



Karen Ullrich (s/h) ✈️ COLM
@karen-ullrich.bsky.social
Research scientist at FAIR NY ❤️ LLMs + Information Theory. Previously, PhD at UoAmsterdam, intern at DeepMind + MSRC.

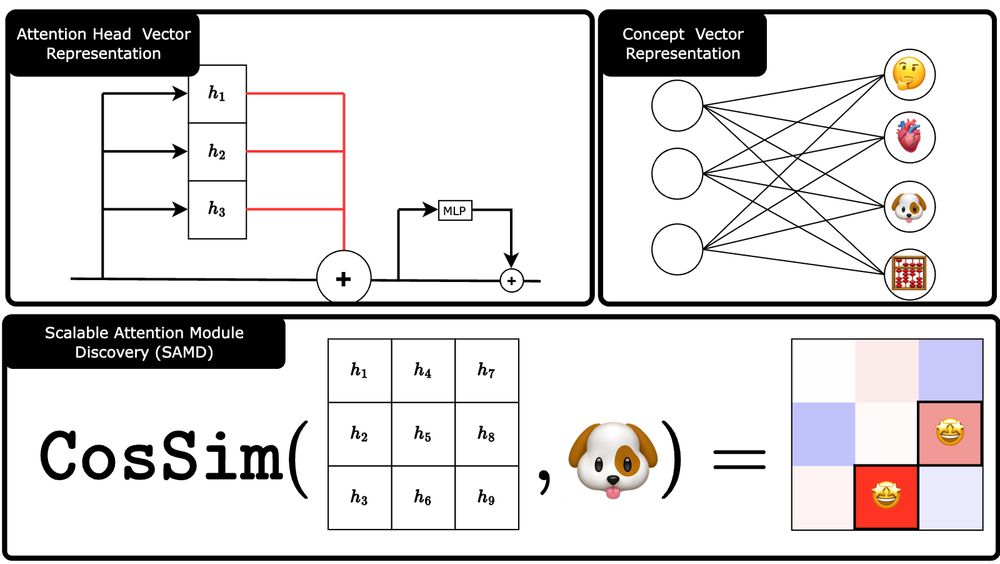
Plus, we generate importance maps showing where in the transformer the concept is encoded — providing interpretable insights into model internals.
July 8, 2025 at 1:49 PM
Plus, we generate importance maps showing where in the transformer the concept is encoded — providing interpretable insights into model internals.
SAMI: Diminishes or amplifies these modules to control the concept's influence
With SAMI, we can scale the importance of these modules — either amplifying or suppressing specific concepts.
With SAMI, we can scale the importance of these modules — either amplifying or suppressing specific concepts.

July 8, 2025 at 1:49 PM
SAMI: Diminishes or amplifies these modules to control the concept's influence
With SAMI, we can scale the importance of these modules — either amplifying or suppressing specific concepts.
With SAMI, we can scale the importance of these modules — either amplifying or suppressing specific concepts.
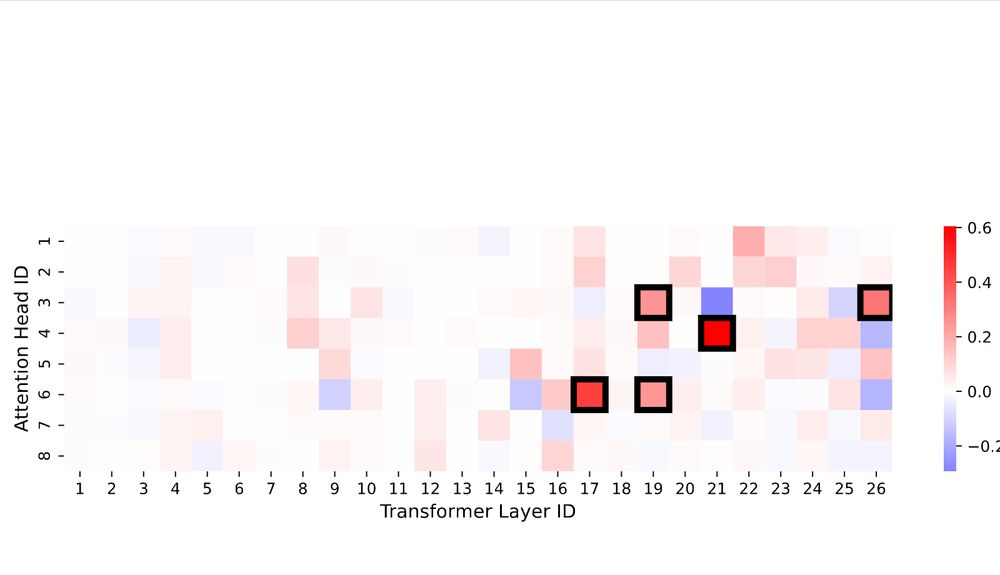
SAMD: Finds the attention heads most correlated with a concept
Using SAMD, we find that only a few attention heads are crucial for a wide range of concepts—confirming the sparse, modular nature of knowledge in transformers.
Using SAMD, we find that only a few attention heads are crucial for a wide range of concepts—confirming the sparse, modular nature of knowledge in transformers.
July 8, 2025 at 1:49 PM
SAMD: Finds the attention heads most correlated with a concept
Using SAMD, we find that only a few attention heads are crucial for a wide range of concepts—confirming the sparse, modular nature of knowledge in transformers.
Using SAMD, we find that only a few attention heads are crucial for a wide range of concepts—confirming the sparse, modular nature of knowledge in transformers.
How would you make an LLM "forget" the concept of dog — or any other arbitrary concept? 🐶❓
We introduce SAMD & SAMI — a novel, concept-agnostic approach to identify and manipulate attention modules in transformers.
We introduce SAMD & SAMI — a novel, concept-agnostic approach to identify and manipulate attention modules in transformers.


July 8, 2025 at 1:49 PM
How would you make an LLM "forget" the concept of dog — or any other arbitrary concept? 🐶❓
We introduce SAMD & SAMI — a novel, concept-agnostic approach to identify and manipulate attention modules in transformers.
We introduce SAMD & SAMI — a novel, concept-agnostic approach to identify and manipulate attention modules in transformers.
Aligned Multi-Objective Optimization (A-🐮) has been accepted at #ICML2025! 🎉
We explore optimization scenarios where objectives align rather than conflict, introducing new scalable algorithms with theoretical guarantees. #MachineLearning #AI #Optimization
We explore optimization scenarios where objectives align rather than conflict, introducing new scalable algorithms with theoretical guarantees. #MachineLearning #AI #Optimization

May 1, 2025 at 7:19 PM
Aligned Multi-Objective Optimization (A-🐮) has been accepted at #ICML2025! 🎉
We explore optimization scenarios where objectives align rather than conflict, introducing new scalable algorithms with theoretical guarantees. #MachineLearning #AI #Optimization
We explore optimization scenarios where objectives align rather than conflict, introducing new scalable algorithms with theoretical guarantees. #MachineLearning #AI #Optimization
🎉🎉 Our paper just got accepted to #ICLR2025! 🎉🎉
Byte-level LLMs without training and guaranteed performance? Curious how? Dive into our work! 📚✨
Paper: arxiv.org/abs/2410.09303
Github: github.com/facebookrese...
Byte-level LLMs without training and guaranteed performance? Curious how? Dive into our work! 📚✨
Paper: arxiv.org/abs/2410.09303
Github: github.com/facebookrese...

January 22, 2025 at 8:57 PM
🎉🎉 Our paper just got accepted to #ICLR2025! 🎉🎉
Byte-level LLMs without training and guaranteed performance? Curious how? Dive into our work! 📚✨
Paper: arxiv.org/abs/2410.09303
Github: github.com/facebookrese...
Byte-level LLMs without training and guaranteed performance? Curious how? Dive into our work! 📚✨
Paper: arxiv.org/abs/2410.09303
Github: github.com/facebookrese...
Pro-tip: Use massive black Friday deals at scientific publishing houses to for example buy a copy of @jmtomczak.bsky.social
book on generative modeling (long overdue)
book on generative modeling (long overdue)

November 28, 2024 at 3:49 PM
Pro-tip: Use massive black Friday deals at scientific publishing houses to for example buy a copy of @jmtomczak.bsky.social
book on generative modeling (long overdue)
book on generative modeling (long overdue)
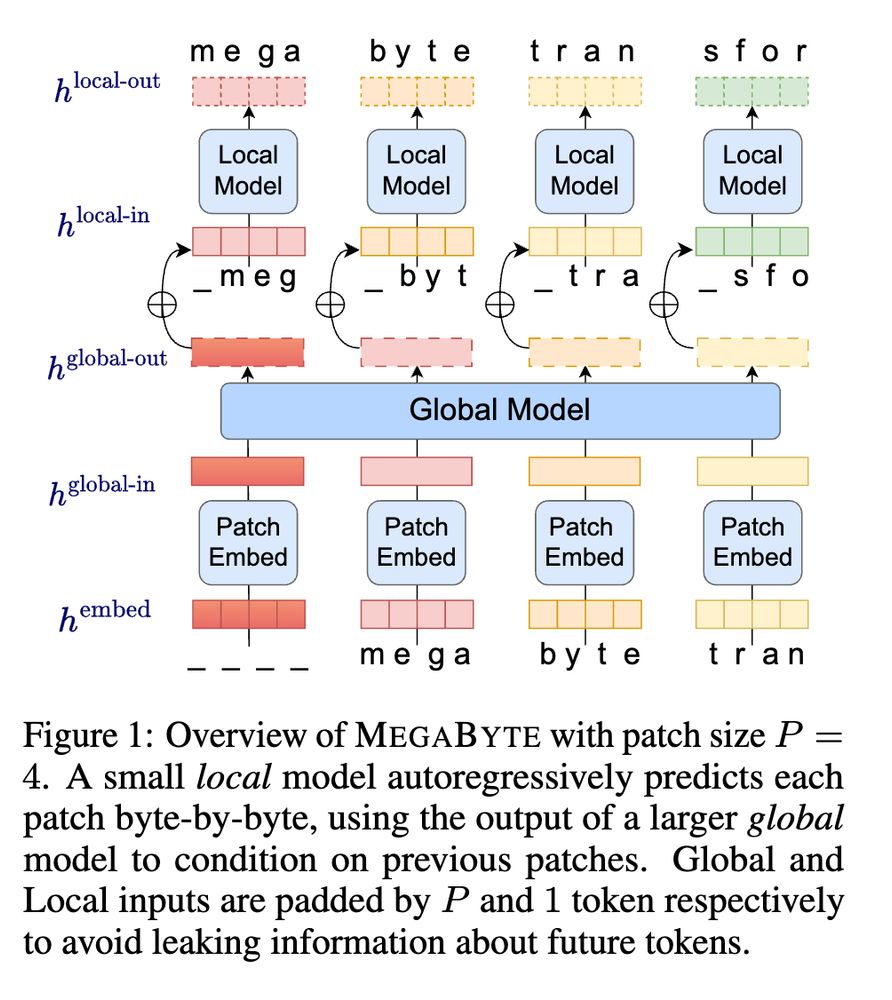
What do you think do we need to sharpen our understanding of tokenization? Or will we soon be rid of it by developing models such as "MegaByte" by
Yu et al?
And add more paper to the threat!
Yu et al?
And add more paper to the threat!
October 30, 2024 at 6:29 PM
What do you think do we need to sharpen our understanding of tokenization? Or will we soon be rid of it by developing models such as "MegaByte" by
Yu et al?
And add more paper to the threat!
Yu et al?
And add more paper to the threat!
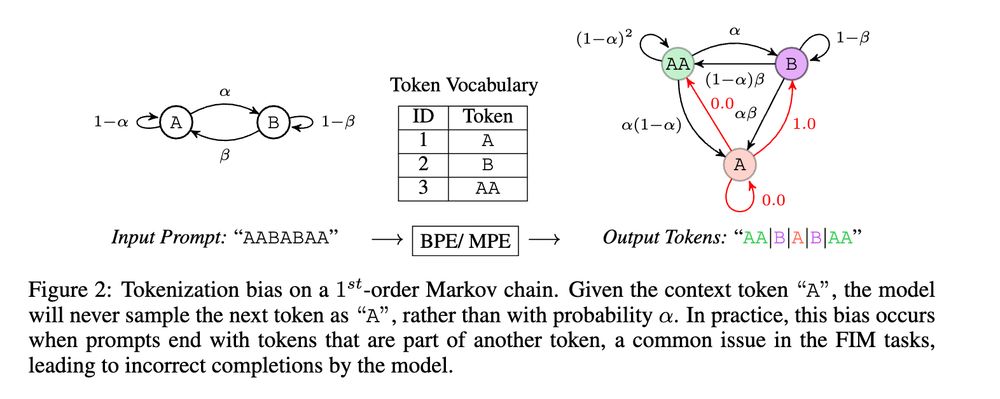
Phan et al, found a method to mitigate some of the tokenization problems Karpathy mentioned by projecting tokens into byte space. The key to their method is to develop a map between statistically equivalent token and byte-level models.
October 30, 2024 at 6:29 PM
Phan et al, found a method to mitigate some of the tokenization problems Karpathy mentioned by projecting tokens into byte space. The key to their method is to develop a map between statistically equivalent token and byte-level models.
In "The Foundations of Tokenization:
Statistical and Computational Concerns", Gastaldi et al. try to make first steps towards defining what a tokenizer should be and define properties it ought to have.
Statistical and Computational Concerns", Gastaldi et al. try to make first steps towards defining what a tokenizer should be and define properties it ought to have.

October 30, 2024 at 6:27 PM
In "The Foundations of Tokenization:
Statistical and Computational Concerns", Gastaldi et al. try to make first steps towards defining what a tokenizer should be and define properties it ought to have.
Statistical and Computational Concerns", Gastaldi et al. try to make first steps towards defining what a tokenizer should be and define properties it ought to have.
In "Toward a Theory of Tokenization in LLMs" Rajaraman et al., the authors discuss why we can think of tokenization to cause lower perplexity/ a better entropy bound.

October 30, 2024 at 6:27 PM
In "Toward a Theory of Tokenization in LLMs" Rajaraman et al., the authors discuss why we can think of tokenization to cause lower perplexity/ a better entropy bound.
A must watch entry point is @karpathy.bsky.social hy's "Let's build the GPT Tokenizer" video, where he discusses some tokenization problems.

October 30, 2024 at 6:27 PM
A must watch entry point is @karpathy.bsky.social hy's "Let's build the GPT Tokenizer" video, where he discusses some tokenization problems.
🎉 Exciting News! 🎉
Two papers have been accepted at #NeurIPS2024 ! 🙌🏼 These papers are the first outcomes of my growing focus on LLMs. 🍾 Cheers to Nikita Dhawan and Jingtong Su + all involved collaborators: @cmaddis.bsky.social Leo Cotta, Rahul Krishnan, Julia Kempe
Two papers have been accepted at #NeurIPS2024 ! 🙌🏼 These papers are the first outcomes of my growing focus on LLMs. 🍾 Cheers to Nikita Dhawan and Jingtong Su + all involved collaborators: @cmaddis.bsky.social Leo Cotta, Rahul Krishnan, Julia Kempe


September 26, 2024 at 6:02 PM
🎉 Exciting News! 🎉
Two papers have been accepted at #NeurIPS2024 ! 🙌🏼 These papers are the first outcomes of my growing focus on LLMs. 🍾 Cheers to Nikita Dhawan and Jingtong Su + all involved collaborators: @cmaddis.bsky.social Leo Cotta, Rahul Krishnan, Julia Kempe
Two papers have been accepted at #NeurIPS2024 ! 🙌🏼 These papers are the first outcomes of my growing focus on LLMs. 🍾 Cheers to Nikita Dhawan and Jingtong Su + all involved collaborators: @cmaddis.bsky.social Leo Cotta, Rahul Krishnan, Julia Kempe