




Haiwen Huang
@haiwen-huang.bsky.social
PhD student in AI at University of Tuebingen.
Dreaming for a better world.
https://andrehuang.github.io/
Dreaming for a better world.
https://andrehuang.github.io/
Pinned
Haiwen Huang
@haiwen-huang.bsky.social
· Apr 22
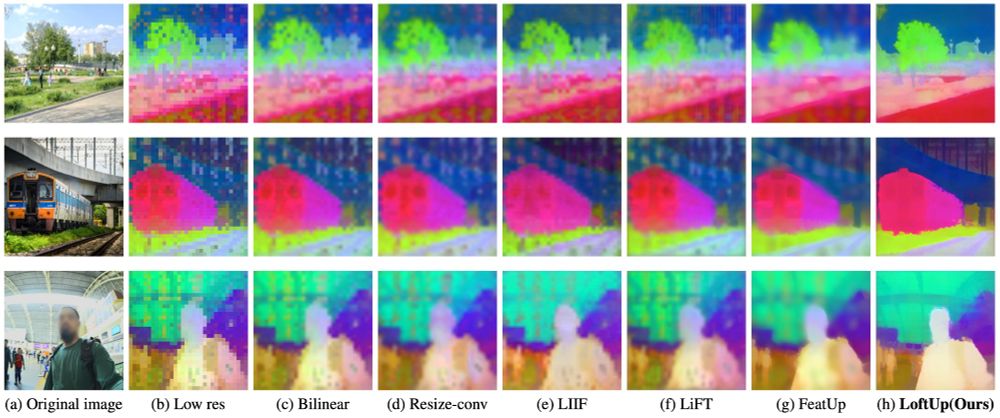
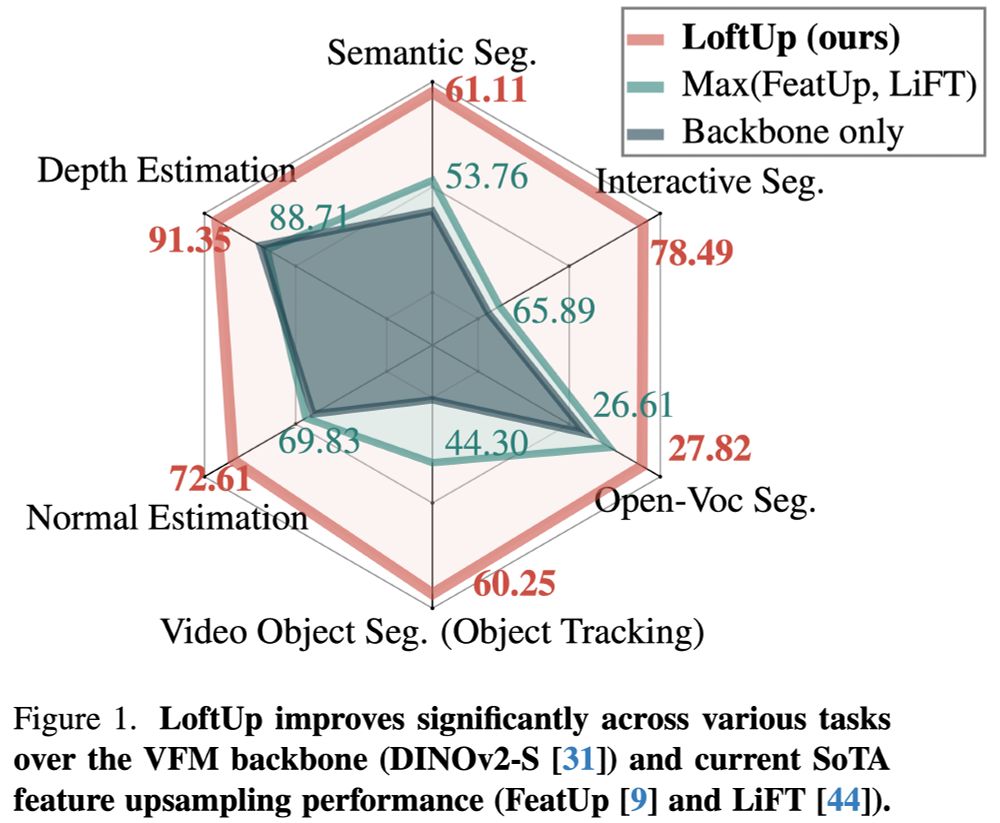
Excited to introduce LoftUp!
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
Happy to find that I've been selected as an Outstanding Reviewer for CVPR 2025!

Behind every great conference is a team of dedicated reviewers. Congratulations to this year’s #CVPR2025 Outstanding Reviewers!
cvpr.thecvf.com/Conferences/...
cvpr.thecvf.com/Conferences/...
May 11, 2025 at 12:44 PM
Happy to find that I've been selected as an Outstanding Reviewer for CVPR 2025!
Reposted by Haiwen Huang

📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
May 5, 2025 at 1:00 PM
📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Reposted by Haiwen Huang

⏰ Heads up! The deadline for two #CVPR2025 Autonomous Grand Challenge tracks is May 10th, 2025:
1️⃣ NAVSIM v2 Challenge: huggingface.co/spaces/AGC20...
2️⃣ World Model Challenge by 1X: huggingface.co/spaces/1x-te...
1️⃣ NAVSIM v2 Challenge: huggingface.co/spaces/AGC20...
2️⃣ World Model Challenge by 1X: huggingface.co/spaces/1x-te...

April 28, 2025 at 9:41 AM
⏰ Heads up! The deadline for two #CVPR2025 Autonomous Grand Challenge tracks is May 10th, 2025:
1️⃣ NAVSIM v2 Challenge: huggingface.co/spaces/AGC20...
2️⃣ World Model Challenge by 1X: huggingface.co/spaces/1x-te...
1️⃣ NAVSIM v2 Challenge: huggingface.co/spaces/AGC20...
2️⃣ World Model Challenge by 1X: huggingface.co/spaces/1x-te...
Reposted by Haiwen Huang

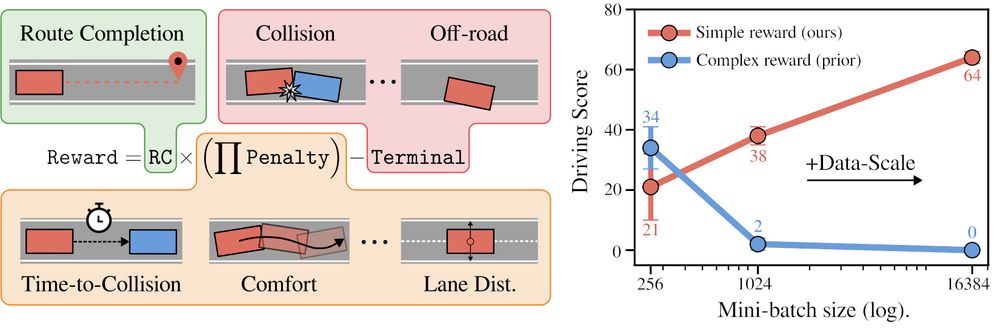
Introducing CaRL: Learning Scalable Planning Policies with Simple Rewards
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
April 28, 2025 at 3:17 PM
Introducing CaRL: Learning Scalable Planning Policies with Simple Rewards
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
Reposted by Haiwen Huang

Loft🆙 Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. We achieve SotA upsampling results for DINOv2. Paper and code:
andrehuang.github.io/loftup-site/
andrehuang.github.io/loftup-site/
April 26, 2025 at 2:47 PM
Loft🆙 Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. We achieve SotA upsampling results for DINOv2. Paper and code:
andrehuang.github.io/loftup-site/
andrehuang.github.io/loftup-site/
Sharing another video showing how LoftUp significantly improves DINOv2 features! Works like a charm!
Try it out:
Code: github.com/andrehuang/l...
Paper: arxiv.org/abs/2504.14032
Try it out:
Code: github.com/andrehuang/l...
Paper: arxiv.org/abs/2504.14032
April 26, 2025 at 7:52 AM
Sharing another video showing how LoftUp significantly improves DINOv2 features! Works like a charm!
Try it out:
Code: github.com/andrehuang/l...
Paper: arxiv.org/abs/2504.14032
Try it out:
Code: github.com/andrehuang/l...
Paper: arxiv.org/abs/2504.14032
Excited to introduce LoftUp!
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
April 22, 2025 at 7:55 AM
Excited to introduce LoftUp!
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
Reposted by Haiwen Huang

How much 3D do visual foundation models (VFMs) know?
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS
March 31, 2025 at 4:06 PM
How much 3D do visual foundation models (VFMs) know?
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS
Reposted by Haiwen Huang

🦣Easi3R: 4D Reconstruction Without Training!
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
April 1, 2025 at 3:21 PM
🦣Easi3R: 4D Reconstruction Without Training!
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
Reposted by Haiwen Huang
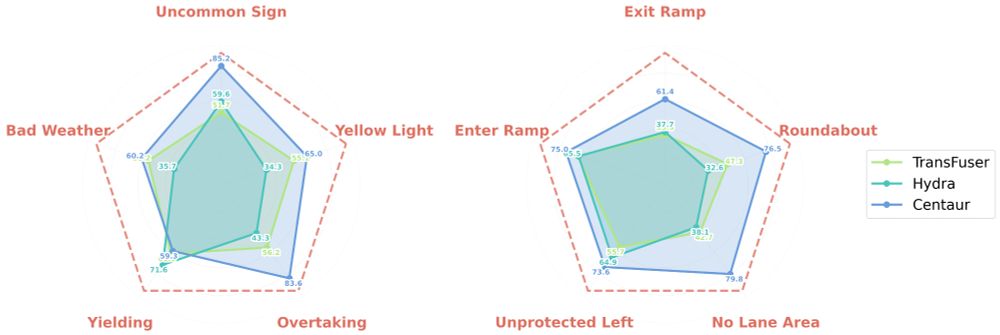
🐎 Centaur, our first foray into test-time training for end-to-end driving. No retraining needed, just plug-and-play at deployment given a trained model. Also, theoretically nearly no overhead in latency with some clever use of buffers. Surprising how effective this is! arxiv.org/abs/2503.11650
March 17, 2025 at 11:03 AM
🐎 Centaur, our first foray into test-time training for end-to-end driving. No retraining needed, just plug-and-play at deployment given a trained model. Also, theoretically nearly no overhead in latency with some clever use of buffers. Surprising how effective this is! arxiv.org/abs/2503.11650
Reposted by Haiwen Huang
🚀 Names matter! We show that better class names in open-vocabulary segmentation benchmarks greatly improve dataset quality and boost model performance. RENOVATE your dataset labels with our automatic framework! #AI #ComputerVision #NeurIPS24
andrehuang.github.io/renovate/
andrehuang.github.io/renovate/

February 26, 2025 at 2:45 PM
🚀 Names matter! We show that better class names in open-vocabulary segmentation benchmarks greatly improve dataset quality and boost model performance. RENOVATE your dataset labels with our automatic framework! #AI #ComputerVision #NeurIPS24
andrehuang.github.io/renovate/
andrehuang.github.io/renovate/
Reposted by Haiwen Huang
Synchronization is ubiquitous in nature and a key mechanism for information processing in the brain. We introduce AKOrN as a dynamical alternative to threshold units, which can be combined with MLPs, CNNs or Transformers. ICLR'25 Oral. Project page: takerum.github.io/akorn_projec...
February 12, 2025 at 2:07 PM
Synchronization is ubiquitous in nature and a key mechanism for information processing in the brain. We introduce AKOrN as a dynamical alternative to threshold units, which can be combined with MLPs, CNNs or Transformers. ICLR'25 Oral. Project page: takerum.github.io/akorn_projec...
Reposted by Haiwen Huang
This week we had our winter retreat jointly with Daniel Cremer's group in Montafon, Austria. 46 talks, 100 Km of slopes and night sledding with some occasionally lost and found. It has been fun!




January 16, 2025 at 5:50 PM
This week we had our winter retreat jointly with Daniel Cremer's group in Montafon, Austria. 46 talks, 100 Km of slopes and night sledding with some occasionally lost and found. It has been fun!