



We’ll cover:
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy

October 6, 2025 at 4:40 PM
We’ll cover:
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy
1️⃣ The alignment problem -- foundations & present-day challenges
2️⃣ Frontier alignment methods & evaluation (RLHF, Constitutional AI, etc.)
3️⃣ Interpretability & monitoring incl. hands-on mech interp labs
4️⃣ Sociotechnical aspects of alignment, governance, risks, Economics of AI and policy
🚨New AI Safety Course
@aims_oxford
!
I’m thrilled to launch a new called AI Safety & Alignment (AISAA) course on the foundations & frontier research of making advanced AI systems safe and aligned at
@UniofOxford
what to expect 👇
robots.ox.ac.uk/~fazl/aisaa/
@aims_oxford
!
I’m thrilled to launch a new called AI Safety & Alignment (AISAA) course on the foundations & frontier research of making advanced AI systems safe and aligned at
@UniofOxford
what to expect 👇
robots.ox.ac.uk/~fazl/aisaa/

October 6, 2025 at 4:40 PM
🚨New AI Safety Course
@aims_oxford
!
I’m thrilled to launch a new called AI Safety & Alignment (AISAA) course on the foundations & frontier research of making advanced AI systems safe and aligned at
@UniofOxford
what to expect 👇
robots.ox.ac.uk/~fazl/aisaa/
@aims_oxford
!
I’m thrilled to launch a new called AI Safety & Alignment (AISAA) course on the foundations & frontier research of making advanced AI systems safe and aligned at
@UniofOxford
what to expect 👇
robots.ox.ac.uk/~fazl/aisaa/
@alasdair-p.bsky.social, @adelbibi.bsky.social , Robert Trager, Damiano Fornasiere, @john-yan.bsky.social , @yanai.bsky.social@yoshuabengio.bsky.social

July 1, 2025 at 3:41 PM
@alasdair-p.bsky.social, @adelbibi.bsky.social , Robert Trager, Damiano Fornasiere, @john-yan.bsky.social , @yanai.bsky.social@yoshuabengio.bsky.social
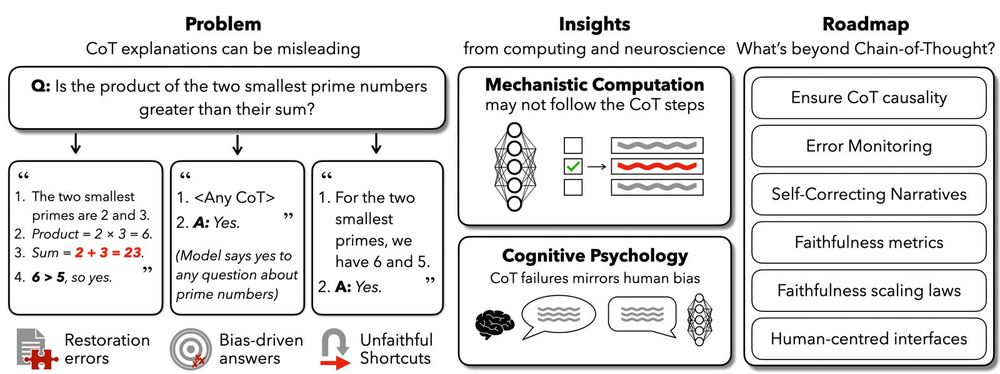
Bottom line: CoT can be useful but should never be mistaken for genuine interpretability. Ensuring trustworthy explanations requires rigorous validation and deeper insight into model internals, which is especially critical as AI scales up in high-stakes domains. (9/9) 📖✨
July 1, 2025 at 3:41 PM
Bottom line: CoT can be useful but should never be mistaken for genuine interpretability. Ensuring trustworthy explanations requires rigorous validation and deeper insight into model internals, which is especially critical as AI scales up in high-stakes domains. (9/9) 📖✨
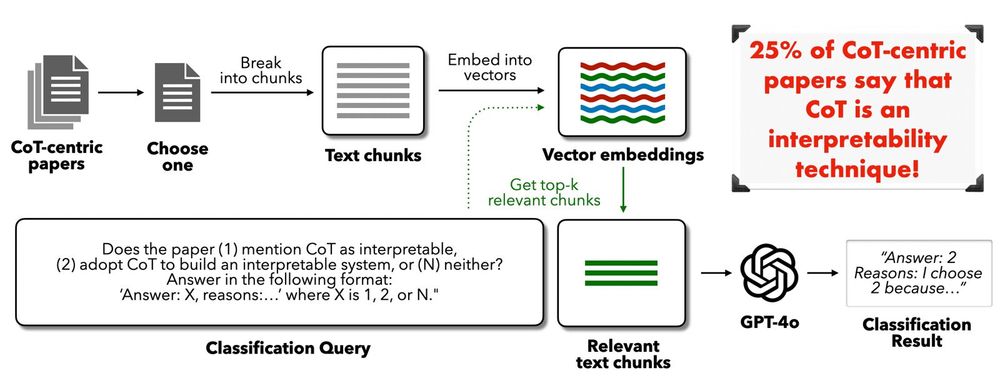
Language models can be prompted or trained to verbalize reasoning steps in their Chain of Thought (CoT). Despite prior work showing such reasoning can be unfaithful, we find that around 25% of recent CoT-centric papers still mistakenly claim CoT as an interpretability technique. (2/9)
July 1, 2025 at 3:41 PM
Language models can be prompted or trained to verbalize reasoning steps in their Chain of Thought (CoT). Despite prior work showing such reasoning can be unfaithful, we find that around 25% of recent CoT-centric papers still mistakenly claim CoT as an interpretability technique. (2/9)
Excited to share our paper: "Chain-of-Thought Is Not Explainability"! We unpack a critical misconception in AI: models explaining their steps (CoT) aren't necessarily revealing their true reasoning. Spoiler: the transparency can be an illusion. (1/9) 🧵

July 1, 2025 at 3:41 PM
Excited to share our paper: "Chain-of-Thought Is Not Explainability"! We unpack a critical misconception in AI: models explaining their steps (CoT) aren't necessarily revealing their true reasoning. Spoiler: the transparency can be an illusion. (1/9) 🧵
Technology = power. AI is reshaping power — fast.
Today’s AI doesn’t just assist decisions; it makes them. Governments use it for surveillance, prediction, and control — often with no oversight.
Technical safeguards aren’t enough on their own — but they’re essential for AI to serve society.
Today’s AI doesn’t just assist decisions; it makes them. Governments use it for surveillance, prediction, and control — often with no oversight.
Technical safeguards aren’t enough on their own — but they’re essential for AI to serve society.

June 27, 2025 at 8:07 AM
Technology = power. AI is reshaping power — fast.
Today’s AI doesn’t just assist decisions; it makes them. Governments use it for surveillance, prediction, and control — often with no oversight.
Technical safeguards aren’t enough on their own — but they’re essential for AI to serve society.
Today’s AI doesn’t just assist decisions; it makes them. Governments use it for surveillance, prediction, and control — often with no oversight.
Technical safeguards aren’t enough on their own — but they’re essential for AI to serve society.
🔍 Excited to share our paper: "Same Question, Different Words: A Latent Adversarial Framework for Prompt Robustness"!

March 4, 2025 at 5:24 PM
🔍 Excited to share our paper: "Same Question, Different Words: A Latent Adversarial Framework for Prompt Robustness"!
💡 Feature Similarity:
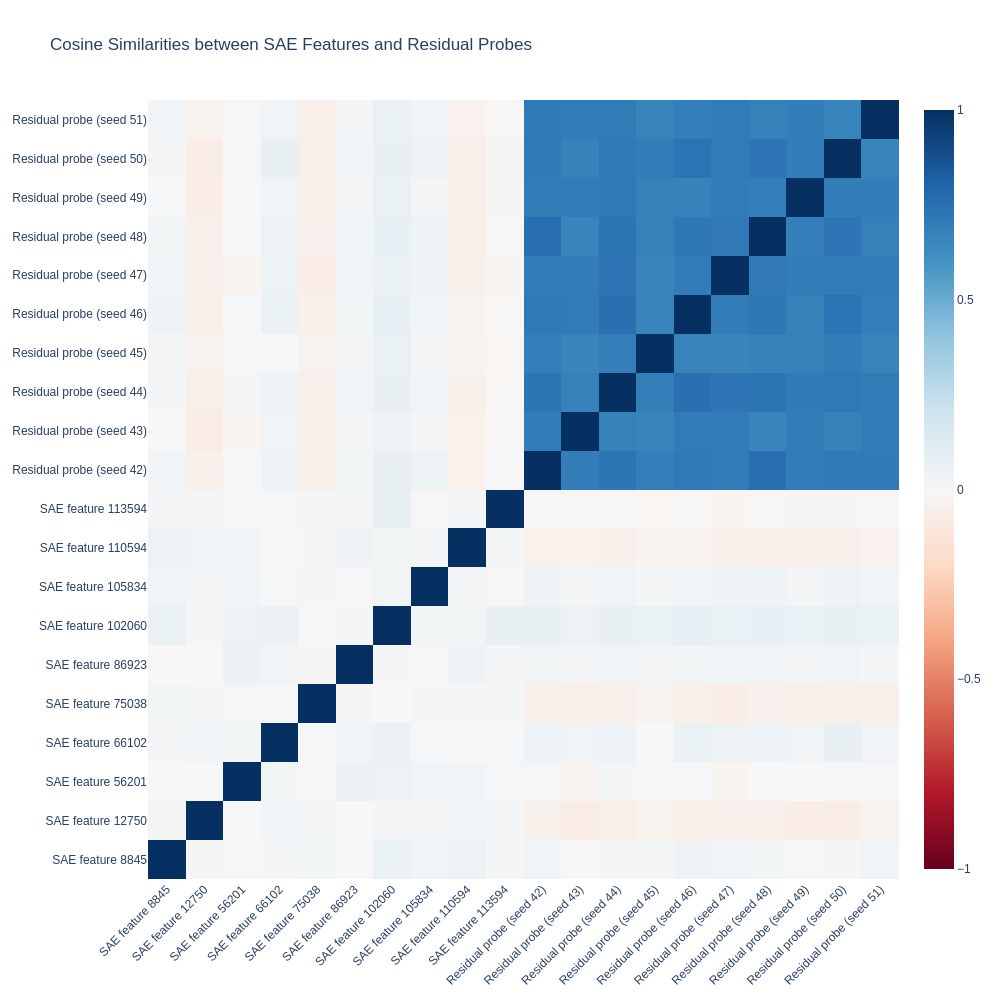
Cosine similarities reveal that linear probes learn highly similar features, while high-performing SAE features are often dissimilar. While individual SAE features are also dissimilar to the probes, combinations of SAE features are increasingly similar.
6/
Cosine similarities reveal that linear probes learn highly similar features, while high-performing SAE features are often dissimilar. While individual SAE features are also dissimilar to the probes, combinations of SAE features are increasingly similar.
6/

March 1, 2025 at 6:14 PM
💡 Feature Similarity:
Cosine similarities reveal that linear probes learn highly similar features, while high-performing SAE features are often dissimilar. While individual SAE features are also dissimilar to the probes, combinations of SAE features are increasingly similar.
6/
Cosine similarities reveal that linear probes learn highly similar features, while high-performing SAE features are often dissimilar. While individual SAE features are also dissimilar to the probes, combinations of SAE features are increasingly similar.
6/
🔍 Digging Deeper:
We analyzed combinations of SAE features. While increasing the number of features improves the in-domain performance (SQUAD), it doesn’t consistently improve generalization performance when compared to the best single SAE features.
5/
We analyzed combinations of SAE features. While increasing the number of features improves the in-domain performance (SQUAD), it doesn’t consistently improve generalization performance when compared to the best single SAE features.
5/

March 1, 2025 at 6:14 PM
🔍 Digging Deeper:
We analyzed combinations of SAE features. While increasing the number of features improves the in-domain performance (SQUAD), it doesn’t consistently improve generalization performance when compared to the best single SAE features.
5/
We analyzed combinations of SAE features. While increasing the number of features improves the in-domain performance (SQUAD), it doesn’t consistently improve generalization performance when compared to the best single SAE features.
5/
📊 Out-of-Distribution Insights:
Performance varies across domains:
• We find SAE features with strong generalization to the Equation, Celebrity, or IDK dataset, but no good generalization to BoolQ
• The probe trained on BoolQ fails to generalize, although decent SAE features exist
4/
Performance varies across domains:
• We find SAE features with strong generalization to the Equation, Celebrity, or IDK dataset, but no good generalization to BoolQ
• The probe trained on BoolQ fails to generalize, although decent SAE features exist
4/


March 1, 2025 at 6:14 PM
📊 Out-of-Distribution Insights:
Performance varies across domains:
• We find SAE features with strong generalization to the Equation, Celebrity, or IDK dataset, but no good generalization to BoolQ
• The probe trained on BoolQ fails to generalize, although decent SAE features exist
4/
Performance varies across domains:
• We find SAE features with strong generalization to the Equation, Celebrity, or IDK dataset, but no good generalization to BoolQ
• The probe trained on BoolQ fails to generalize, although decent SAE features exist
4/
🛠️ Our Approach:
We compare two probing methods at different layers (notably Layer 31):
• Linear probes trained on the residual stream, hitting ~90% accuracy in-domain
• Individual SAE features, reaching ~80% accuracy
3/
We compare two probing methods at different layers (notably Layer 31):
• Linear probes trained on the residual stream, hitting ~90% accuracy in-domain
• Individual SAE features, reaching ~80% accuracy
3/

March 1, 2025 at 6:14 PM
🛠️ Our Approach:
We compare two probing methods at different layers (notably Layer 31):
• Linear probes trained on the residual stream, hitting ~90% accuracy in-domain
• Individual SAE features, reaching ~80% accuracy
3/
We compare two probing methods at different layers (notably Layer 31):
• Linear probes trained on the residual stream, hitting ~90% accuracy in-domain
• Individual SAE features, reaching ~80% accuracy
3/
🔍 The Challenge:
LLMs sometimes confidently answer questions—even ones they can’t truly answer. We use three existing datasets (SQuAD, IDK, BoolQ), and two newly created synthetic datasets (Equations, and Celebrity Names) to quantify this behavior.
2/
LLMs sometimes confidently answer questions—even ones they can’t truly answer. We use three existing datasets (SQuAD, IDK, BoolQ), and two newly created synthetic datasets (Equations, and Celebrity Names) to quantify this behavior.
2/

March 1, 2025 at 6:14 PM
🔍 The Challenge:
LLMs sometimes confidently answer questions—even ones they can’t truly answer. We use three existing datasets (SQuAD, IDK, BoolQ), and two newly created synthetic datasets (Equations, and Celebrity Names) to quantify this behavior.
2/
LLMs sometimes confidently answer questions—even ones they can’t truly answer. We use three existing datasets (SQuAD, IDK, BoolQ), and two newly created synthetic datasets (Equations, and Celebrity Names) to quantify this behavior.
2/
New paper alert! 🚨
Important question: Do SAEs generalise?
We explore the answerability detection in LLMs by comparing SAE features vs. linear residual stream probes.
Answer:
probes outperform SAE features in-domain, out-of-domain generalization varies sharply between features and datasets. 🧵
Important question: Do SAEs generalise?
We explore the answerability detection in LLMs by comparing SAE features vs. linear residual stream probes.
Answer:
probes outperform SAE features in-domain, out-of-domain generalization varies sharply between features and datasets. 🧵

March 1, 2025 at 6:14 PM
New paper alert! 🚨
Important question: Do SAEs generalise?
We explore the answerability detection in LLMs by comparing SAE features vs. linear residual stream probes.
Answer:
probes outperform SAE features in-domain, out-of-domain generalization varies sharply between features and datasets. 🧵
Important question: Do SAEs generalise?
We explore the answerability detection in LLMs by comparing SAE features vs. linear residual stream probes.
Answer:
probes outperform SAE features in-domain, out-of-domain generalization varies sharply between features and datasets. 🧵
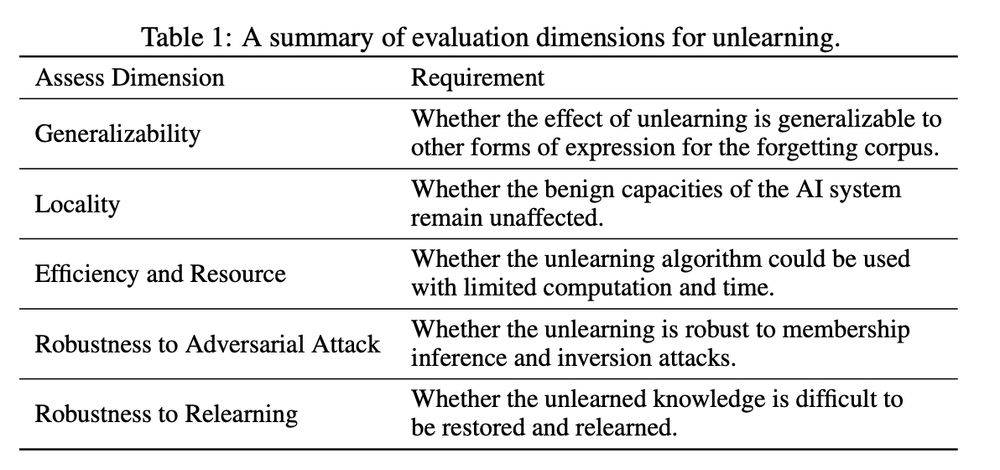
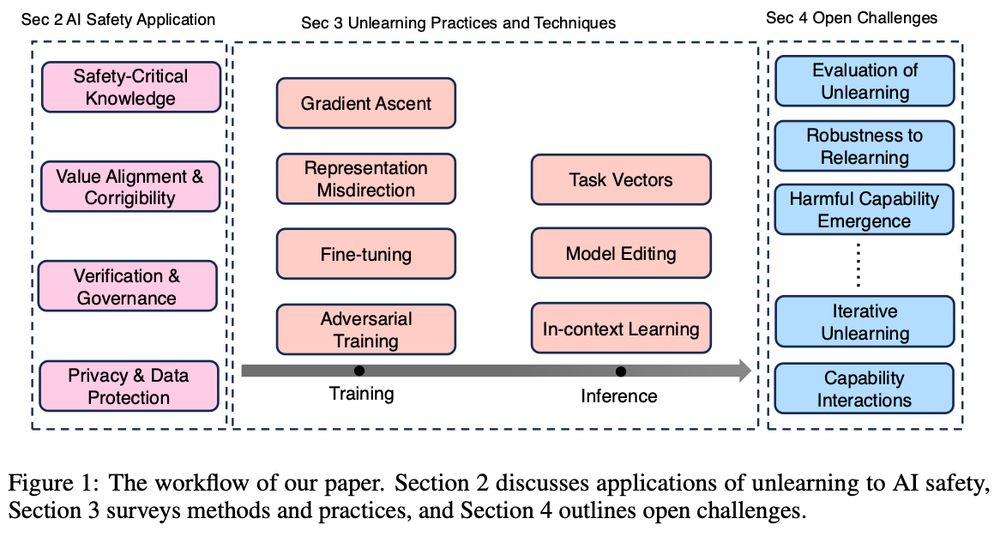
⚠️ Current unlearning tests fall short.
Models can pass tests yet retain harmful, emergent capabilities. These risks often surface in subtle, unexpected ways during extended interactions.
How can we evaluate major concerns e.g. the dual-use capabilities can emerge from beneficial data?
4/8
January 10, 2025 at 4:58 PM
⚠️ Current unlearning tests fall short.
Models can pass tests yet retain harmful, emergent capabilities. These risks often surface in subtle, unexpected ways during extended interactions.
How can we evaluate major concerns e.g. the dual-use capabilities can emerge from beneficial data?
4/8
💡 Key AI Safety Applications for Unlearning:
Managing safety-critical knowledge
Mitigating jailbreaks
Correcting value alignment
Ensuring privacy/legal compliance
But: Removing facts is easy; removing dangerous capabilities is HARD. Capabilities emerge from complex knowledge interactions.
3/8
Managing safety-critical knowledge
Mitigating jailbreaks
Correcting value alignment
Ensuring privacy/legal compliance
But: Removing facts is easy; removing dangerous capabilities is HARD. Capabilities emerge from complex knowledge interactions.
3/8
January 10, 2025 at 4:58 PM
💡 Key AI Safety Applications for Unlearning:
Managing safety-critical knowledge
Mitigating jailbreaks
Correcting value alignment
Ensuring privacy/legal compliance
But: Removing facts is easy; removing dangerous capabilities is HARD. Capabilities emerge from complex knowledge interactions.
3/8
Managing safety-critical knowledge
Mitigating jailbreaks
Correcting value alignment
Ensuring privacy/legal compliance
But: Removing facts is easy; removing dangerous capabilities is HARD. Capabilities emerge from complex knowledge interactions.
3/8
There's a crucial distinction between removing specific knowledge vs controlling capabilities. While you can make an AI "forget" certain facts, preventing it from reconstructing capabilities is much harder since they emerge from combining benign knowledge.
Real world example:
2a/8
Real world example:
2a/8
January 10, 2025 at 4:58 PM
There's a crucial distinction between removing specific knowledge vs controlling capabilities. While you can make an AI "forget" certain facts, preventing it from reconstructing capabilities is much harder since they emerge from combining benign knowledge.
Real world example:
2a/8
Real world example:
2a/8
🚨 New Paper Alert: Open Problem in Machine Unlearning for AI Safety 🚨
Can AI truly "forget"? While unlearning promises data removal, controlling emergent capabilities is a inherent challenge. Here's why it matters: 👇
Paper: arxiv.org/pdf/2501.04952
1/8

January 10, 2025 at 4:58 PM
🚨 New Paper Alert: Open Problem in Machine Unlearning for AI Safety 🚨
Can AI truly "forget"? While unlearning promises data removal, controlling emergent capabilities is a inherent challenge. Here's why it matters: 👇
Paper: arxiv.org/pdf/2501.04952
1/8
Today is a good day for AI Safety!
We are launching the AI Luminate AI Safety Benchmark @MLCommons @PeterMattson100 @tangenticAI
The first step towards global standard benchmark for AI PRODUCT safety!
We are launching the AI Luminate AI Safety Benchmark @MLCommons @PeterMattson100 @tangenticAI
The first step towards global standard benchmark for AI PRODUCT safety!

December 4, 2024 at 6:15 PM
Today is a good day for AI Safety!
We are launching the AI Luminate AI Safety Benchmark @MLCommons @PeterMattson100 @tangenticAI
The first step towards global standard benchmark for AI PRODUCT safety!
We are launching the AI Luminate AI Safety Benchmark @MLCommons @PeterMattson100 @tangenticAI
The first step towards global standard benchmark for AI PRODUCT safety!