




Gregor Diensthuber
@gdiensthuber.bsky.social
PhD student @NovoaLab @CRGenomica |Wet-Lab 🔁 Dry-Lab | RNA modifications | Method Development 🧬⚒
Finally, we established that a combination of alignment and current features still presents a robust way of detecting RNA modifications with RNA004, as demonstrated on E.coli strains knockout for certain mod writers. (11/12)

July 14, 2025 at 4:00 PM
Finally, we established that a combination of alignment and current features still presents a robust way of detecting RNA modifications with RNA004, as demonstrated on E.coli strains knockout for certain mod writers. (11/12)
While IVTs helped remove sequence-specific FPs two classes of FPs remained: I) cross-reactive mods found on the same base, and II) mods at adjacent positions (+/- 1nt) from identified FP sites, which cannot be accounted for with existing methods. (10/12)

July 14, 2025 at 4:00 PM
While IVTs helped remove sequence-specific FPs two classes of FPs remained: I) cross-reactive mods found on the same base, and II) mods at adjacent positions (+/- 1nt) from identified FP sites, which cannot be accounted for with existing methods. (10/12)
Considering the substantial amount of FPs observed at unannotated sites we reasoned that the use of IVT controls might be necessary to help remove sequence specific FPs. (9/12)

July 14, 2025 at 4:00 PM
Considering the substantial amount of FPs observed at unannotated sites we reasoned that the use of IVT controls might be necessary to help remove sequence specific FPs. (9/12)
From there we moved to rRNAs for benchmarking since accurate mod. maps exist for well-studied species. We could recapitulate most Ψ and m5C sites while also observing substantial FP, especially at base methylations and unannotated sites. (8/12)

July 14, 2025 at 4:00 PM
From there we moved to rRNAs for benchmarking since accurate mod. maps exist for well-studied species. We could recapitulate most Ψ and m5C sites while also observing substantial FP, especially at base methylations and unannotated sites. (8/12)
Moving to per-site predictions (removing per read estimates that fall below the default cutoff), we observe that most models slightly underpredict the per-site stoichiometries with the pseU model performing the most accurate (particularly in the 0-25% modified range). (7/12)

July 14, 2025 at 4:00 PM
Moving to per-site predictions (removing per read estimates that fall below the default cutoff), we observe that most models slightly underpredict the per-site stoichiometries with the pseU model performing the most accurate (particularly in the 0-25% modified range). (7/12)
Digging a bit deeper, we can identify particular sets of sequences (5mer) that produce lower probability estimates than the remaining ones, suggesting a strong impact of the sequence context on predictions. (6/12)

July 14, 2025 at 4:00 PM
Digging a bit deeper, we can identify particular sets of sequences (5mer) that produce lower probability estimates than the remaining ones, suggesting a strong impact of the sequence context on predictions. (6/12)
Key observations (per-read): 1) in general, models perform well. 2) Ψ and m1Ψ are indistinguishable. 3) m5C and hm5C cross-react in particular sequence contexts as indicated by the bimodal distribution of hm5C called with the m5C model. (5/12)

July 14, 2025 at 4:00 PM
Key observations (per-read): 1) in general, models perform well. 2) Ψ and m1Ψ are indistinguishable. 3) m5C and hm5C cross-react in particular sequence contexts as indicated by the bimodal distribution of hm5C called with the m5C model. (5/12)
But first, a quick word on mod-aware basecallers and the information they provide. The models make predictions on a per-read and position basis (per-read) which can then be collapsed into per-site predictions, using downstream tools which consider a certain filter-threshold (per-site).

July 14, 2025 at 4:00 PM
But first, a quick word on mod-aware basecallers and the information they provide. The models make predictions on a per-read and position basis (per-read) which can then be collapsed into per-site predictions, using downstream tools which consider a certain filter-threshold (per-site).
Next we went ahead and sequenced synthetic oligos containing all possible 5mers (n=1024) to assess model performance, cross-reactivities and potential sequence biases. (3/12)

July 14, 2025 at 4:00 PM
Next we went ahead and sequenced synthetic oligos containing all possible 5mers (n=1024) to assess model performance, cross-reactivities and potential sequence biases. (3/12)
First things first, we updated SeqTagger to support 96 barcodes with the newest sequencing chemistry (RNA004). If you are interested in multiplexing your own DRS runs the new model is openly available here -> github.com/novoalab/Seq.... Feedback is very welcome! (2/12)

July 14, 2025 at 4:00 PM
First things first, we updated SeqTagger to support 96 barcodes with the newest sequencing chemistry (RNA004). If you are interested in multiplexing your own DRS runs the new model is openly available here -> github.com/novoalab/Seq.... Feedback is very welcome! (2/12)
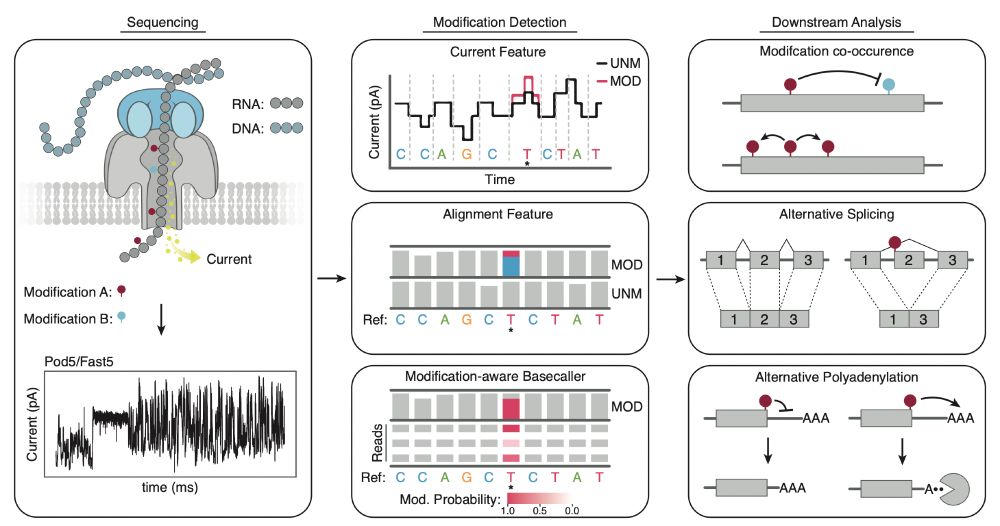
How has native RNA sequencing contributed to epitranscriptomic research? This is one of the main questions we addressed in our recent review by @evamarianovoa.bsky.social and I now live in Molecular Cell #RNAsky #RNA #nanopore
authors.elsevier.com/a/1kS2f3vVUP...
authors.elsevier.com/a/1kS2f3vVUP...
January 20, 2025 at 4:07 PM
How has native RNA sequencing contributed to epitranscriptomic research? This is one of the main questions we addressed in our recent review by @evamarianovoa.bsky.social and I now live in Molecular Cell #RNAsky #RNA #nanopore
authors.elsevier.com/a/1kS2f3vVUP...
authors.elsevier.com/a/1kS2f3vVUP...