



Jacob Springer
@jacobspringer.bsky.social
Machine Learning (the science part) | PhD student @ CMU
Fine-tuning behaves similarly: using a fixed learning rate across different pre-training checkpoints, we see eventual degradation in both task performance and web-data perplexity. This often holds even after hyperparameter tuning. Overtraining = worse fine-tuning outcomes!
8/10
8/10

March 26, 2025 at 6:35 PM
Fine-tuning behaves similarly: using a fixed learning rate across different pre-training checkpoints, we see eventual degradation in both task performance and web-data perplexity. This often holds even after hyperparameter tuning. Overtraining = worse fine-tuning outcomes!
8/10
8/10
👉 Early in training: Models have low sensitivity & the base model improves quickly; performance improves 📈
👉 Late in training: Models become highly sensitive & the base model improves slowly; performance degrades! 📉
7/10
👉 Late in training: Models become highly sensitive & the base model improves slowly; performance degrades! 📉
7/10

March 26, 2025 at 6:35 PM
👉 Early in training: Models have low sensitivity & the base model improves quickly; performance improves 📈
👉 Late in training: Models become highly sensitive & the base model improves slowly; performance degrades! 📉
7/10
👉 Late in training: Models become highly sensitive & the base model improves slowly; performance degrades! 📉
7/10
🔹 Early checkpoints: Robust to parameter changes.
🔸 Later checkpoints: Highly sensitive, leading to worse performance after perturbation! (Left plot: sensitivity increases over training, Right plot: final performance eventually degrades.)
5/10
🔸 Later checkpoints: Highly sensitive, leading to worse performance after perturbation! (Left plot: sensitivity increases over training, Right plot: final performance eventually degrades.)
5/10

March 26, 2025 at 6:35 PM
🔹 Early checkpoints: Robust to parameter changes.
🔸 Later checkpoints: Highly sensitive, leading to worse performance after perturbation! (Left plot: sensitivity increases over training, Right plot: final performance eventually degrades.)
5/10
🔸 Later checkpoints: Highly sensitive, leading to worse performance after perturbation! (Left plot: sensitivity increases over training, Right plot: final performance eventually degrades.)
5/10
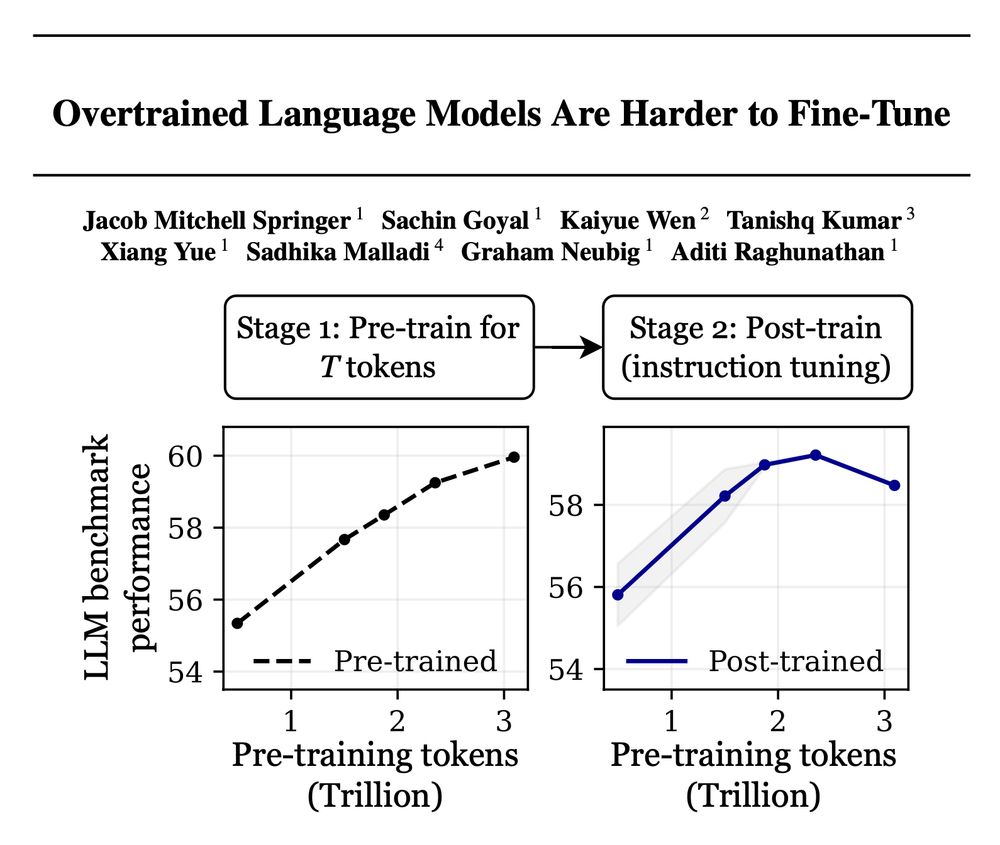
Example: OLMo-1B trained on 3T tokens performs over 2% *worse* after instruction tuning than its 2.3T-token version—even though it saw 30% more data! We see similar observations for many other post-training setups.
Why does extended pre-training hurt fine-tuning performance? 🤔
3/10
Why does extended pre-training hurt fine-tuning performance? 🤔
3/10

March 26, 2025 at 6:35 PM
Example: OLMo-1B trained on 3T tokens performs over 2% *worse* after instruction tuning than its 2.3T-token version—even though it saw 30% more data! We see similar observations for many other post-training setups.
Why does extended pre-training hurt fine-tuning performance? 🤔
3/10
Why does extended pre-training hurt fine-tuning performance? 🤔
3/10
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
March 26, 2025 at 6:35 PM
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10