




PhD Student at Westlake University. 3D/4D Reconstruction, Virtual Humans.
fanegg.github.io

🔗Page: fanegg.github.io/Human3R
📄Paper: arxiv.org/abs/2510.06219
💻Code: github.com/fanegg/Human3R
Big thanks to our awesome team!
@fanegg.bsky.social @xingyu-chen.bsky.social Yuxuan Xue @apchen.bsky.social @xiuyuliang.bsky.social Gerard Pons-Moll
This is achieved by reading out humans from a 4D foundation model, #CUT3R, with our proposed 𝙝𝙪𝙢𝙖𝙣 𝙥𝙧𝙤𝙢𝙥𝙩 𝙩𝙪𝙣𝙞𝙣𝙜.
Our human tokens capture ID+ shape + pose + position of human, unlocking 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴-𝗳𝗿𝗲𝗲 4D tracking.
Just input a RGB video, we online reconstruct 4D humans and scene in 𝗢𝗻𝗲 model and 𝗢𝗻𝗲 stage.
Training this versatile model is easier than you think – it just takes 𝗢𝗻𝗲 day using 𝗢𝗻𝗲 GPU!
🔗Page: fanegg.github.io/Human3R/
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
Reposted by Yue Chen

TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
Reposted by Yue Chen

Reposted by Yue Chen

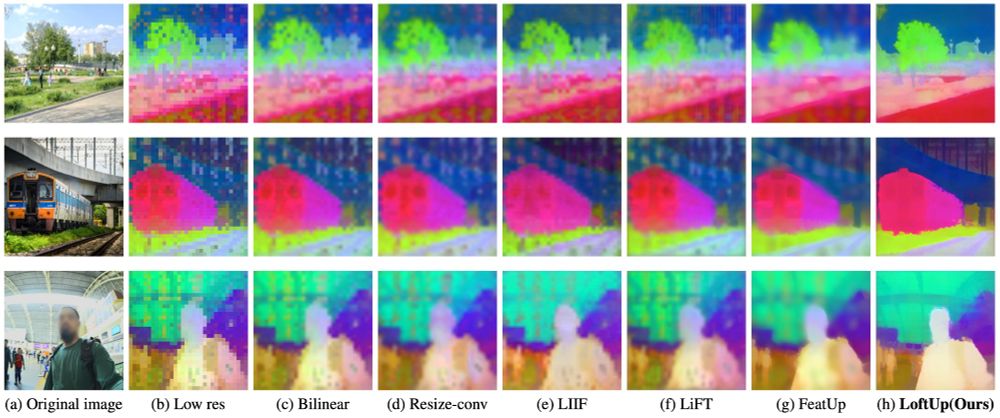
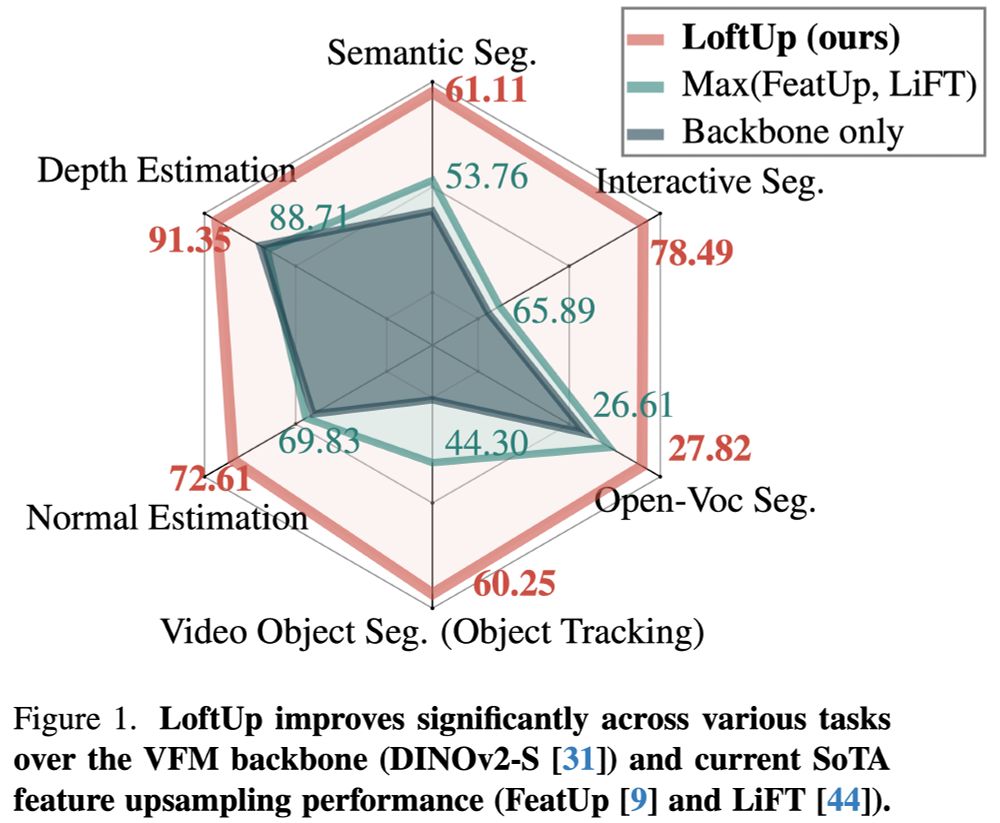
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
Reposted by Yue Chen
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io

🎥Video: youtu.be/4fT5lzcAJqo?...
Big thanks to the amazing team!
@fanegg.bsky.social, @xingyu-chen.bsky.social, Anpei Chen, Gerard Pons-Moll, Yuliang Xiu
#DUSt3R #MASt3R #MiDaS #DINOv2 #DINO #SAM #CLIP #RADIO #MAE #StableDiffusion #Zero123
Apply #Feat2GS in sparse & causal captures:
🤗Online Demo: huggingface.co/spaces/endle...
📄Paper: arxiv.org/abs/2412.09606
🔍Try it NOW: fanegg.github.io/Feat2GS/#chart
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS