



Matheus Gadelha
@gadelha.bsky.social
Research Scientist at Adobe Research. ML/3D/Graphics. http://mgadelha.me
This example should convey what we are doing pretty well: just starting from different noises will not lead to diverse *object motions*.
More results in the website: motionmodes.github.io
More results in the website: motionmodes.github.io
December 3, 2024 at 6:15 PM
This example should convey what we are doing pretty well: just starting from different noises will not lead to diverse *object motions*.
More results in the website: motionmodes.github.io
More results in the website: motionmodes.github.io
And if you also want color, the model can give you texture

November 22, 2024 at 5:15 AM
And if you also want color, the model can give you texture
You can turn the same shape into a chess horse piece or a gorilla

November 22, 2024 at 5:15 AM
You can turn the same shape into a chess horse piece or a gorilla
Now you can generate more teddy bears and control their pose using the base shape!

November 22, 2024 at 5:15 AM
Now you can generate more teddy bears and control their pose using the base shape!
Our solution is to train a multi-view diffusion model that, given multi-view normal renderings and one RGB rendering (guide image), outputs refined multi-view normals + RGB renderings.

November 22, 2024 at 5:15 AM
Our solution is to train a multi-view diffusion model that, given multi-view normal renderings and one RGB rendering (guide image), outputs refined multi-view normals + RGB renderings.
For example, from three spheres, we can create a mouse that an off-the-shelf normal estimator will recognize as having several features not present in the original spheres (eyes, nose, mouth, ears, etc.).

November 22, 2024 at 5:15 AM
For example, from three spheres, we can create a mouse that an off-the-shelf normal estimator will recognize as having several features not present in the original spheres (eyes, nose, mouth, ears, etc.).
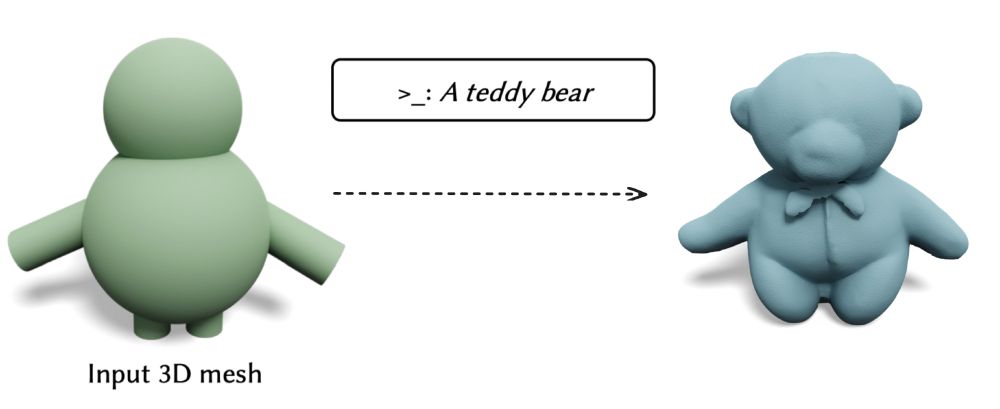
Our upcoming SIGGRAPH Asia paper explores refining 3D shapes using text descriptions. For example, we transform the spheres and cylinders on the left into a detailed teddy bear! 🧸
Read on for more details in the thread! 👇
Read on for more details in the thread! 👇
November 22, 2024 at 5:15 AM
Our upcoming SIGGRAPH Asia paper explores refining 3D shapes using text descriptions. For example, we transform the spheres and cylinders on the left into a detailed teddy bear! 🧸
Read on for more details in the thread! 👇
Read on for more details in the thread! 👇