



Florian Schneider
@floschne-nlp.bsky.social
he/him
3rd and final year PhD Student
Researching on the applications and limitations of multimodal transformer encoder and decoder models.
3rd and final year PhD Student
Researching on the applications and limitations of multimodal transformer encoder and decoder models.
Reposted by Florian Schneider

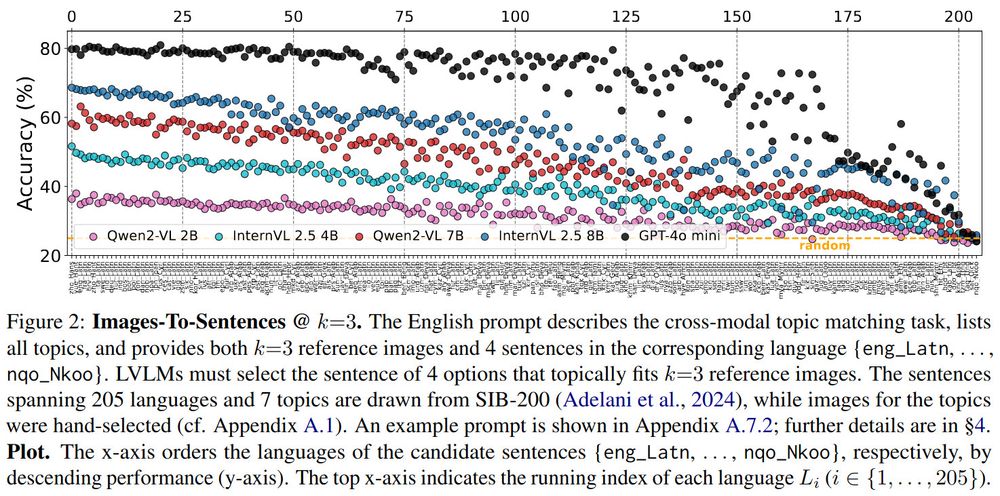
Strong vision-language models (VLMs) like GPT-4o-mini maintain good performance for top-150 languages, only to drop to performing no better than chance for the lowest resource languages!
February 21, 2025 at 7:46 AM
Strong vision-language models (VLMs) like GPT-4o-mini maintain good performance for top-150 languages, only to drop to performing no better than chance for the lowest resource languages!
Reposted by Florian Schneider
X-modal to text-only perf. *gap* shows that VL support decreases from high to low-resource language tiers:
Images/Topic→Sentence (for I/T, pick S): narrows with less textual support (left)
Sentences→Image/Topic (for S, pick I/T): increases with less VL support worse (right)
Images/Topic→Sentence (for I/T, pick S): narrows with less textual support (left)
Sentences→Image/Topic (for S, pick I/T): increases with less VL support worse (right)

February 21, 2025 at 7:46 AM
X-modal to text-only perf. *gap* shows that VL support decreases from high to low-resource language tiers:
Images/Topic→Sentence (for I/T, pick S): narrows with less textual support (left)
Sentences→Image/Topic (for S, pick I/T): increases with less VL support worse (right)
Images/Topic→Sentence (for I/T, pick S): narrows with less textual support (left)
Sentences→Image/Topic (for S, pick I/T): increases with less VL support worse (right)
Reposted by Florian Schneider
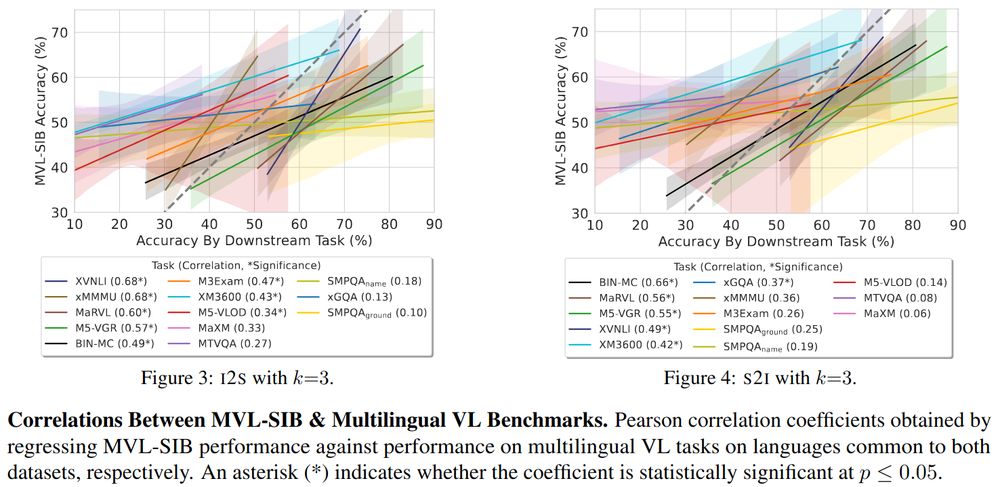
Cross-modal topic matching correlates well with other multilingual vision-language tasks!
🤗Images-To-Sentence (given Images, select topically fitting sentence) & Sentences-To-Image (given Sentences, pick topically matching image) probe complementary aspects in VLU
🤗Images-To-Sentence (given Images, select topically fitting sentence) & Sentences-To-Image (given Sentences, pick topically matching image) probe complementary aspects in VLU
February 21, 2025 at 7:46 AM
Cross-modal topic matching correlates well with other multilingual vision-language tasks!
🤗Images-To-Sentence (given Images, select topically fitting sentence) & Sentences-To-Image (given Sentences, pick topically matching image) probe complementary aspects in VLU
🤗Images-To-Sentence (given Images, select topically fitting sentence) & Sentences-To-Image (given Sentences, pick topically matching image) probe complementary aspects in VLU