



Julien Pourcel
@jul-p.bsky.social
PhD student at INRIA (FLOWERS team) working on LLM4code | Prev. (MVA) ENS ParisSaclay
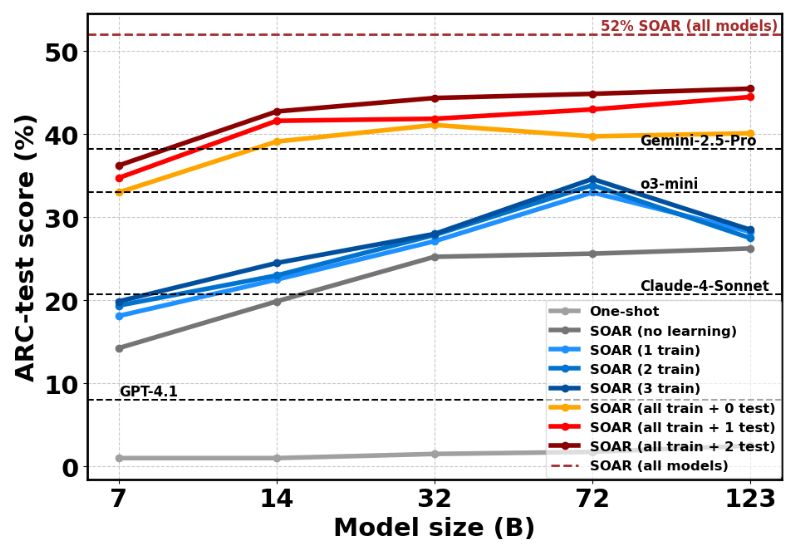
📈 **Results**:
- Qwen-7B model: 6% → 36% accuracy
- Qwen-32B model: 13% → 45% accuracy
- Mistral-Large-2: 20% -> 46% accuracy
- Combined ensemble: 52% on ARC-AGI test set
- Outperforms much larger models like o3-mini and Claude-4-Sonnet
- Qwen-7B model: 6% → 36% accuracy
- Qwen-32B model: 13% → 45% accuracy
- Mistral-Large-2: 20% -> 46% accuracy
- Combined ensemble: 52% on ARC-AGI test set
- Outperforms much larger models like o3-mini and Claude-4-Sonnet
July 10, 2025 at 4:04 PM
📈 **Results**:
- Qwen-7B model: 6% → 36% accuracy
- Qwen-32B model: 13% → 45% accuracy
- Mistral-Large-2: 20% -> 46% accuracy
- Combined ensemble: 52% on ARC-AGI test set
- Outperforms much larger models like o3-mini and Claude-4-Sonnet
- Qwen-7B model: 6% → 36% accuracy
- Qwen-32B model: 13% → 45% accuracy
- Mistral-Large-2: 20% -> 46% accuracy
- Combined ensemble: 52% on ARC-AGI test set
- Outperforms much larger models like o3-mini and Claude-4-Sonnet
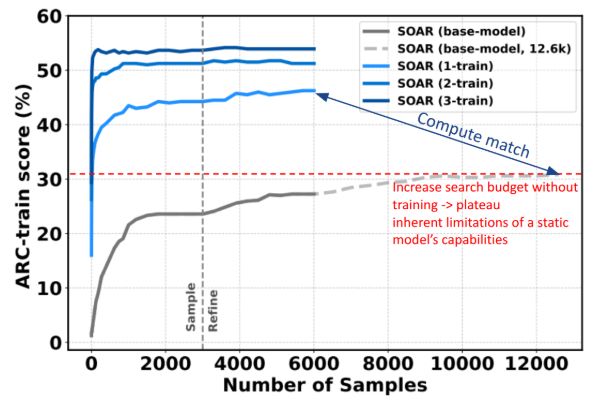
🔬 Why This Matters? Most coding tasks are too hard for even the best language models to solve in one shot. Traditional search methods help, but they hit a wall because the model’s abilities are fixed. SOAR breaks through this barrier by letting the model improve itself over time
July 10, 2025 at 4:04 PM
🔬 Why This Matters? Most coding tasks are too hard for even the best language models to solve in one shot. Traditional search methods help, but they hit a wall because the model’s abilities are fixed. SOAR breaks through this barrier by letting the model improve itself over time
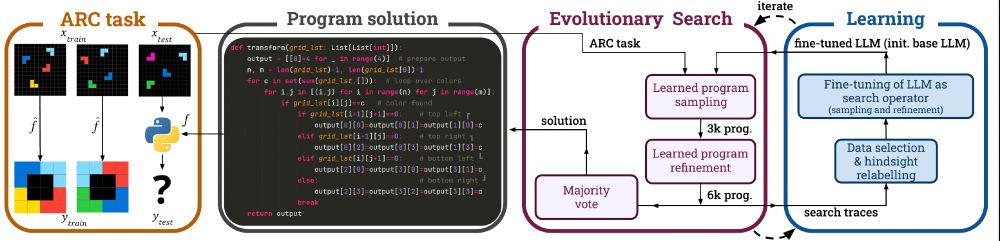
Introducing SOAR 🚀, a self-improving framework for prog synth that alternates between search and learning (accepted to #ICML!)
It brings LLMs from just a few percent on ARC-AGI-1 up to 52%
We’re releasing the finetuned LLMs, a dataset of 5M generated programs and the code.
🧵
It brings LLMs from just a few percent on ARC-AGI-1 up to 52%
We’re releasing the finetuned LLMs, a dataset of 5M generated programs and the code.
🧵
July 10, 2025 at 4:04 PM
Introducing SOAR 🚀, a self-improving framework for prog synth that alternates between search and learning (accepted to #ICML!)
It brings LLMs from just a few percent on ARC-AGI-1 up to 52%
We’re releasing the finetuned LLMs, a dataset of 5M generated programs and the code.
🧵
It brings LLMs from just a few percent on ARC-AGI-1 up to 52%
We’re releasing the finetuned LLMs, a dataset of 5M generated programs and the code.
🧵