




Erik Arakelyan
@kirekara.bsky.social
Researcher @Nvidia | PhD from @CopeNLU | Formerly doing magic at @Amazon Alexa AI and @ARM. ML MSc graduate from @UCL. Research is the name of the game. ᓚᘏᗢ
http://osoblanco.github.io
http://osoblanco.github.io
The last round of applause goes to the @copenlu.bsky.social lab, @ucph.bsky.social and my amazing colleagues and friends there for the heartwarming, inspiring and fun times we had ♥️ to everyone involved in this journey goes my deepest sympathy ♥️♥️
April 3, 2025 at 1:00 PM
The last round of applause goes to the @copenlu.bsky.social lab, @ucph.bsky.social and my amazing colleagues and friends there for the heartwarming, inspiring and fun times we had ♥️ to everyone involved in this journey goes my deepest sympathy ♥️♥️
I also want to thank the fantastic PhD committee,
@barbaraplank.bsky.social , Ivan Titov and
@delliott.bsky.social sky.social, for their deep, thought-provoking and insightful questions and analysis.
@barbaraplank.bsky.social , Ivan Titov and
@delliott.bsky.social sky.social, for their deep, thought-provoking and insightful questions and analysis.
April 3, 2025 at 12:58 PM
I also want to thank the fantastic PhD committee,
@barbaraplank.bsky.social , Ivan Titov and
@delliott.bsky.social sky.social, for their deep, thought-provoking and insightful questions and analysis.
@barbaraplank.bsky.social , Ivan Titov and
@delliott.bsky.social sky.social, for their deep, thought-provoking and insightful questions and analysis.
What i secretly desire is even stricter than grounding with RAG. Maybe have a big Knowledge Graph for grounding and use a good neural link predictor for confirming if the facts are correct. This covers factuality, we also would like deductive and analytic reasoning similar to a theorem prover.
November 19, 2024 at 10:01 AM
What i secretly desire is even stricter than grounding with RAG. Maybe have a big Knowledge Graph for grounding and use a good neural link predictor for confirming if the facts are correct. This covers factuality, we also would like deductive and analytic reasoning similar to a theorem prover.
The results consistently show that, over each model, traces that lead to correct answers had a higher percentage of unique emergent facts and overlap in the relations used between the code and search, while the portion of underutilized relations was lower.🤔🤔
November 8, 2024 at 2:20 PM
The results consistently show that, over each model, traces that lead to correct answers had a higher percentage of unique emergent facts and overlap in the relations used between the code and search, while the portion of underutilized relations was lower.🤔🤔
By comparing relations in code with those in search traces, we measure emergent hallucinations and unused relations, highlighting areas of sub-optimal reasoning. We also assess the uniqueness of emergent facts per inference hop, indicating the extent of problem-space exploration.

November 8, 2024 at 2:19 PM
By comparing relations in code with those in search traces, we measure emergent hallucinations and unused relations, highlighting areas of sub-optimal reasoning. We also assess the uniqueness of emergent facts per inference hop, indicating the extent of problem-space exploration.
We found out that there is a strong correlation between the search faithfulness towards the code and model performance across all of the models.

November 8, 2024 at 2:18 PM
We found out that there is a strong correlation between the search faithfulness towards the code and model performance across all of the models.
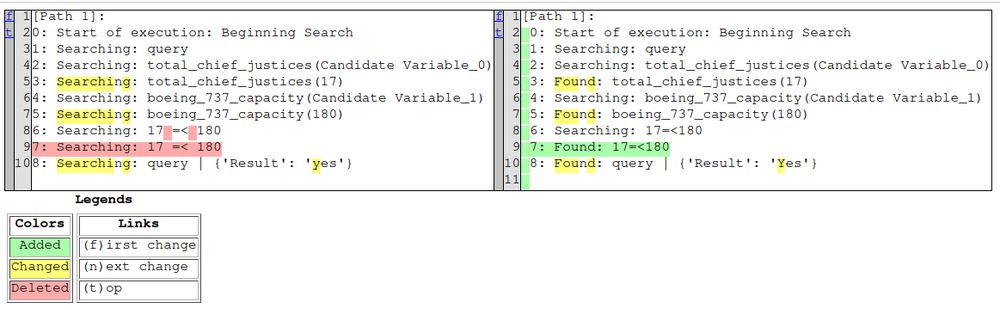
Using FLARE also allows the evaluation of faithfulness of the completed search w.r.t. the defined facts, relations, and search logic (taken from Prolog). We simply compare (ROUGE-Lsum) the simulated search with the actual code execution when available.
November 8, 2024 at 2:17 PM
Using FLARE also allows the evaluation of faithfulness of the completed search w.r.t. the defined facts, relations, and search logic (taken from Prolog). We simply compare (ROUGE-Lsum) the simulated search with the actual code execution when available.
The method boosts the performance of various LLMs at different scales (8B -> 100B+) compared to CoT and Faithful CoT on various Mathematical, Multi-Hop, and Relation Inference tasks.

November 8, 2024 at 2:16 PM
The method boosts the performance of various LLMs at different scales (8B -> 100B+) compared to CoT and Faithful CoT on various Mathematical, Multi-Hop, and Relation Inference tasks.
LLM formalizes the tasks using Prolog into facts, relations, and search logic and simulates exhaustive search by iteratively exploring the problem space with backtracking.

November 8, 2024 at 2:15 PM
LLM formalizes the tasks using Prolog into facts, relations, and search logic and simulates exhaustive search by iteratively exploring the problem space with backtracking.
Reposted by Erik Arakelyan

Hey! 🙂 we analysed what happens during pre-training, and for causal LMs, intra-document causal masking helps quite a bit both in terms of pre-training dynamics and downstream task performance: arxiv.org/abs/2402.13991

Analysing The Impact of Sequence Composition on Language Model Pre-Training
Most language model pre-training frameworks concatenate multiple documents into fixed-length sequences and use causal masking to compute the likelihood of each token given its context; this strategy i...
arxiv.org
November 8, 2024 at 9:05 AM
Hey! 🙂 we analysed what happens during pre-training, and for causal LMs, intra-document causal masking helps quite a bit both in terms of pre-training dynamics and downstream task performance: arxiv.org/abs/2402.13991