


Special thanks to @maosbot.bsky.social for all the support and encouragement!
October 6, 2025 at 4:40 PM
Special thanks to @maosbot.bsky.social for all the support and encouragement!
Much credit to my wonderful TA's🙌:
@hunarbatra.bsky.social
Matthew Farrugia-Roberts
(Head TA) and
@jamesaoldfield.bsky.social
🎟 We also have the wonderful
Marta Ziosi
asa guest tutorial speaker on AI governance and regulations!
@hunarbatra.bsky.social
Matthew Farrugia-Roberts
(Head TA) and
@jamesaoldfield.bsky.social
🎟 We also have the wonderful
Marta Ziosi
asa guest tutorial speaker on AI governance and regulations!
October 6, 2025 at 4:40 PM
Much credit to my wonderful TA's🙌:
@hunarbatra.bsky.social
Matthew Farrugia-Roberts
(Head TA) and
@jamesaoldfield.bsky.social
🎟 We also have the wonderful
Marta Ziosi
asa guest tutorial speaker on AI governance and regulations!
@hunarbatra.bsky.social
Matthew Farrugia-Roberts
(Head TA) and
@jamesaoldfield.bsky.social
🎟 We also have the wonderful
Marta Ziosi
asa guest tutorial speaker on AI governance and regulations!
🔥 We’re lucky to host world-class guest lecturers:
•
@yoshuabengio.bsky.social
– Université de Montréal, Mila, LawZero
•
@neelnanda.bsky.social
Google DeepMind
•
Joslyn Barnhart
Google DeepMind
•
Robert Trager
– Oxford Martin AI Governance Initiative
•
@yoshuabengio.bsky.social
– Université de Montréal, Mila, LawZero
•
@neelnanda.bsky.social
Google DeepMind
•
Joslyn Barnhart
Google DeepMind
•
Robert Trager
– Oxford Martin AI Governance Initiative
October 6, 2025 at 4:40 PM
🔥 We’re lucky to host world-class guest lecturers:
•
@yoshuabengio.bsky.social
– Université de Montréal, Mila, LawZero
•
@neelnanda.bsky.social
Google DeepMind
•
Joslyn Barnhart
Google DeepMind
•
Robert Trager
– Oxford Martin AI Governance Initiative
•
@yoshuabengio.bsky.social
– Université de Montréal, Mila, LawZero
•
@neelnanda.bsky.social
Google DeepMind
•
Joslyn Barnhart
Google DeepMind
•
Robert Trager
– Oxford Martin AI Governance Initiative
We’ll cover:
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy

October 6, 2025 at 4:40 PM
We’ll cover:
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy
🔑 What it is:
An AIMS CDT course with 15 h of lectures + 15 h of labs
💡 Lectures are open to all Oxford students, and we’ll do our best to record & make them publicly available.
An AIMS CDT course with 15 h of lectures + 15 h of labs
💡 Lectures are open to all Oxford students, and we’ll do our best to record & make them publicly available.
October 6, 2025 at 4:40 PM
🔑 What it is:
An AIMS CDT course with 15 h of lectures + 15 h of labs
💡 Lectures are open to all Oxford students, and we’ll do our best to record & make them publicly available.
An AIMS CDT course with 15 h of lectures + 15 h of labs
💡 Lectures are open to all Oxford students, and we’ll do our best to record & make them publicly available.
Reposted by Fazl Barez

Other works have highlighted that CoTs ≠ explainability alphaxiv.org/abs/2025.02 (@fbarez.bsky.social), and that intermediate (CoT) tokens ≠ reasoning traces arxiv.org/abs/2504.09762 (@rao2z.bsky.social).
Here, FUR offers a fine-grained test if LMs latently used information from CoTs for answers!
Here, FUR offers a fine-grained test if LMs latently used information from CoTs for answers!
Chain-of-Thought Is Not Explainability | alphaXiv
View 3 comments: There should be a balance of both subjective and observable methodologies. Adhering to just one is a fools errand.
alphaxiv.org
August 21, 2025 at 3:21 PM
Other works have highlighted that CoTs ≠ explainability alphaxiv.org/abs/2025.02 (@fbarez.bsky.social), and that intermediate (CoT) tokens ≠ reasoning traces arxiv.org/abs/2504.09762 (@rao2z.bsky.social).
Here, FUR offers a fine-grained test if LMs latently used information from CoTs for answers!
Here, FUR offers a fine-grained test if LMs latently used information from CoTs for answers!
Link to the paper www.alphaxiv.org/abs/2025.02
www.alphaxiv.org
July 2, 2025 at 7:33 AM
Link to the paper www.alphaxiv.org/abs/2025.02
@alasdair-p.bsky.social, @adelbibi.bsky.social , Robert Trager, Damiano Fornasiere, @john-yan.bsky.social , @yanai.bsky.social@yoshuabengio.bsky.social

July 1, 2025 at 3:41 PM
@alasdair-p.bsky.social, @adelbibi.bsky.social , Robert Trager, Damiano Fornasiere, @john-yan.bsky.social , @yanai.bsky.social@yoshuabengio.bsky.social
Work done with my wonderful collaborators @tonywu1105.bsky.social Iván Arcuschin, @bearraptor, Vincent Wang, @noahysiegel.bsky.social , N. Collignon, C. Neo, @wordscompute.bsky.social pute.bsky.social
https://pute.bsky.social
July 1, 2025 at 3:41 PM
Work done with my wonderful collaborators @tonywu1105.bsky.social Iván Arcuschin, @bearraptor, Vincent Wang, @noahysiegel.bsky.social , N. Collignon, C. Neo, @wordscompute.bsky.social pute.bsky.social
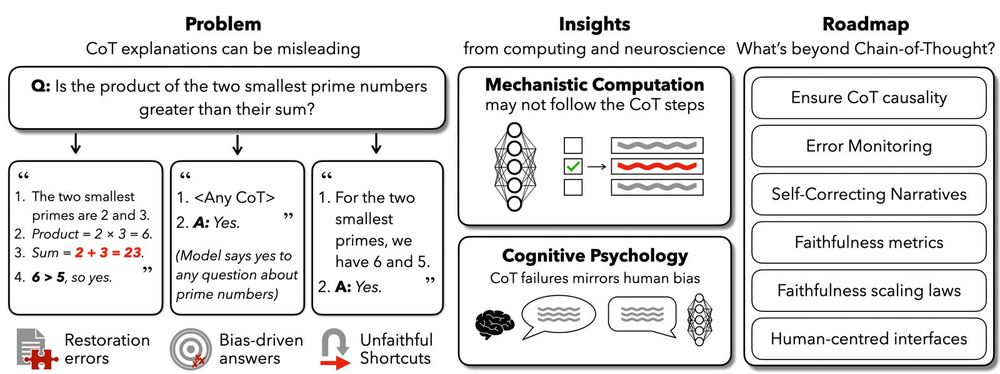
Bottom line: CoT can be useful but should never be mistaken for genuine interpretability. Ensuring trustworthy explanations requires rigorous validation and deeper insight into model internals, which is especially critical as AI scales up in high-stakes domains. (9/9) 📖✨
July 1, 2025 at 3:41 PM
Bottom line: CoT can be useful but should never be mistaken for genuine interpretability. Ensuring trustworthy explanations requires rigorous validation and deeper insight into model internals, which is especially critical as AI scales up in high-stakes domains. (9/9) 📖✨
Inspired by cognitive science, we suggest strategies like error monitoring, self-correcting narratives, and dual-process reasoning (intuitive + reflective steps). Enhanced human oversight tools are also critical to interpret and verify model reasoning. (8/9)
July 1, 2025 at 3:41 PM
Inspired by cognitive science, we suggest strategies like error monitoring, self-correcting narratives, and dual-process reasoning (intuitive + reflective steps). Enhanced human oversight tools are also critical to interpret and verify model reasoning. (8/9)
We suggest treating CoT as complementary rather than sufficient for interpretability, developing rigorous methods to verify CoT faithfulness, and applying causal validation techniques like activation patching, counterfactual checks, and verifier models. (7/9)
July 1, 2025 at 3:41 PM
We suggest treating CoT as complementary rather than sufficient for interpretability, developing rigorous methods to verify CoT faithfulness, and applying causal validation techniques like activation patching, counterfactual checks, and verifier models. (7/9)
Why does this disconnect occur? One possibility is that models process information via distributed, parallel computations. Yet CoT presents reasoning as a sequential narrative. This fundamental mismatch leads to inherently unfaithful explanations. (6/9)
July 1, 2025 at 3:41 PM
Why does this disconnect occur? One possibility is that models process information via distributed, parallel computations. Yet CoT presents reasoning as a sequential narrative. This fundamental mismatch leads to inherently unfaithful explanations. (6/9)
Another red flag: models often silently correct errors within their reasoning steps. They may produce the correct final answer by reasoning steps that are not verbalised, while the steps they do verbalise remain flawed, creating an illusion of transparency. (5/9)
July 1, 2025 at 3:41 PM
Another red flag: models often silently correct errors within their reasoning steps. They may produce the correct final answer by reasoning steps that are not verbalised, while the steps they do verbalise remain flawed, creating an illusion of transparency. (5/9)
Alarmingly, explicit prompt biases can easily sway model answers without ever being mentioned in their explanations. Models rationalize biased answers convincingly, yet fail to disclose these hidden influences. Trusting such rationales can be dangerous. (4/9)
July 1, 2025 at 3:41 PM
Alarmingly, explicit prompt biases can easily sway model answers without ever being mentioned in their explanations. Models rationalize biased answers convincingly, yet fail to disclose these hidden influences. Trusting such rationales can be dangerous. (4/9)
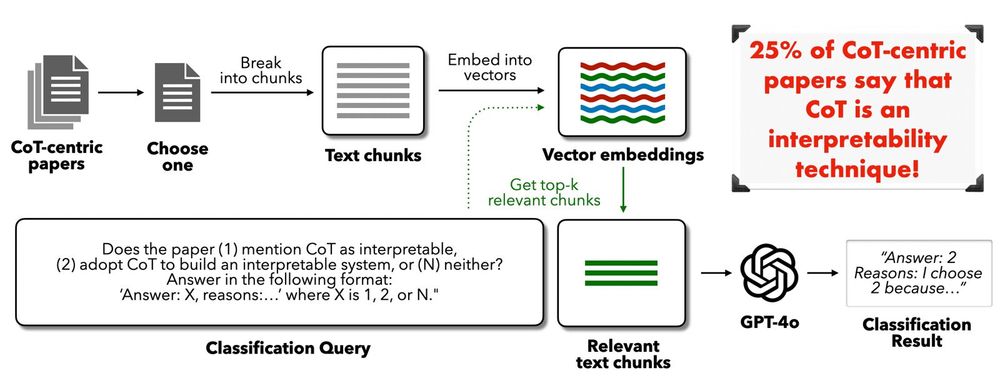
Our analysis shows high-stakes domains often rely on CoT explanations: ~38% of medical AI, 25% of AI for law, and 63% of autonomous vehicle papers using CoT misclaim it as interpretability. Misplaced trust here risks serious real-world consequences. (3/9)
July 1, 2025 at 3:41 PM
Our analysis shows high-stakes domains often rely on CoT explanations: ~38% of medical AI, 25% of AI for law, and 63% of autonomous vehicle papers using CoT misclaim it as interpretability. Misplaced trust here risks serious real-world consequences. (3/9)
Language models can be prompted or trained to verbalize reasoning steps in their Chain of Thought (CoT). Despite prior work showing such reasoning can be unfaithful, we find that around 25% of recent CoT-centric papers still mistakenly claim CoT as an interpretability technique. (2/9)
July 1, 2025 at 3:41 PM
Language models can be prompted or trained to verbalize reasoning steps in their Chain of Thought (CoT). Despite prior work showing such reasoning can be unfaithful, we find that around 25% of recent CoT-centric papers still mistakenly claim CoT as an interpretability technique. (2/9)
Co-authored with: Isaac Friend, Keir Reid, Igor Krawczuk, Vincent Wang, @jakobmokander.bsky.social kander.bsky.social , @philiptorr.bsky.social , Julia C Morse and Robert Trager
Kander (@kander.bsky.social)
Malware malbec and gummie bears!
kander.bsky.social
June 27, 2025 at 8:07 AM
Co-authored with: Isaac Friend, Keir Reid, Igor Krawczuk, Vincent Wang, @jakobmokander.bsky.social kander.bsky.social , @philiptorr.bsky.social , Julia C Morse and Robert Trager
In our new paper, Toward Resisting AI-Enabled Authoritarianism, we propose some technical safeguards to push back:
🔒 Scalable privacy
🔍 Verifiable interpretability
🛡️ Adversarial user tools
🔒 Scalable privacy
🔍 Verifiable interpretability
🛡️ Adversarial user tools
June 27, 2025 at 8:07 AM
In our new paper, Toward Resisting AI-Enabled Authoritarianism, we propose some technical safeguards to push back:
🔒 Scalable privacy
🔍 Verifiable interpretability
🛡️ Adversarial user tools
🔒 Scalable privacy
🔍 Verifiable interpretability
🛡️ Adversarial user tools