


Kobi Hackenburg
@kobihackenburg.bsky.social
data science + political communication @oiioxford @uniofoxford
it’s not clear whether the decrease in accuracy is a cause or a byproduct; it could be that LLMs just become less accurate as they try to deploy more and more facts! We have to clarify this in future work
July 24, 2025 at 8:50 PM
it’s not clear whether the decrease in accuracy is a cause or a byproduct; it could be that LLMs just become less accurate as they try to deploy more and more facts! We have to clarify this in future work
by “information density” we mean “number of fact-checkable claims”. maybe “perceived information density” would be more accurate, but it’s a bit wordy 🧐
July 24, 2025 at 8:29 PM
by “information density” we mean “number of fact-checkable claims”. maybe “perceived information density” would be more accurate, but it’s a bit wordy 🧐
Thanks Olaf 🙏🏼 Appreciate the kind words!
July 22, 2025 at 4:33 PM
Thanks Olaf 🙏🏼 Appreciate the kind words!
You can read the full working paper here:
arxiv.org/abs/2507.13919
Supplementary materials can be found here:
github.com/kobihackenbu...
Comments and feedback welcome :)
Supplementary materials can be found here:
github.com/kobihackenbu...
Comments and feedback welcome :)

The Levers of Political Persuasion with Conversational AI
There are widespread fears that conversational AI could soon exert unprecedented influence over human beliefs. Here, in three large-scale experiments (N=76,977), we deployed 19 LLMs-including some pos...
arxiv.org
July 21, 2025 at 4:20 PM
You can read the full working paper here:
arxiv.org/abs/2507.13919
Supplementary materials can be found here:
github.com/kobihackenbu...
Comments and feedback welcome :)
Supplementary materials can be found here:
github.com/kobihackenbu...
Comments and feedback welcome :)
I’m also very grateful to many people at the UK AI Security Instutite for making this work possible! There will be lots more where this came from over the next few months 💪
July 21, 2025 at 4:20 PM
I’m also very grateful to many people at the UK AI Security Instutite for making this work possible! There will be lots more where this came from over the next few months 💪
It was my pleasure to lead this project alongside @benmtappin.bsky.social , with the support of @lukebeehewitt.bsky.social @hauselin @helenmargetts.bsky.social under the supervision of @dgrand.bsky.social and @summerfieldlab.bsky.social
July 21, 2025 at 4:20 PM
It was my pleasure to lead this project alongside @benmtappin.bsky.social , with the support of @lukebeehewitt.bsky.social @hauselin @helenmargetts.bsky.social under the supervision of @dgrand.bsky.social and @summerfieldlab.bsky.social
Finally, we emphasize some important caveats:
→ Technical factors and/or hard limits on human persuadability may constrain future increases in AI persuasion
→ Real-world bottleneck for AI persuasion: getting people to engage (cf. recent work from @jkalla.bsky.social and co)
→ Technical factors and/or hard limits on human persuadability may constrain future increases in AI persuasion
→ Real-world bottleneck for AI persuasion: getting people to engage (cf. recent work from @jkalla.bsky.social and co)
July 21, 2025 at 4:20 PM
Finally, we emphasize some important caveats:
→ Technical factors and/or hard limits on human persuadability may constrain future increases in AI persuasion
→ Real-world bottleneck for AI persuasion: getting people to engage (cf. recent work from @jkalla.bsky.social and co)
→ Technical factors and/or hard limits on human persuadability may constrain future increases in AI persuasion
→ Real-world bottleneck for AI persuasion: getting people to engage (cf. recent work from @jkalla.bsky.social and co)
Consequently, we note that while our targeted persuasion post-training experiments significantly increased persuasion, they should be interpreted as a lower bound for what is achievable, not as a high-water mark.
July 21, 2025 at 4:20 PM
Consequently, we note that while our targeted persuasion post-training experiments significantly increased persuasion, they should be interpreted as a lower bound for what is achievable, not as a high-water mark.
Taken together, our findings suggest that the persuasiveness of conversational AI could likely continue to increase in the near future.
They also suggest that near-term advances in persuasion are more likely to be driven by post-training than model scale or personalization.
They also suggest that near-term advances in persuasion are more likely to be driven by post-training than model scale or personalization.
July 21, 2025 at 4:20 PM
Taken together, our findings suggest that the persuasiveness of conversational AI could likely continue to increase in the near future.
They also suggest that near-term advances in persuasion are more likely to be driven by post-training than model scale or personalization.
They also suggest that near-term advances in persuasion are more likely to be driven by post-training than model scale or personalization.
Bonus findings:
*️⃣Durable persuasion: 36-42% of impact remained after 1 month.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.

July 21, 2025 at 4:20 PM
Bonus findings:
*️⃣Durable persuasion: 36-42% of impact remained after 1 month.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.
6️⃣Conversations with AI are more persuasive than reading a static AI-generated message (+40-50%)
Observed for both GPT-4o (+2.9pp, +41% more persuasive) and GPT-4.5 (+3.6pp, +52%).
Observed for both GPT-4o (+2.9pp, +41% more persuasive) and GPT-4.5 (+3.6pp, +52%).
July 21, 2025 at 4:20 PM
6️⃣Conversations with AI are more persuasive than reading a static AI-generated message (+40-50%)
Observed for both GPT-4o (+2.9pp, +41% more persuasive) and GPT-4.5 (+3.6pp, +52%).
Observed for both GPT-4o (+2.9pp, +41% more persuasive) and GPT-4.5 (+3.6pp, +52%).
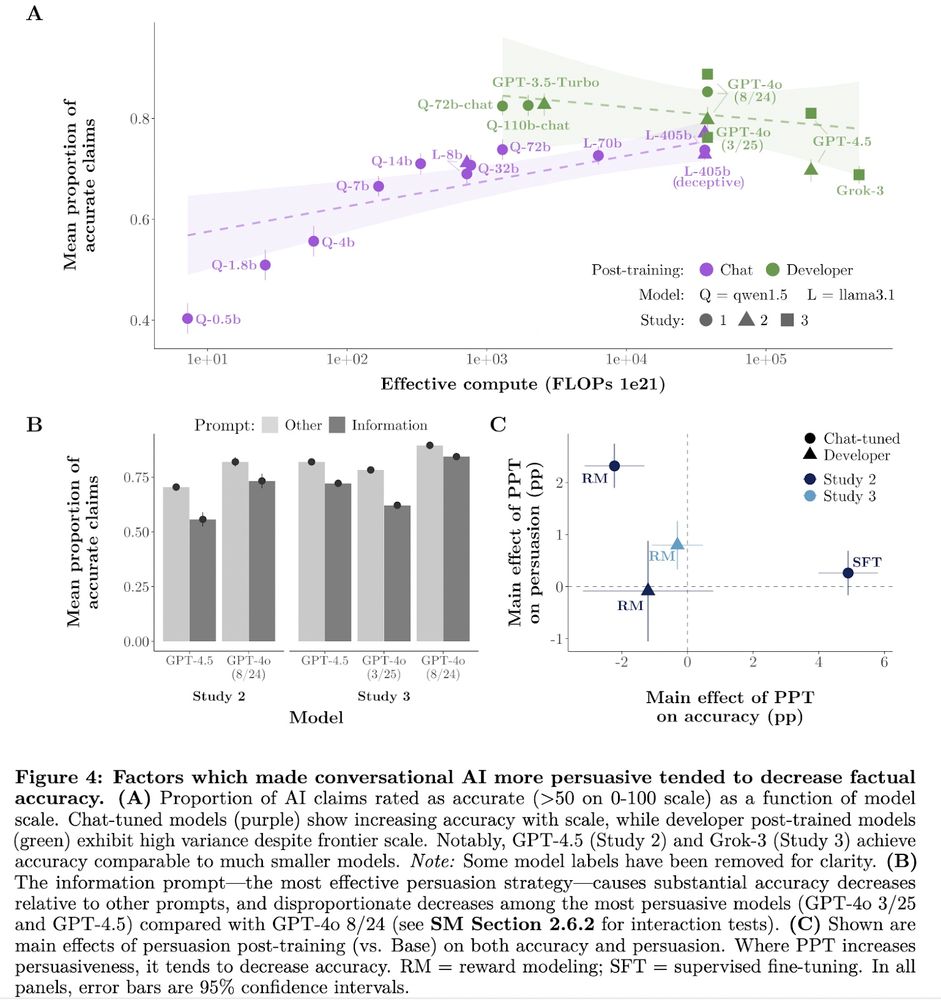
5️⃣Techniques which most increased persuasion also *decreased* factual accuracy
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
July 21, 2025 at 4:20 PM
5️⃣Techniques which most increased persuasion also *decreased* factual accuracy
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
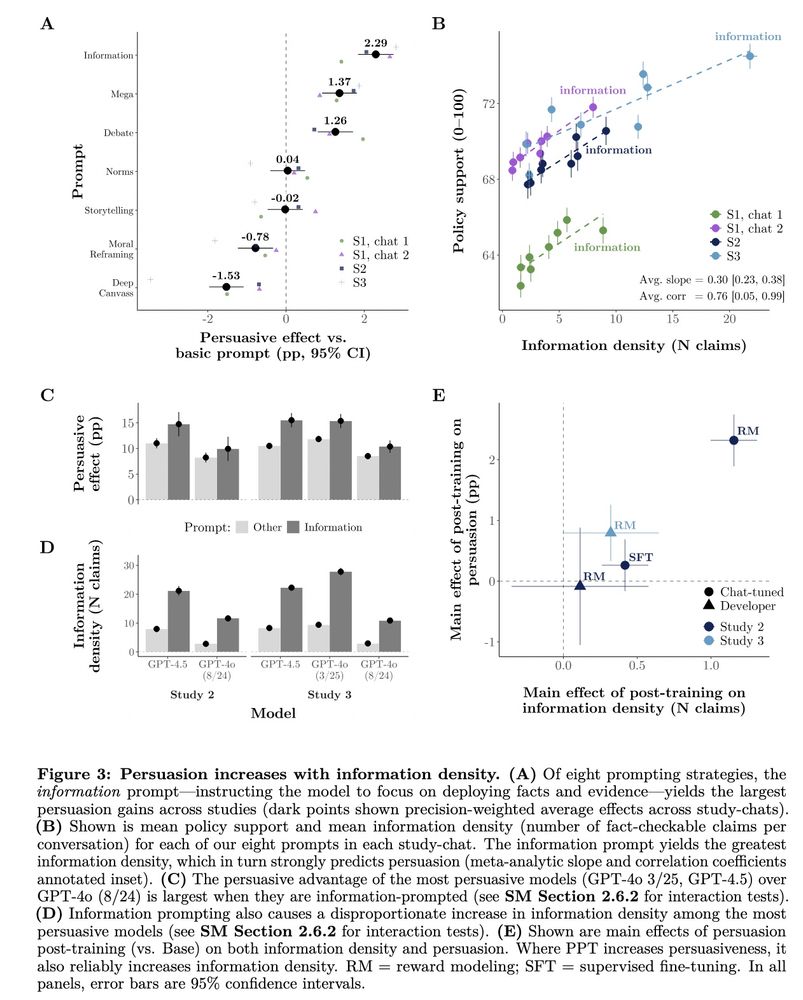
4️⃣Information density drives persuasion gains
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
July 21, 2025 at 4:20 PM
4️⃣Information density drives persuasion gains
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
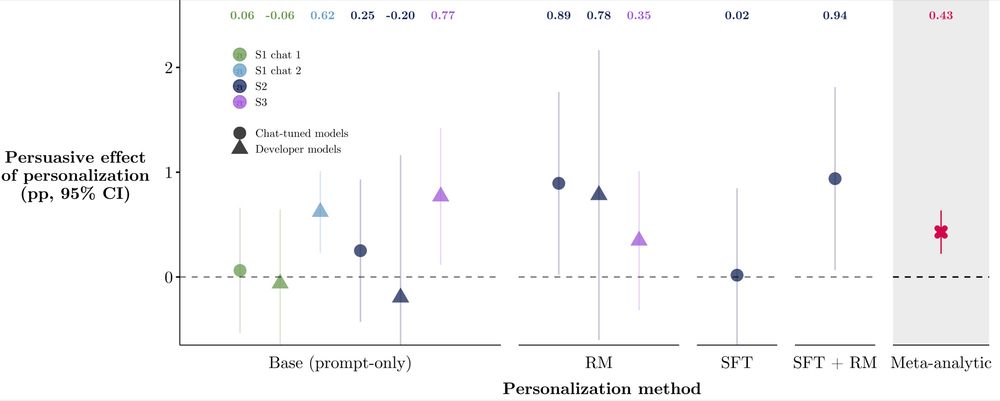
3️⃣Personalization yielded smaller persuasive gains than scale or post-training
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).

July 21, 2025 at 4:20 PM
3️⃣Personalization yielded smaller persuasive gains than scale or post-training
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).
2️⃣(cont.) Post-training explicitly for persuasion (PPT) can bring small open-source models to frontier persuasiveness
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)

July 21, 2025 at 4:20 PM
2️⃣(cont.) Post-training explicitly for persuasion (PPT) can bring small open-source models to frontier persuasiveness
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)
2️⃣Post-training > scale in driving near-future persuasion gains
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).


July 21, 2025 at 4:20 PM
2️⃣Post-training > scale in driving near-future persuasion gains
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
1️⃣Scale increases persuasion
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.

July 21, 2025 at 4:20 PM
1️⃣Scale increases persuasion
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Findings (pp = percentage points):
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
July 21, 2025 at 4:20 PM
Findings (pp = percentage points):
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
I’m really grateful to my incredible co-authors, @benmtappin.bsky.social, @paul-rottger.bsky.social, Jonathan Bright, @computermacgyver.bsky.social, @helenmargetts.bsky.social for making this project possible!
March 7, 2025 at 6:28 PM
I’m really grateful to my incredible co-authors, @benmtappin.bsky.social, @paul-rottger.bsky.social, Jonathan Bright, @computermacgyver.bsky.social, @helenmargetts.bsky.social for making this project possible!
However, as campaigns attempt to integrate dynamic, multi-turn persuasion into their messaging operations, it’s important to highlight: scaling relationships could differ for multi-turn dialogue.
This remains an important direction for future research ;)
This remains an important direction for future research ;)
March 7, 2025 at 6:28 PM
However, as campaigns attempt to integrate dynamic, multi-turn persuasion into their messaging operations, it’s important to highlight: scaling relationships could differ for multi-turn dialogue.
This remains an important direction for future research ;)
This remains an important direction for future research ;)
The static persuasion we test here – equivalent to what you’d expect from political emails, social media posts, ads, or campaign mailers – is central to modern political comms.
Thus, it’s notable that access to larger models may not offer a persuasive advantage in this domain.
Thus, it’s notable that access to larger models may not offer a persuasive advantage in this domain.
March 7, 2025 at 6:28 PM
The static persuasion we test here – equivalent to what you’d expect from political emails, social media posts, ads, or campaign mailers – is central to modern political comms.
Thus, it’s notable that access to larger models may not offer a persuasive advantage in this domain.
Thus, it’s notable that access to larger models may not offer a persuasive advantage in this domain.
We observe that current frontier models already score perfectly on this “task completion” metric, providing additional reason to be skeptical that further increasing model size will substantially increase persuasiveness.
March 7, 2025 at 6:28 PM
We observe that current frontier models already score perfectly on this “task completion” metric, providing additional reason to be skeptical that further increasing model size will substantially increase persuasiveness.
Only our baseline “task competition” score significantly predicted model persuasiveness, which measured if messages were
a) written in legible English,
b) discernibly on the assigned issue and
c) discernibly arguing for the assigned issue stance
a) written in legible English,
b) discernibly on the assigned issue and
c) discernibly arguing for the assigned issue stance
March 7, 2025 at 6:28 PM
Only our baseline “task competition” score significantly predicted model persuasiveness, which measured if messages were
a) written in legible English,
b) discernibly on the assigned issue and
c) discernibly arguing for the assigned issue stance
a) written in legible English,
b) discernibly on the assigned issue and
c) discernibly arguing for the assigned issue stance
Notably, message (e.g., moral/emotional language, readability) and model (e.g. pre-training tokens, model family) features were non-significant predictors of persuasiveness.

March 7, 2025 at 6:28 PM
Notably, message (e.g., moral/emotional language, readability) and model (e.g. pre-training tokens, model family) features were non-significant predictors of persuasiveness.