



Julie
@juliemdc.bsky.social
PhD Student at Inria Saclay and Ecole Polytechnique (GeomeriX and VISTA teams)
Reposted by Julie

Check out our new work: MIRO
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
October 31, 2025 at 9:11 PM
Check out our new work: MIRO
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
Reposted by Julie

We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉

October 31, 2025 at 11:24 AM
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
Reposted by Julie
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.

August 18, 2025 at 3:14 PM
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
Reposted by Julie
I will be at #CVPR2025 this week in Nashville.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
June 11, 2025 at 12:52 AM
I will be at #CVPR2025 this week in Nashville.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
Reposted by Julie

Masked Diffusion Models (MDMs) are a hot topic in generative AI 🔥 — powerful but slow due to multiple sampling steps.
We @polytechniqueparis.bsky.social and @inria-grenoble.bsky.social introduce Di[M]O — a novel approach to distill MDMs into a one-step generator without sacrificing quality.
We @polytechniqueparis.bsky.social and @inria-grenoble.bsky.social introduce Di[M]O — a novel approach to distill MDMs into a one-step generator without sacrificing quality.
March 21, 2025 at 3:36 PM
Masked Diffusion Models (MDMs) are a hot topic in generative AI 🔥 — powerful but slow due to multiple sampling steps.
We @polytechniqueparis.bsky.social and @inria-grenoble.bsky.social introduce Di[M]O — a novel approach to distill MDMs into a one-step generator without sacrificing quality.
We @polytechniqueparis.bsky.social and @inria-grenoble.bsky.social introduce Di[M]O — a novel approach to distill MDMs into a one-step generator without sacrificing quality.
Reposted by Julie
Check out our latest work on Text-to-Image generation! We've successfully trained a T2I model using only ImageNet data by leveraging captioning and data augmentation.

🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇

March 3, 2025 at 10:32 AM
Check out our latest work on Text-to-Image generation! We've successfully trained a T2I model using only ImageNet data by leveraging captioning and data augmentation.
Reposted by Julie
Our paper got accepted at TMLR!
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.

December 20, 2024 at 1:23 AM
Our paper got accepted at TMLR!
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.
Reposted by Julie
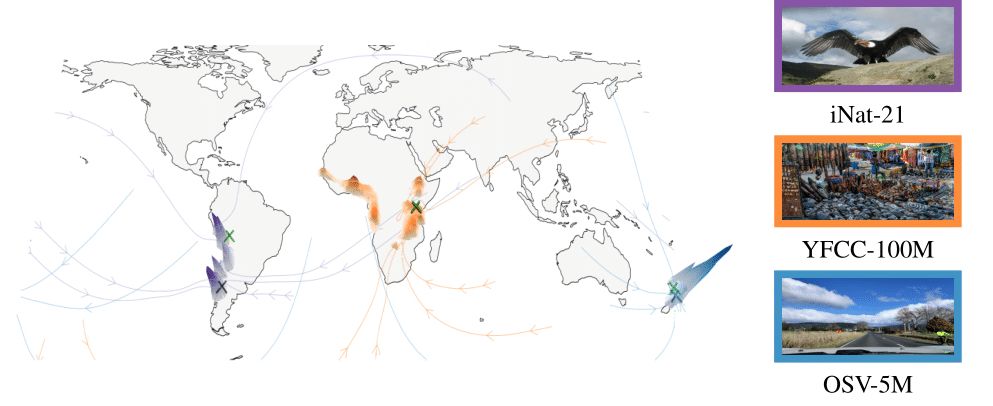
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
December 10, 2024 at 3:56 PM
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk