


Joel Mire
@joelmire.bsky.social
Master’s student @ltiatcmu.bsky.social. he/him
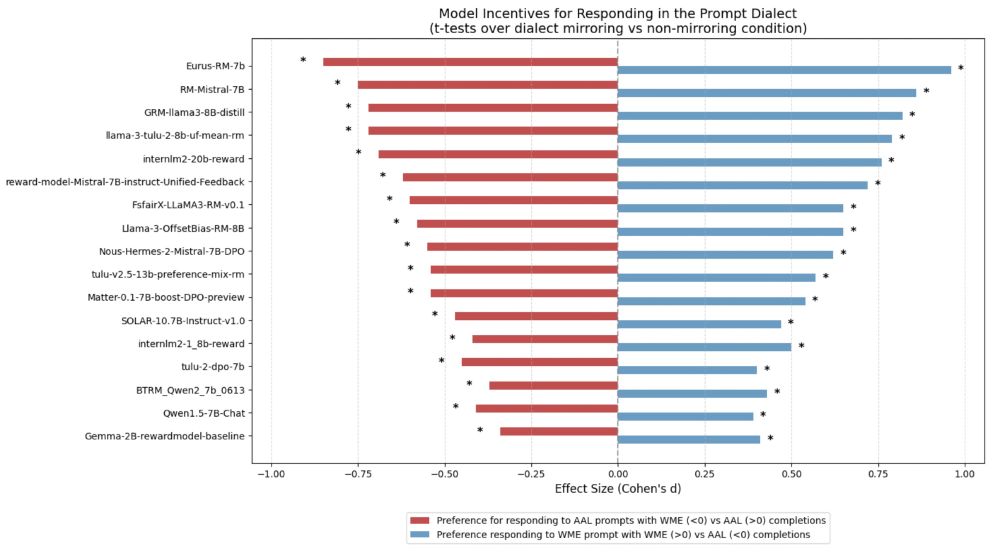
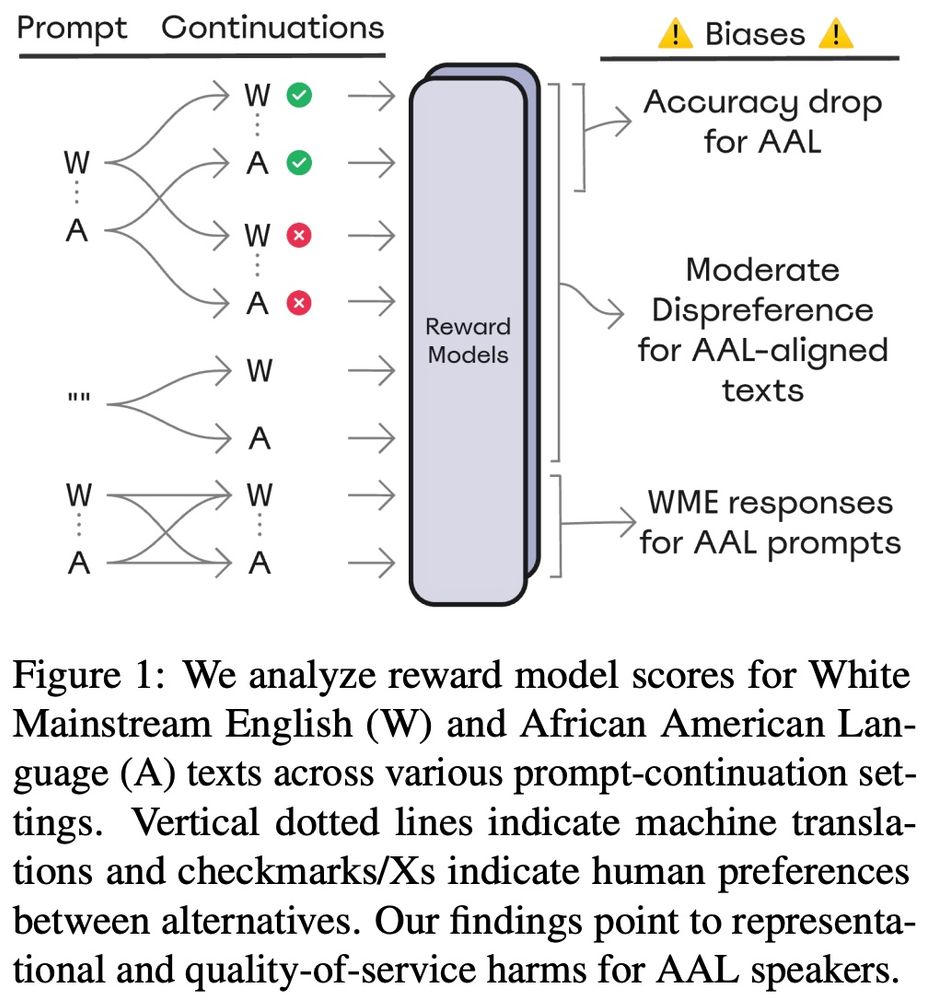
Finally, we show that the reward models strongly incentivize steering conversations toward WME, even when prompted with AAL. 🗣️🔄 (7/10)
March 6, 2025 at 7:49 PM
Finally, we show that the reward models strongly incentivize steering conversations toward WME, even when prompted with AAL. 🗣️🔄 (7/10)
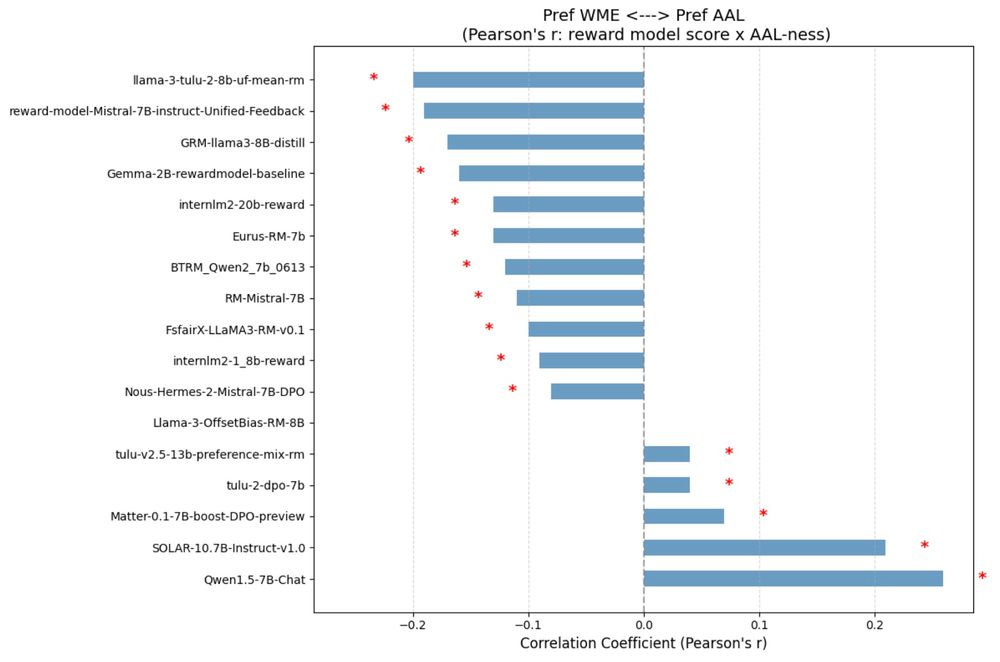
Also, for most models, rewards are negatively correlated with the predicted AAL-ness of a text (based on a pre-existing dialect detection tool). (6/10)
March 6, 2025 at 7:49 PM
Also, for most models, rewards are negatively correlated with the predicted AAL-ness of a text (based on a pre-existing dialect detection tool). (6/10)
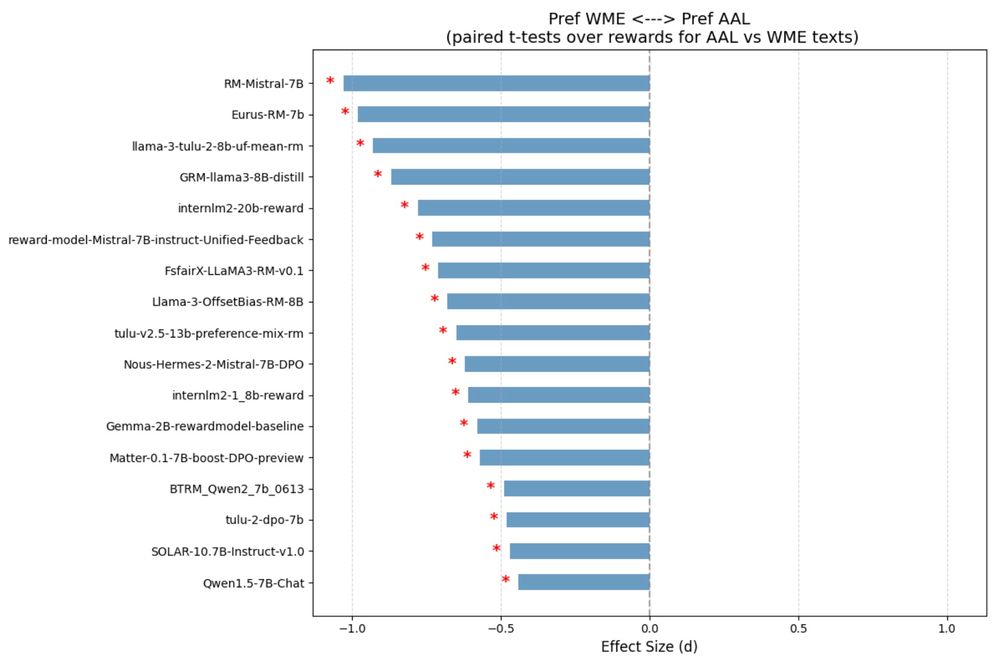
Next, we show that most reward models predict lower rewards for AAL texts ⬇️ (5/10)
March 6, 2025 at 7:49 PM
Next, we show that most reward models predict lower rewards for AAL texts ⬇️ (5/10)
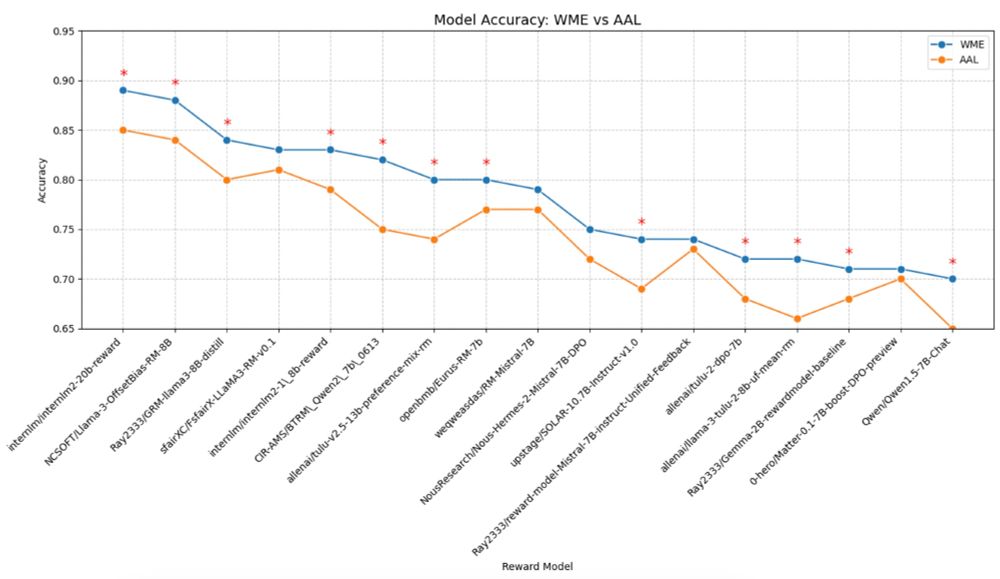
First, we see a significant drop in performance (-4% accuracy on average) in assigning higher rewards to human-preferred completions when processing AAL texts vs. WME texts. 📉 (4/10)
March 6, 2025 at 7:49 PM
First, we see a significant drop in performance (-4% accuracy on average) in assigning higher rewards to human-preferred completions when processing AAL texts vs. WME texts. 📉 (4/10)
We introduce morphosyntactic & phonological features of AAL into WME texts from the RewardBench dataset using validated automatic translation methods. Then, we test 17 reward models for implicit anti-AAL dialect biases. 📊 (3/10)
March 6, 2025 at 7:49 PM
We introduce morphosyntactic & phonological features of AAL into WME texts from the RewardBench dataset using validated automatic translation methods. Then, we test 17 reward models for implicit anti-AAL dialect biases. 📊 (3/10)
Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)

March 6, 2025 at 7:49 PM
Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)