



Kobi Hackenburg
@kobihackenburg.bsky.social
data science + political communication @oiioxford @uniofoxford
Bonus findings:
*️⃣Durable persuasion: 36-42% of impact remained after 1 month.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.

July 21, 2025 at 4:20 PM
Bonus findings:
*️⃣Durable persuasion: 36-42% of impact remained after 1 month.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt.
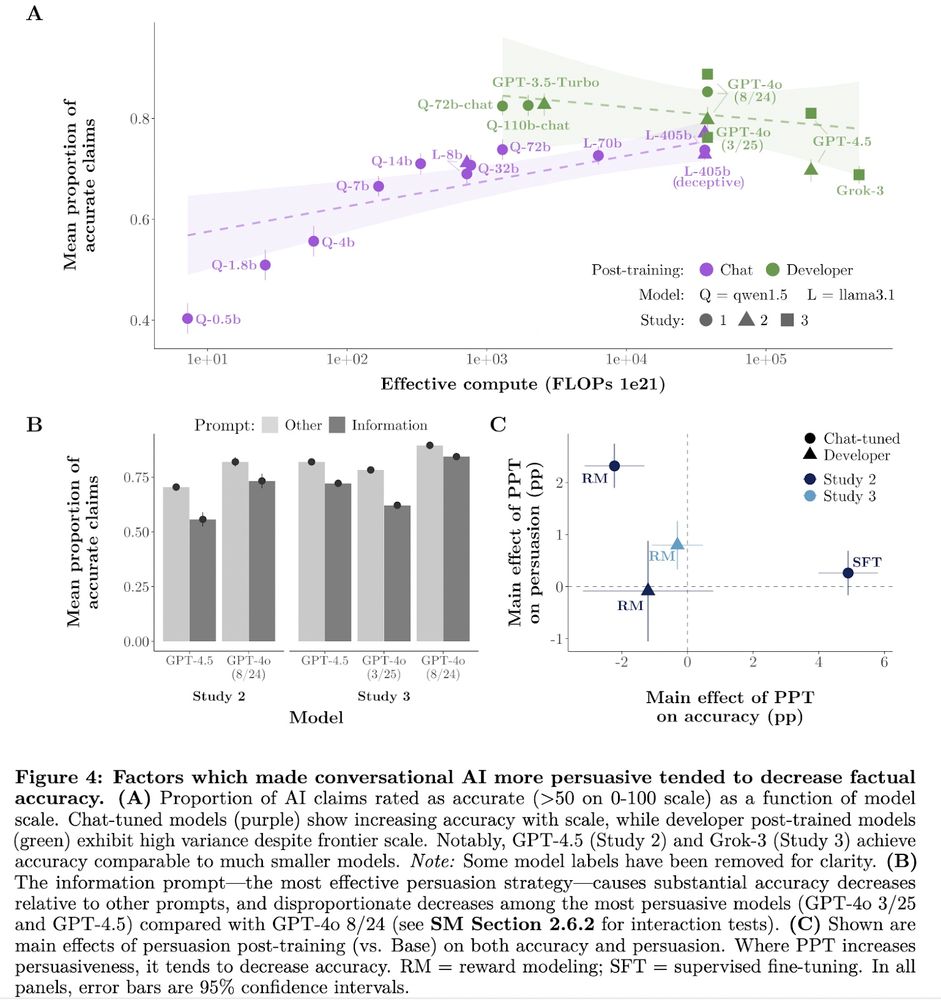
5️⃣Techniques which most increased persuasion also *decreased* factual accuracy
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
July 21, 2025 at 4:20 PM
5️⃣Techniques which most increased persuasion also *decreased* factual accuracy
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
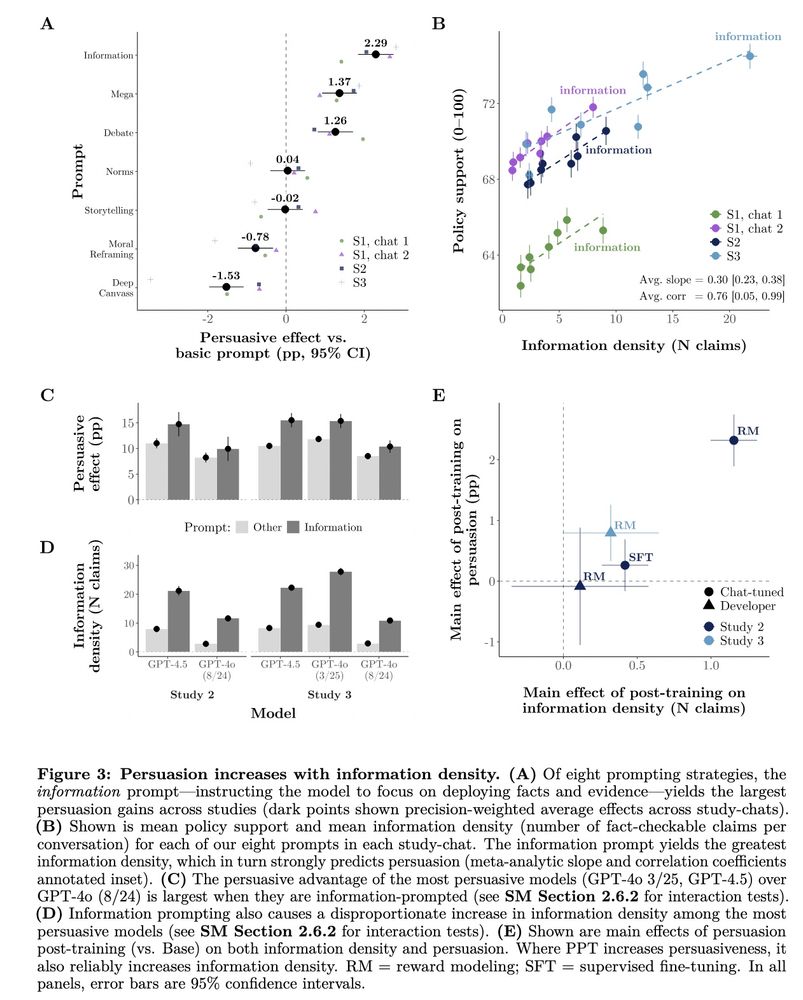
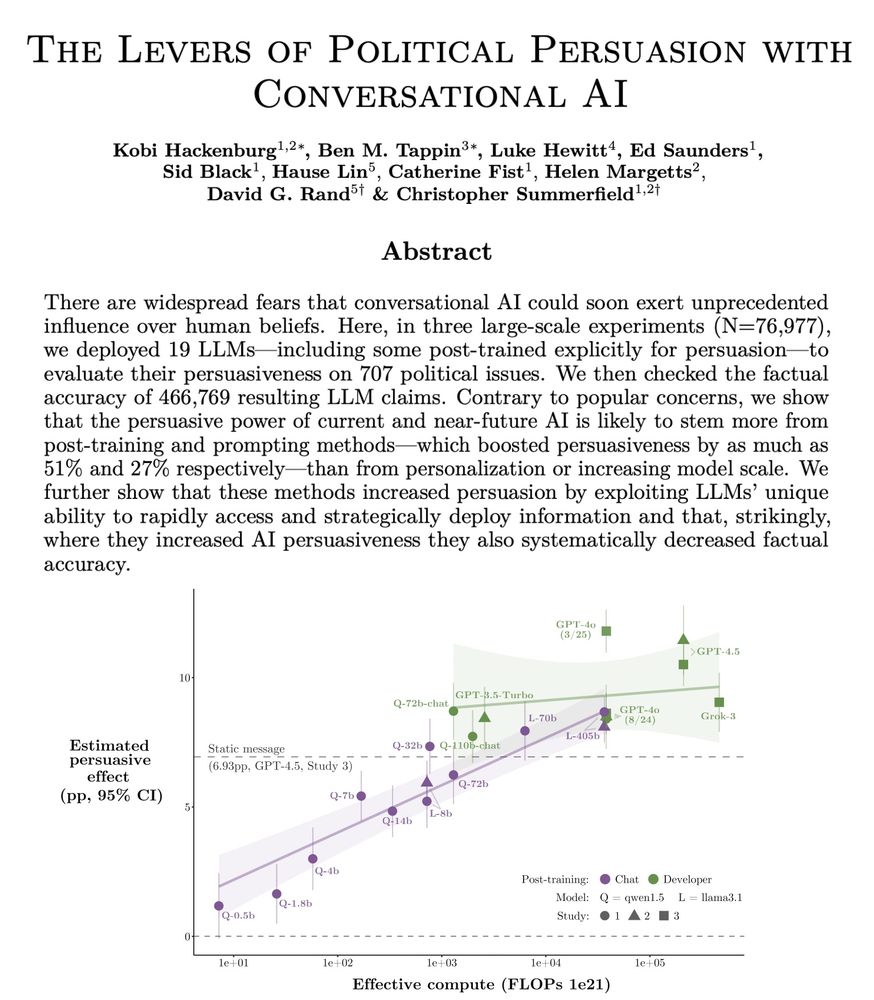
4️⃣Information density drives persuasion gains
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
July 21, 2025 at 4:20 PM
4️⃣Information density drives persuasion gains
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
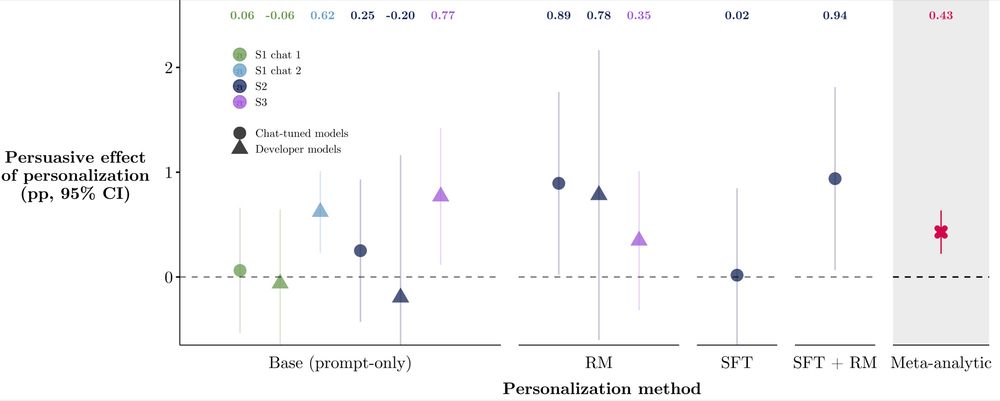
3️⃣Personalization yielded smaller persuasive gains than scale or post-training
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).

July 21, 2025 at 4:20 PM
3️⃣Personalization yielded smaller persuasive gains than scale or post-training
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.).
Held for simple and sophisticated personalization; prompt-based, fine-tuning, and reward modeling (all <1pp).
2️⃣(cont.) Post-training explicitly for persuasion (PPT) can bring small open-source models to frontier persuasiveness
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)

July 21, 2025 at 4:20 PM
2️⃣(cont.) Post-training explicitly for persuasion (PPT) can bring small open-source models to frontier persuasiveness
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. (PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (+0.6pp on avg.).)
2️⃣Post-training > scale in driving near-future persuasion gains
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).


July 21, 2025 at 4:20 PM
2️⃣Post-training > scale in driving near-future persuasion gains
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
1️⃣Scale increases persuasion
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.

July 21, 2025 at 4:20 PM
1️⃣Scale increases persuasion
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Findings (pp = percentage points):
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
July 21, 2025 at 4:20 PM
Findings (pp = percentage points):
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, as much as +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
Today (w/ @ox.ac.uk @stanford @MIT @LSE) we’re sharing the results of the largest AI persuasion experiments to date: 76k participants, 19 LLMs, 707 political issues.
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more!
🧵:
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more!
🧵:
July 21, 2025 at 4:20 PM
Today (w/ @ox.ac.uk @stanford @MIT @LSE) we’re sharing the results of the largest AI persuasion experiments to date: 76k participants, 19 LLMs, 707 political issues.
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more!
🧵:
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more!
🧵:
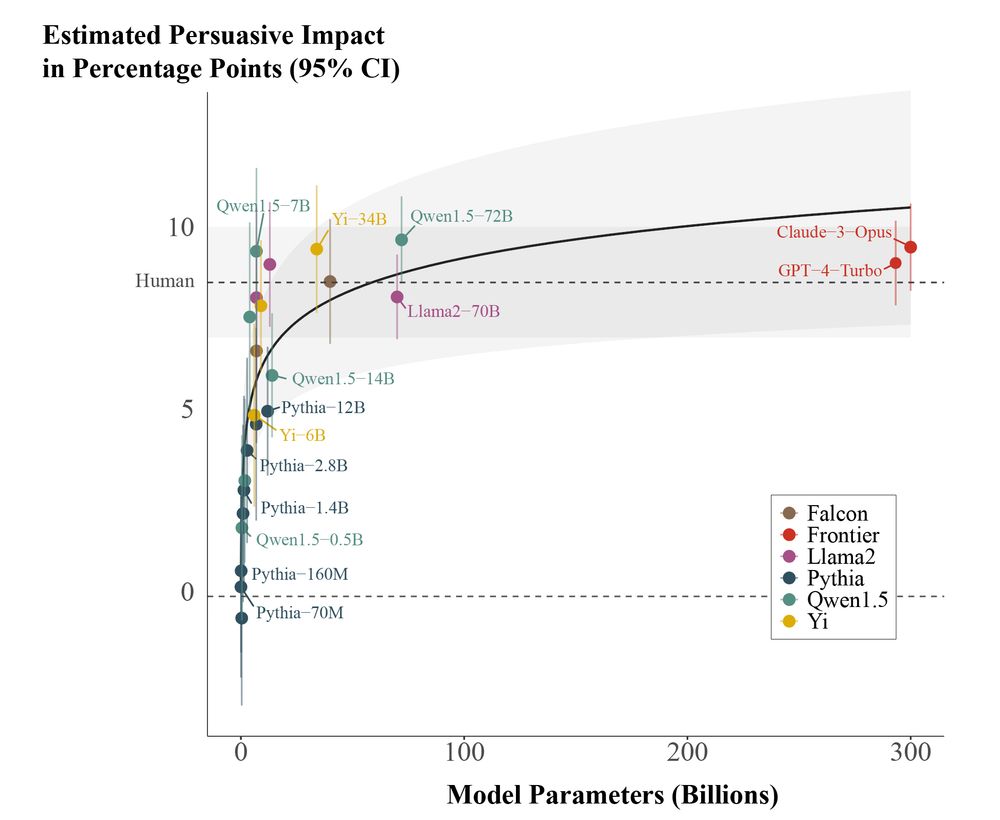
Notably, message (e.g., moral/emotional language, readability) and model (e.g. pre-training tokens, model family) features were non-significant predictors of persuasiveness.

March 7, 2025 at 6:28 PM
Notably, message (e.g., moral/emotional language, readability) and model (e.g. pre-training tokens, model family) features were non-significant predictors of persuasiveness.
The scaling relationship we found to be most consistent with the data was a log-logistic function, indicating sharp diminishing returns to model size.

March 7, 2025 at 6:28 PM
The scaling relationship we found to be most consistent with the data was a log-logistic function, indicating sharp diminishing returns to model size.
📈Out today in @PNASNews!📈
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:

March 7, 2025 at 6:28 PM
📈Out today in @PNASNews!📈
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵: