 75% less work (the 2x2 rate implies) is that VRS always reverts to full rate on geometry edges to preserve them, so it's efficiency depends on triangle size on screen. For that particular pass screenpipe throughput doesn't improve and it's only ~11% faster in the end. 2/3

November 2, 2025 at 4:58 PM
The reason for not doing 75% less work (the 2x2 rate implies) is that VRS always reverts to full rate on geometry edges to preserve them, so it's efficiency depends on triangle size on screen. For that particular pass screenpipe throughput doesn't improve and it's only ~11% faster in the end. 2/3
Finally got around to adding support for (hardware) VRS to the toy engine. Forcing a 2x2 shading rate and comparing in GPU trace, a summary of what is happening for the gbuffer pass (2nd trace VRS on), the GPU is doing the same number of z-tests, while doing about 64% less pixel shader work. 1/3

November 2, 2025 at 4:58 PM
Finally got around to adding support for (hardware) VRS to the toy engine. Forcing a 2x2 shading rate and comparing in GPU trace, a summary of what is happening for the gbuffer pass (2nd trace VRS on), the GPU is doing the same number of z-tests, while doing about 64% less pixel shader work. 1/3
Happy Halloween!

October 31, 2025 at 8:11 PM
Happy Halloween!
Visual Studio's Memory Layout visualiser is a nice way to detect misalignment issues between C++ and HLSL buffers, in this particular case for a structured buffer, where XMMATRIX is 16-byte aligned, while in HLSL it will be a float4x4 with 4-byte alignment, causing errors.

August 10, 2025 at 3:10 PM
Visual Studio's Memory Layout visualiser is a nice way to detect misalignment issues between C++ and HLSL buffers, in this particular case for a structured buffer, where XMMATRIX is 16-byte aligned, while in HLSL it will be a float4x4 with 4-byte alignment, causing errors.
Finally got around to adding something I've been meaning to add to the toy renderer for ages: mesh lods, courtesy of meshoptimizer github.com/zeux/meshopt....
July 15, 2025 at 8:41 PM
Finally got around to adding something I've been meaning to add to the toy renderer for ages: mesh lods, courtesy of meshoptimizer github.com/zeux/meshopt....
Remember kids, the save button used to be a real, physical object.

June 20, 2025 at 5:00 PM
Remember kids, the save button used to be a real, physical object.
It will be a big fight.

May 21, 2025 at 8:03 PM
It will be a big fight.
Hooked up the hierarchical depth i had lying around and did some occlusion culling in the amplification shader, this and per meshlet frustum culling gave a total of ~40% speedup, most of it due to occlusion culling, compared to the vertex shader pipeline with per mesh frustum culling.

March 23, 2025 at 4:21 PM
Hooked up the hierarchical depth i had lying around and did some occlusion culling in the amplification shader, this and per meshlet frustum culling gave a total of ~40% speedup, most of it due to occlusion culling, compared to the vertex shader pipeline with per mesh frustum culling.
Today I was reminded of the importance of understanding the tools you use well. Assimp I added to the toy engine had a PreTransformVertices option which didn't do what I thought, merging meshes using same material into one, very bad for raytracing but also for simpler things like frustum culling.

March 13, 2025 at 9:29 PM
Today I was reminded of the importance of understanding the tools you use well. Assimp I added to the toy engine had a PreTransformVertices option which didn't do what I thought, merging meshes using same material into one, very bad for raytracing but also for simpler things like frustum culling.
Amplification shader support added with meshlet frustum culling. Drops the original vertex shader path cost by 14% and by 35% for a depth only pass (no pixel shader bound). NVidia 3080 laptop, 1080p. Some decent savings there.

March 9, 2025 at 12:00 AM
Amplification shader support added with meshlet frustum culling. Drops the original vertex shader path cost by 14% and by 35% for a depth only pass (no pixel shader bound). NVidia 3080 laptop, 1080p. Some decent savings there.
More mesh as vertex shader replacement costs (no culling). With St Miguel's, 126 tris/64 verts meshlets/128 threadgroup size MS is 6.8% more expensive than VS, 126/64/32 w/looping is 5.6% more but 96/32/32 is 2.1% cheaper. Smaller meshlets can beat VS in that scene (3080 GPU, 1080p, gbuffer pass).

March 1, 2025 at 7:20 PM
More mesh as vertex shader replacement costs (no culling). With St Miguel's, 126 tris/64 verts meshlets/128 threadgroup size MS is 6.8% more expensive than VS, 126/64/32 w/looping is 5.6% more but 96/32/32 is 2.1% cheaper. Smaller meshlets can beat VS in that scene (3080 GPU, 1080p, gbuffer pass).
By the way, if you want a quick way to convert indices to random colours feed the index to your random number generation as a seed. This is a Wes Anderson inspired version of the Bistro, converting material IDs to random colours.

February 23, 2025 at 6:26 PM
By the way, if you want a quick way to convert indices to random colours feed the index to your random number generation as a seed. This is a Wes Anderson inspired version of the Bistro, converting material IDs to random colours.
Upgrading the toy engine to use mesh shaders done.

February 22, 2025 at 11:31 PM
Upgrading the toy engine to use mesh shaders done.
So I started tinkering with mesh shaders and I integrated meshoptimizer (github.com/zeux/meshopt...) to the toy engine to create the meshlets. I thought I'd run the regular meshes through the optimisation pass, minimal effort, 12.5% cheaper gbuffer pass with St Miguel, nice!

February 18, 2025 at 9:47 PM
So I started tinkering with mesh shaders and I integrated meshoptimizer (github.com/zeux/meshopt...) to the toy engine to create the meshlets. I thought I'd run the regular meshes through the optimisation pass, minimal effort, 12.5% cheaper gbuffer pass with St Miguel, nice!
Summary of the potential causes of GPU crashes, from
youtu.be/VaGcs5-W6S4
youtu.be/VaGcs5-W6S4

February 15, 2025 at 11:27 AM
Summary of the potential causes of GPU crashes, from
youtu.be/VaGcs5-W6S4
youtu.be/VaGcs5-W6S4
This is the amount of shader ISA code the compiler produces for a single atan2(). Avoid using it for time critical code.

January 10, 2025 at 4:51 PM
This is the amount of shader ISA code the compiler produces for a single atan2(). Avoid using it for time critical code.

January 6, 2025 at 9:49 PM
Started reading this beauty, although I started gaming on PC, my first job in the industry was with the original Xbox and consoles hold a dear place in my heart.

January 4, 2025 at 12:19 PM
Started reading this beauty, although I started gaming on PC, my first job in the industry was with the original Xbox and consoles hold a dear place in my heart.
TIL: In Compiler Explorer, if you enable comments for the RGA ISA output you get live register analysis which is seemingly produced but hidden by default. You also get some additional info for the DXC output as well (input signatures etc).

January 1, 2025 at 7:17 PM
TIL: In Compiler Explorer, if you enable comments for the RGA ISA output you get live register analysis which is seemingly produced but hidden by default. You also get some additional info for the DXC output as well (input signatures etc).
A nice visualisation why using fps as a measure of performance (improvement) should be avoided. The mapping from ms to fps is not linear and the actual impact on frame time (ms) of an fps increase will depend on where in the graph (X axis) you are (from software.intel.com/content/www/...)

December 31, 2024 at 3:04 PM
A nice visualisation why using fps as a measure of performance (improvement) should be avoided. The mapping from ms to fps is not linear and the actual impact on frame time (ms) of an fps increase will depend on where in the graph (X axis) you are (from software.intel.com/content/www/...)
This happens even when compiler knows that the index varies per thread. To fix this you need to use the NonUniformResourceIndex qualifier. The compiler will then add a waterfall loop to batch wave threads by resource index and ensure that each thread accesses the correct one. 2/3

December 30, 2024 at 3:52 PM
This happens even when compiler knows that the index varies per thread. To fix this you need to use the NonUniformResourceIndex qualifier. The compiler will then add a waterfall loop to batch wave threads by resource index and ensure that each thread accesses the correct one. 2/3
When using arrays of resources/bindless, it's worth paying attention to index divergence. Even if using thread divergent indices, the compiler will use the index from the first active thread to access a resource, for all threads in the wave, which can cause hard to find bugs 1/3

December 30, 2024 at 3:52 PM
When using arrays of resources/bindless, it's worth paying attention to index divergence. Even if using thread divergent indices, the compiler will use the index from the first active thread to access a resource, for all threads in the wave, which can cause hard to find bugs 1/3
When you spend all your budget on NPCs and can't afford to render the whole Eiffel tower.

December 30, 2024 at 11:00 AM
When you spend all your budget on NPCs and can't afford to render the whole Eiffel tower.