


Josh McDermott
@joshhmcdermott.bsky.social
Working to understand how humans and machines hear. Prof at MIT; director of Lab for Computational Audition. https://mcdermottlab.mit.edu/
He measured human confidence for pitch, and found that confidence was higher for conditions with lower discrimination thresholds. The model reproduced this general trend. (13/n)

November 9, 2025 at 9:34 PM
He measured human confidence for pitch, and found that confidence was higher for conditions with lower discrimination thresholds. The model reproduced this general trend. (13/n)
Lakshmi used the same framework to build models of pitch perception that represent uncertainty. The models generate a distribution over fundamental frequency. (12/n)

November 9, 2025 at 9:34 PM
Lakshmi used the same framework to build models of pitch perception that represent uncertainty. The models generate a distribution over fundamental frequency. (12/n)
By contrast, simulating bets using the softmax distribution of a standard classification-based neural network does not yield human-like confidence, presumably because the distribution is not incentivized to have correct uncertainty. (11/n)

November 9, 2025 at 9:34 PM
By contrast, simulating bets using the softmax distribution of a standard classification-based neural network does not yield human-like confidence, presumably because the distribution is not incentivized to have correct uncertainty. (11/n)
The model can also be used to select natural sounds whose localization is certain or uncertain. When presented to humans, humans place higher bets on the sounds with low model uncertainty, and vice versa. (10/n)

November 9, 2025 at 9:34 PM
The model can also be used to select natural sounds whose localization is certain or uncertain. When presented to humans, humans place higher bets on the sounds with low model uncertainty, and vice versa. (10/n)
The model replicates patterns of localization accuracy (like previous models) but also replicates the dependence of confidence on conditions. Here confidence is lower for sounds with narrower spectra, and at peripheral locations: (9/n)

November 9, 2025 at 9:34 PM
The model replicates patterns of localization accuracy (like previous models) but also replicates the dependence of confidence on conditions. Here confidence is lower for sounds with narrower spectra, and at peripheral locations: (9/n)
To simulate betting behavior from the model, he mapped a measure of the model posterior spread to a bet (in cents). (8/n)

November 9, 2025 at 9:34 PM
To simulate betting behavior from the model, he mapped a measure of the model posterior spread to a bet (in cents). (8/n)
Lakshmi then tested whether the model’s uncertainty was predictive of human confidence judgments. He ran experiments in which people localized sounds and then placed bets on their localization judgment: (7/n)

November 9, 2025 at 9:34 PM
Lakshmi then tested whether the model’s uncertainty was predictive of human confidence judgments. He ran experiments in which people localized sounds and then placed bets on their localization judgment: (7/n)
The model was trained on spatial renderings of lots of natural sounds in lots of different rooms. Once trained, it produces narrow posteriors for some sounds, and broad posteriors for others: (6/n)

November 9, 2025 at 9:34 PM
The model was trained on spatial renderings of lots of natural sounds in lots of different rooms. Once trained, it produces narrow posteriors for some sounds, and broad posteriors for others: (6/n)
He first applied this idea to sound localization. The model takes binaural audio as input and estimates parameters of a mixture distribution over a sphere. Distributions can be narrow, broad, or multi-modal, depending on the stimulus. (5/n)

November 9, 2025 at 9:34 PM
He first applied this idea to sound localization. The model takes binaural audio as input and estimates parameters of a mixture distribution over a sphere. Distributions can be narrow, broad, or multi-modal, depending on the stimulus. (5/n)
Lakshmi realized that models could be trained to output parameters of distributions, and that by optimizing models with a log-likelihood loss function, the model is incentivized to correctly represent uncertainty. (4/n)
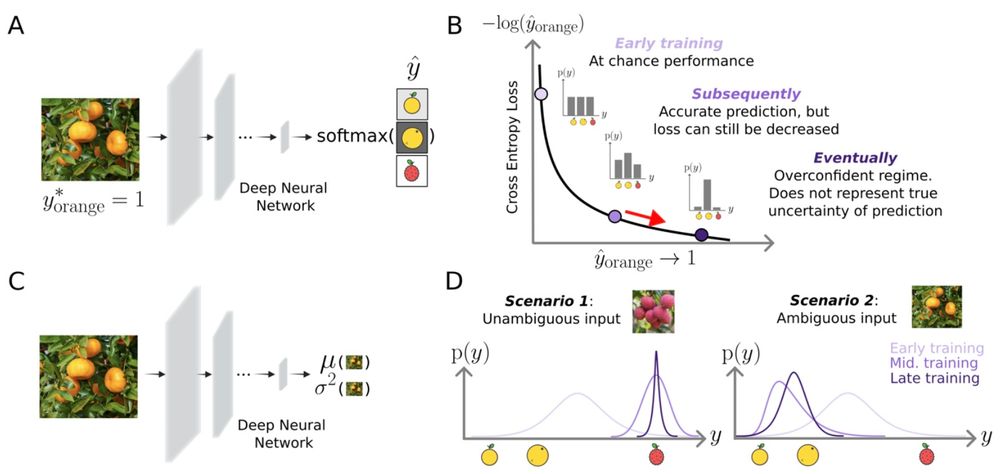
November 9, 2025 at 9:34 PM
Lakshmi realized that models could be trained to output parameters of distributions, and that by optimizing models with a log-likelihood loss function, the model is incentivized to correctly represent uncertainty. (4/n)
Please to announce the successful thesis defense of Dr. Jarrod Hicks! His thesis provides the first thorough exploration of auditory scene analysis with environmental sounds. I’m excited to see what he does next.

February 13, 2025 at 1:34 PM
Please to announce the successful thesis defense of Dr. Jarrod Hicks! His thesis provides the first thorough exploration of auditory scene analysis with environmental sounds. I’m excited to see what he does next.
I'm pleased to announce the successful thesis defense of Dr. Vin Agarwal! His thesis compiles an impressive body of work on auditory intuitive physics. Stay tuned for some great papers. It has been a pleasure working with him.

February 5, 2025 at 11:38 AM
I'm pleased to announce the successful thesis defense of Dr. Vin Agarwal! His thesis compiles an impressive body of work on auditory intuitive physics. Stay tuned for some great papers. It has been a pleasure working with him.
At UniReps today: Gasser Elbanna's poster "Artificial Neural Networks Generate Human-like Continuous Speech Perception". West Exhibition Hall C, B3.
Gasser built models of phoneme recognition, and finds that they replicate human confusions pretty well.
Gasser built models of phoneme recognition, and finds that they replicate human confusions pretty well.

December 14, 2024 at 12:50 PM
At UniReps today: Gasser Elbanna's poster "Artificial Neural Networks Generate Human-like Continuous Speech Perception". West Exhibition Hall C, B3.
Gasser built models of phoneme recognition, and finds that they replicate human confusions pretty well.
Gasser built models of phoneme recognition, and finds that they replicate human confusions pretty well.
One other useful result: Mark showed that machine learning models closely approximate traditional ideal observers when optimized for the simple tasks for which you can derive proper ideal observers, giving credence to our general approach. (13/n)

December 13, 2024 at 4:13 PM
One other useful result: Mark showed that machine learning models closely approximate traditional ideal observers when optimized for the simple tasks for which you can derive proper ideal observers, giving credence to our general approach. (13/n)
Here is one cool effect. Human voice recognition is known to depend on pitch, such that it is worse when you shift the f0 of a voice. Models exhibit the same effect, but only if they have access to phase-locked spikes in their input. (10/n)

December 13, 2024 at 4:13 PM
Here is one cool effect. Human voice recognition is known to depend on pitch, such that it is worse when you shift the f0 of a voice. Models exhibit the same effect, but only if they have access to phase-locked spikes in their input. (10/n)
The biggest effects were on sound localization and voice recognition. Suggests that auditory attention (which is often directed to a particular voice at a particular location) is likely to be impaired in the absence of phase locking, consistent with some current proposals. (7/n)

December 13, 2024 at 4:13 PM
The biggest effects were on sound localization and voice recognition. Suggests that auditory attention (which is often directed to a particular voice at a particular location) is likely to be impaired in the absence of phase locking, consistent with some current proposals. (7/n)
This variation across task domains was largely explained by the temporal fidelity needed to achieve good task performance in real-world conditions (hearing in noise), indicating that different domains incorporate temporal coding as needed for what they have to do. (6/n)

December 13, 2024 at 4:13 PM
This variation across task domains was largely explained by the temporal fidelity needed to achieve good task performance in real-world conditions (hearing in noise), indicating that different domains incorporate temporal coding as needed for what they have to do. (6/n)
The results show that models require some degree of phase locking to exhibit human-like behavior, but that the extent needed depends on the domain (sound localization, voice recognition, or word recognition). (5/n)
December 13, 2024 at 4:13 PM
The results show that models require some degree of phase locking to exhibit human-like behavior, but that the extent needed depends on the domain (sound localization, voice recognition, or word recognition). (5/n)
Mark varied the fidelity of temporal coding in a simulated ear by manipulating the cutoff of a lowpass filter in simulated hair cells. (4/n)

December 13, 2024 at 4:13 PM
Mark varied the fidelity of temporal coding in a simulated ear by manipulating the cutoff of a lowpass filter in simulated hair cells. (4/n)
The idea of the paper was to optimize artificial neural networks to perform auditory tasks using input from simulated auditory nerve fibers, and to test whether high-fidelity spike timing (“phase locking”) was necessary to match human behavior. (3/n)

December 13, 2024 at 4:13 PM
The idea of the paper was to optimize artificial neural networks to perform auditory tasks using input from simulated auditory nerve fibers, and to test whether high-fidelity spike timing (“phase locking”) was necessary to match human behavior. (3/n)
The ear exhibits incredibly precise spike timing, but its role in perception has been unclear. Knowing this role is important for understanding hearing loss and auditory prosthetics. (2/n)

December 13, 2024 at 4:13 PM
The ear exhibits incredibly precise spike timing, but its role in perception has been unclear. Knowing this role is important for understanding hearing loss and auditory prosthetics. (2/n)