



Jacob Springer
@jacobspringer.bsky.social
Machine Learning (the science part) | PhD student @ CMU
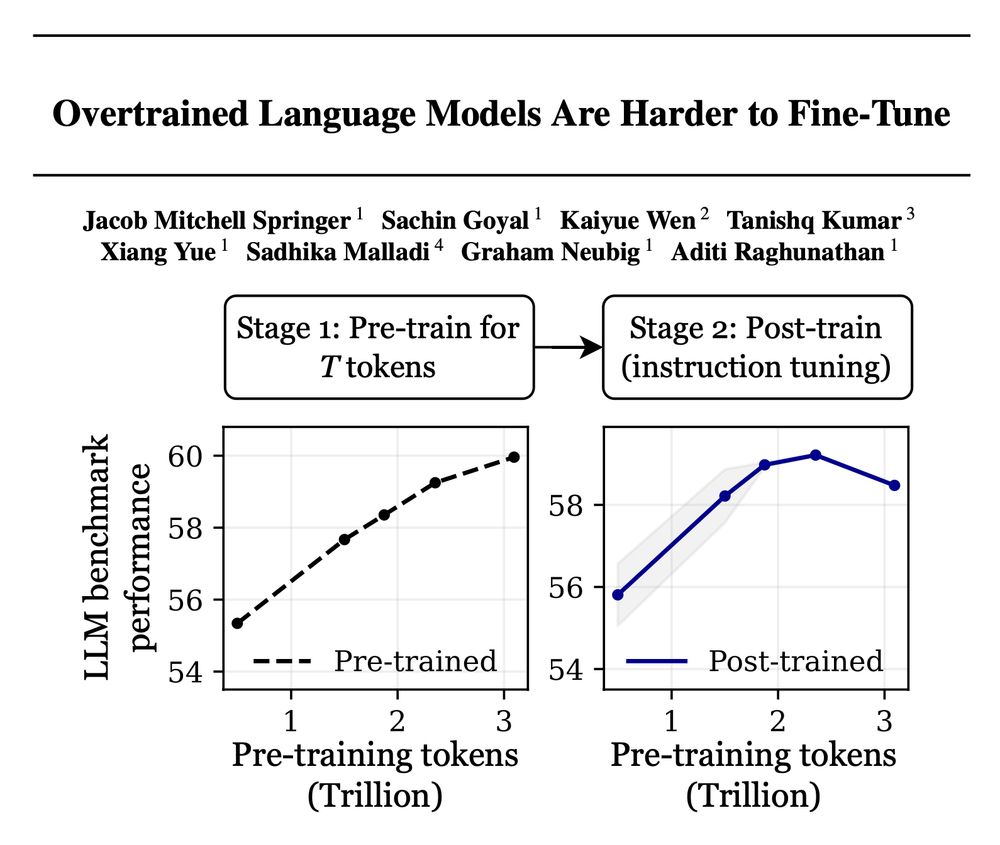
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
March 26, 2025 at 6:35 PM
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10