




Julen Etxaniz
@juletxara.bsky.social
PhD Student in Language Analysis and Processing at HiTZ Zentroa - IXA UPV/EHU Working on Improving Language Models for Low-resource Languages.
Reposted by Julen Etxaniz

Very interesting dataset related to a yet unsolved problem: how do children learn language. Basque and other 44 languages! Glad that our center is involved with co-author @juletxara.bsky.social
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!

October 15, 2025 at 11:39 AM
Very interesting dataset related to a yet unsolved problem: how do children learn language. Basque and other 44 languages! Glad that our center is involved with co-author @juletxara.bsky.social
Reposted by Julen Etxaniz

🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
October 15, 2025 at 10:53 AM
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
Reposted by Julen Etxaniz

𝐃𝐨 𝐲𝐨𝐮 𝐫𝐞𝐚𝐥𝐥𝐲 𝐰𝐚𝐧𝐭 𝐭𝐨 𝐬𝐞𝐞 𝐰𝐡𝐚𝐭 𝐦𝐮𝐥𝐭𝐢𝐥𝐢𝐧𝐠𝐮𝐚𝐥 𝐞𝐟𝐟𝐨𝐫𝐭 𝐥𝐨𝐨𝐤𝐬 𝐥𝐢𝐤𝐞? 🇨🇳🇮🇩🇸🇪
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159

October 14, 2025 at 5:01 PM
𝐃𝐨 𝐲𝐨𝐮 𝐫𝐞𝐚𝐥𝐥𝐲 𝐰𝐚𝐧𝐭 𝐭𝐨 𝐬𝐞𝐞 𝐰𝐡𝐚𝐭 𝐦𝐮𝐥𝐭𝐢𝐥𝐢𝐧𝐠𝐮𝐚𝐥 𝐞𝐟𝐟𝐨𝐫𝐭 𝐥𝐨𝐨𝐤𝐬 𝐥𝐢𝐤𝐞? 🇨🇳🇮🇩🇸🇪
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159
Reposted by Julen Etxaniz

Ayer presenté mi proyecto de tesis "Document Level Information Extraction in Low-Resource Languages" en el simposio doctoral del congreso #SEPLN2025 ¡Eskerrik asko a los organizadores!

September 26, 2025 at 10:39 AM
Ayer presenté mi proyecto de tesis "Document Level Information Extraction in Low-Resource Languages" en el simposio doctoral del congreso #SEPLN2025 ¡Eskerrik asko a los organizadores!
Reposted by Julen Etxaniz

#newHitzPaper
Can a simple inference-time approach unlock better Vision-Language Compositionality?🤯
Our latest paper shows how adding structure at inference significantly boosts performance in popular dual-encoder VLMs on different datasets.
Read more: arxiv.org/abs/2506.09691
Can a simple inference-time approach unlock better Vision-Language Compositionality?🤯
Our latest paper shows how adding structure at inference significantly boosts performance in popular dual-encoder VLMs on different datasets.
Read more: arxiv.org/abs/2506.09691

June 18, 2025 at 11:28 AM
#newHitzPaper
Can a simple inference-time approach unlock better Vision-Language Compositionality?🤯
Our latest paper shows how adding structure at inference significantly boosts performance in popular dual-encoder VLMs on different datasets.
Read more: arxiv.org/abs/2506.09691
Can a simple inference-time approach unlock better Vision-Language Compositionality?🤯
Our latest paper shows how adding structure at inference significantly boosts performance in popular dual-encoder VLMs on different datasets.
Read more: arxiv.org/abs/2506.09691
Reposted by Julen Etxaniz

Jakintza alor guztietako mikroaurkezpenen txanda kafera bitarte #ikergazte2025




May 30, 2025 at 8:24 AM
Jakintza alor guztietako mikroaurkezpenen txanda kafera bitarte #ikergazte2025
Reposted by Julen Etxaniz

Primeran aritu dire gure kideak #IKERGAZTE2025 kongresuan!

May 30, 2025 at 10:44 AM
Primeran aritu dire gure kideak #IKERGAZTE2025 kongresuan!
Reposted by Julen Etxaniz

🚨 Paper Alert: “RL Finetunes Small Subnetworks in Large Language Models”
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive

May 21, 2025 at 3:50 AM
🚨 Paper Alert: “RL Finetunes Small Subnetworks in Large Language Models”
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
Reposted by Julen Etxaniz

Euskal Herriko Unibertsitateak #HITZ bezalako erreferentziazko ikerketa zentroak izateak harrotasunez betetzen gaitu. Eneko Agirre zuzendaria eta bere taldekideekin izan gara goizean.
Jarrai dezazuela bide berriak urratzen hizkuntza eta ahotsa ardatz duen AAren inguruan, @hitz-zentroa.bsky.social.
Jarrai dezazuela bide berriak urratzen hizkuntza eta ahotsa ardatz duen AAren inguruan, @hitz-zentroa.bsky.social.

March 24, 2025 at 11:39 AM
Euskal Herriko Unibertsitateak #HITZ bezalako erreferentziazko ikerketa zentroak izateak harrotasunez betetzen gaitu. Eneko Agirre zuzendaria eta bere taldekideekin izan gara goizean.
Jarrai dezazuela bide berriak urratzen hizkuntza eta ahotsa ardatz duen AAren inguruan, @hitz-zentroa.bsky.social.
Jarrai dezazuela bide berriak urratzen hizkuntza eta ahotsa ardatz duen AAren inguruan, @hitz-zentroa.bsky.social.
Reposted by Julen Etxaniz

🧙♂️ New paper 🧙♀️:
Presenting Wicked: a simple automated method to make MCQA benchmarks more challenging. Wicked shook up 18 open-weight LLMs on 6 benchmarks, with up to 19.7% performance drop with direct prompting 🤯
Paper: shorturl.at/1CGq0
Code: shorturl.at/n2nCU
Presenting Wicked: a simple automated method to make MCQA benchmarks more challenging. Wicked shook up 18 open-weight LLMs on 6 benchmarks, with up to 19.7% performance drop with direct prompting 🤯
Paper: shorturl.at/1CGq0
Code: shorturl.at/n2nCU

February 26, 2025 at 11:51 AM
🧙♂️ New paper 🧙♀️:
Presenting Wicked: a simple automated method to make MCQA benchmarks more challenging. Wicked shook up 18 open-weight LLMs on 6 benchmarks, with up to 19.7% performance drop with direct prompting 🤯
Paper: shorturl.at/1CGq0
Code: shorturl.at/n2nCU
Presenting Wicked: a simple automated method to make MCQA benchmarks more challenging. Wicked shook up 18 open-weight LLMs on 6 benchmarks, with up to 19.7% performance drop with direct prompting 🤯
Paper: shorturl.at/1CGq0
Code: shorturl.at/n2nCU
Reposted by Julen Etxaniz

Are humans able to assess if an argument is valid? Can LLMs help them raise the appropriate critical questions to assess its validity?
🤖 Let's use AI to make us more critical!
🤖 Let's use AI to make us more critical!
February 17, 2025 at 1:51 PM
Are humans able to assess if an argument is valid? Can LLMs help them raise the appropriate critical questions to assess its validity?
🤖 Let's use AI to make us more critical!
🤖 Let's use AI to make us more critical!
Reposted by Julen Etxaniz

Bisita izan dugu! Eusko Jaurlaritzako Hizkuntza Politikarako Sailburuordetzako talde zabalarekin, Aitor Aldasoro sailburuordea, Josune Irabien eta Sonia Rodriguez barne, arratsalde ederra pasa genuen zentroa erakusten eta Ikergaitu proiektuko azken emaitzak erakusten https://www.hitz.eus/iker-gaitu/

February 17, 2025 at 9:39 AM
Bisita izan dugu! Eusko Jaurlaritzako Hizkuntza Politikarako Sailburuordetzako talde zabalarekin, Aitor Aldasoro sailburuordea, Josune Irabien eta Sonia Rodriguez barne, arratsalde ederra pasa genuen zentroa erakusten eta Ikergaitu proiektuko azken emaitzak erakusten https://www.hitz.eus/iker-gaitu/
Reposted by Julen Etxaniz
Bisita izan dugu! Zientzia, Unibertsitateak eta Berrikuntza saileko Juan Ignacio Pérez sailburua @juanignacioperez.bsky.social , Adolfo Morais eta Xabier Aizpurua sailburuordeekin eguerdi ederra pasa @hitz-zentroa.bsky.social erakusten eta Adimen Artifizialean azken garapenen inguruan jarduten.

February 17, 2025 at 10:03 AM
Bisita izan dugu! Zientzia, Unibertsitateak eta Berrikuntza saileko Juan Ignacio Pérez sailburua @juanignacioperez.bsky.social , Adolfo Morais eta Xabier Aizpurua sailburuordeekin eguerdi ederra pasa @hitz-zentroa.bsky.social erakusten eta Adimen Artifizialean azken garapenen inguruan jarduten.
Reposted by Julen Etxaniz
Iker de la Iglesiak medikuntzako argumentuen ebaluazio automatikoari buruzko posterra aurkeztu du #COLING2025 konferentzian


January 23, 2025 at 10:51 AM
Iker de la Iglesiak medikuntzako argumentuen ebaluazio automatikoari buruzko posterra aurkeztu du #COLING2025 konferentzian
Reposted by Julen Etxaniz

Reposted by Julen Etxaniz
Paula Ontalvillak "Improving the Efficiency of Visually Augmented Language Models" lana aurkeztu du COLING konferentzian




January 22, 2025 at 7:16 AM
Paula Ontalvillak "Improving the Efficiency of Visually Augmented Language Models" lana aurkeztu du COLING konferentzian
Reposted by Julen Etxaniz
We presented two posters at #NeurIPS2024! @gazkune.bsky.social @juletxara.bsky.social and Imanol Miranda

December 26, 2024 at 1:49 PM
We presented two posters at #NeurIPS2024! @gazkune.bsky.social @juletxara.bsky.social and Imanol Miranda
Reposted by Julen Etxaniz

If you are interested in LLMs' knowledge about local cultures, check this paper by @juletxara.bsky.social
and come to discuss with us in Vancouver #NeurIPS2024 arxiv.org/abs/2406.07302
and come to discuss with us in Vancouver #NeurIPS2024 arxiv.org/abs/2406.07302

BertaQA: How Much Do Language Models Know About Local Culture?
Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how well these models p...
arxiv.org
December 8, 2024 at 9:21 AM
If you are interested in LLMs' knowledge about local cultures, check this paper by @juletxara.bsky.social
and come to discuss with us in Vancouver #NeurIPS2024 arxiv.org/abs/2406.07302
and come to discuss with us in Vancouver #NeurIPS2024 arxiv.org/abs/2406.07302
Reposted by Julen Etxaniz

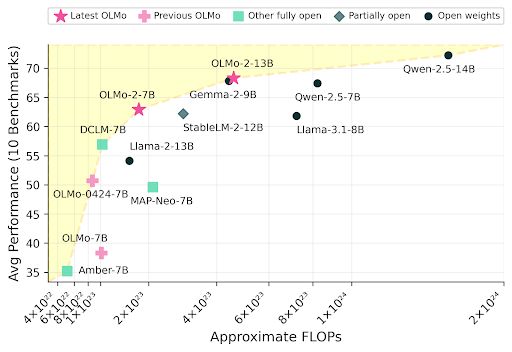
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
November 26, 2024 at 8:51 PM
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
Reposted by Julen Etxaniz

OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
November 26, 2024 at 9:12 PM
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social