



Alexander Kolesnikov
@kolesnikov.ch
The full answer is probably very complex.
I really like the "function matching" angle we discovered (or rediscovered) in one of our papers that partially demystifies distillation for me: arxiv.org/abs/2106.05237
I really like the "function matching" angle we discovered (or rediscovered) in one of our papers that partially demystifies distillation for me: arxiv.org/abs/2106.05237

Knowledge distillation: A good teacher is patient and consistent
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we addres...
arxiv.org
December 21, 2024 at 5:39 PM
The full answer is probably very complex.
I really like the "function matching" angle we discovered (or rediscovered) in one of our papers that partially demystifies distillation for me: arxiv.org/abs/2106.05237
I really like the "function matching" angle we discovered (or rediscovered) in one of our papers that partially demystifies distillation for me: arxiv.org/abs/2106.05237
Also check out this concurrent work that is very similar in spirit to Jet and JetFormer, which proposes autoregressive ViT-powered normalizing flows (NFs): x.com/zhaisf/statu...
x.com
x.com
December 20, 2024 at 2:39 PM
Also check out this concurrent work that is very similar in spirit to Jet and JetFormer, which proposes autoregressive ViT-powered normalizing flows (NFs): x.com/zhaisf/statu...
December 20, 2024 at 2:39 PM
Final note: we see the Jet model as a powerful tool and a building block for advanced generative models, like JetFormer bsky.app/profile/mtsc..., and not as a standalone competitive generative model.

Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 20, 2024 at 2:39 PM
Final note: we see the Jet model as a powerful tool and a building block for advanced generative models, like JetFormer bsky.app/profile/mtsc..., and not as a standalone competitive generative model.
Check out the paper for more juicy details: arxiv.org/abs/2412.15129.
My favorite mini-insight is how implicit half-precision matrix multiplications (with float32 accumulation) can 'eat' entropy and lead to an overly optimistic, flawed objective and evaluations.
My favorite mini-insight is how implicit half-precision matrix multiplications (with float32 accumulation) can 'eat' entropy and lead to an overly optimistic, flawed objective and evaluations.

Jet: A Modern Transformer-Based Normalizing Flow
In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute...
arxiv.org
December 20, 2024 at 2:39 PM
Check out the paper for more juicy details: arxiv.org/abs/2412.15129.
My favorite mini-insight is how implicit half-precision matrix multiplications (with float32 accumulation) can 'eat' entropy and lead to an overly optimistic, flawed objective and evaluations.
My favorite mini-insight is how implicit half-precision matrix multiplications (with float32 accumulation) can 'eat' entropy and lead to an overly optimistic, flawed objective and evaluations.
We release full Jet code (including training) in big_vision repo: github.com/google-resea....

Add "Jet: A Modern Transformer-Based Normalizing Flow" by andresusanopinto · Pull Request #143 · google-research/big_vision
Implementation used in https://arxiv.org/abs/2412.15129
There are a few other small fixes in big_vision codebase.
github.com
December 20, 2024 at 2:39 PM
We release full Jet code (including training) in big_vision repo: github.com/google-resea....
When trained on 'small' data, such as ImageNet-1k, overfitting occurs.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.


December 20, 2024 at 2:39 PM
When trained on 'small' data, such as ImageNet-1k, overfitting occurs.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
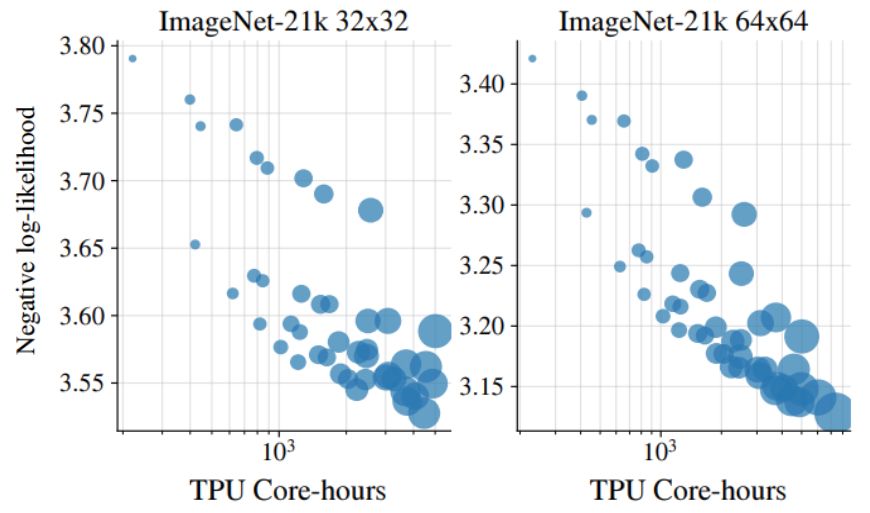
We observe robust performance improvements with compute scaling, showing behavior similar to classical scaling laws.
These are the results of varying the Jet model size when training on ImageNet-21k images:
These are the results of varying the Jet model size when training on ImageNet-21k images:
December 20, 2024 at 2:39 PM
We observe robust performance improvements with compute scaling, showing behavior similar to classical scaling laws.
These are the results of varying the Jet model size when training on ImageNet-21k images:
These are the results of varying the Jet model size when training on ImageNet-21k images:
Our main contribution is a very straightforward design: Jet is just repeated affine coupling layers with ViT inside. We show that many standard components are not needed with our simple design:
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise

December 20, 2024 at 2:39 PM
Our main contribution is a very straightforward design: Jet is just repeated affine coupling layers with ViT inside. We show that many standard components are not needed with our simple design:
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
Here it is: arxiv.org/abs/2412.15129
Jet: A Modern Transformer-Based Normalizing Flow
In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute...
arxiv.org
December 20, 2024 at 2:33 PM
Here it is: arxiv.org/abs/2412.15129
JetFormer product of endless and heated (but friendly) arguing and discussions with @mtschannen.bsky.social
and @asusanopinto.bsky.social.
Very excited about this model due to its potential to unify multimodal learning with a simple and universal end-to-end approach.
and @asusanopinto.bsky.social.
Very excited about this model due to its potential to unify multimodal learning with a simple and universal end-to-end approach.
December 2, 2024 at 5:19 PM
JetFormer product of endless and heated (but friendly) arguing and discussions with @mtschannen.bsky.social
and @asusanopinto.bsky.social.
Very excited about this model due to its potential to unify multimodal learning with a simple and universal end-to-end approach.
and @asusanopinto.bsky.social.
Very excited about this model due to its potential to unify multimodal learning with a simple and universal end-to-end approach.
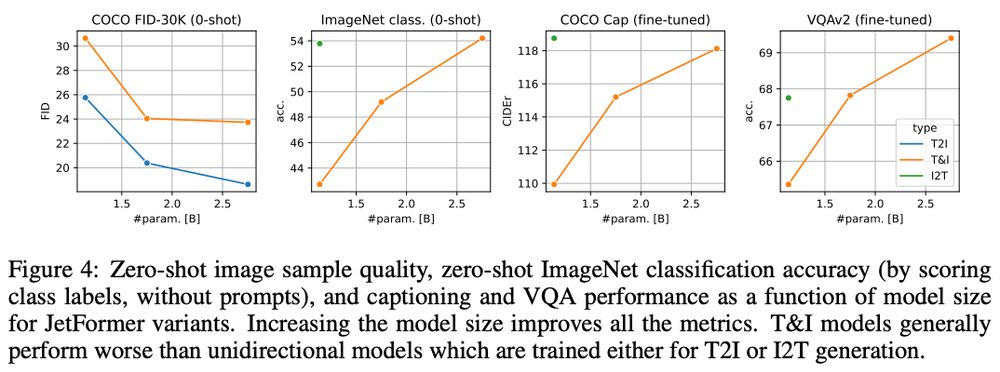
We evaluate JetFormer potential to model large-scale multimodal image+text data and do image-to-text, text-to-image and VQA tasks, and get rather encouraging results.
December 2, 2024 at 5:19 PM
We evaluate JetFormer potential to model large-scale multimodal image+text data and do image-to-text, text-to-image and VQA tasks, and get rather encouraging results.
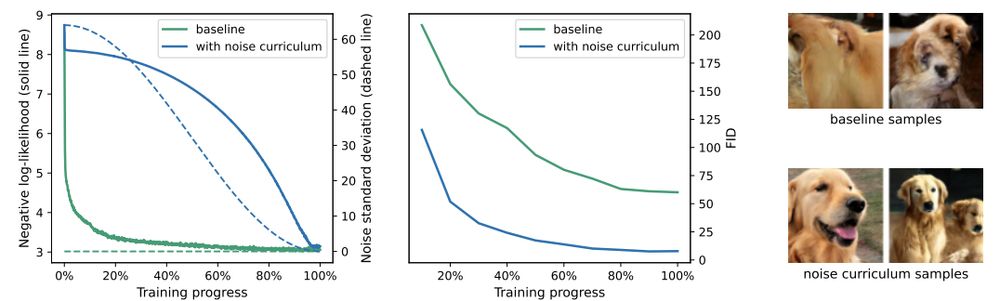
We also present novel data augmentation: "noise curriculum". It helps a pure NLL model to focus on high-level image details.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
December 2, 2024 at 5:19 PM
We also present novel data augmentation: "noise curriculum". It helps a pure NLL model to focus on high-level image details.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
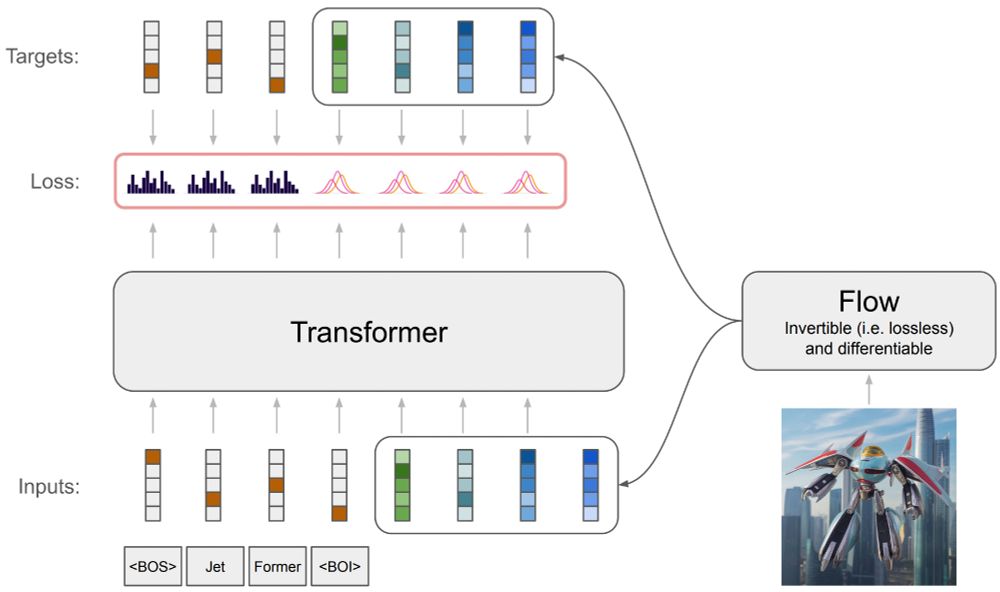
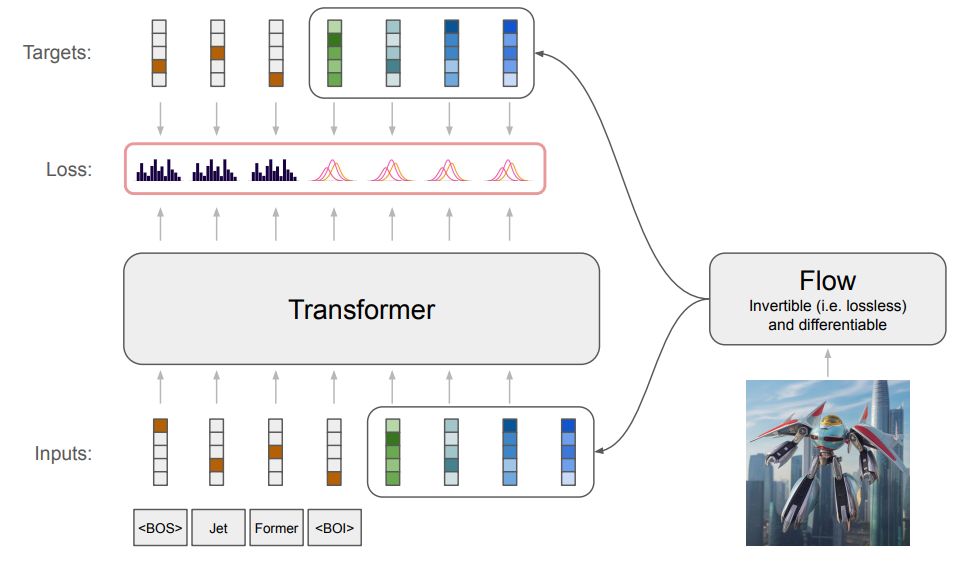
JetFormer is just an autoregressive transformer, trained end-to-end in one go, with no pretrained image encoders/quantizers.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
December 2, 2024 at 5:19 PM
JetFormer is just an autoregressive transformer, trained end-to-end in one go, with no pretrained image encoders/quantizers.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.