



Evangelos Kazakos
@ekazakos.bsky.social
Postdoctoral researcher @ CIIRC, CTU, Prague working in vision & language. Also robotics noob. PhD from University of Bristol. Ex. Samsung Research (SAIC-C). I love coffee and plants. And socks.
Mystic vibes in Kutna Hora 🎶🎶
I LOVE THE CZECH REPUBLIC! 🇨🇿
I LOVE THE CZECH REPUBLIC! 🇨🇿
November 24, 2025 at 8:32 AM
Mystic vibes in Kutna Hora 🎶🎶
I LOVE THE CZECH REPUBLIC! 🇨🇿
I LOVE THE CZECH REPUBLIC! 🇨🇿
Sweetest barista ever! Made my day.

November 12, 2025 at 7:19 AM
Sweetest barista ever! Made my day.

I’m in paradise

October 17, 2025 at 10:18 AM
I’m in paradise

I wish all buildings in cities were like this one.
Prague, Krymská
Prague, Krymská

September 12, 2025 at 2:47 PM
I wish all buildings in cities were like this one.
Prague, Krymská
Prague, Krymská
Am I tripping??? Was just randomly checking Bluesky's repo and they've just pushed a commit for bookmarks!!!
Bookmarks feature is coming soon on Bluesky folks! 🎉🎉🎉❤️❤️❤️
Bookmarks feature is coming soon on Bluesky folks! 🎉🎉🎉❤️❤️❤️

September 5, 2025 at 3:12 AM
Am I tripping??? Was just randomly checking Bluesky's repo and they've just pushed a commit for bookmarks!!!
Bookmarks feature is coming soon on Bluesky folks! 🎉🎉🎉❤️❤️❤️
Bookmarks feature is coming soon on Bluesky folks! 🎉🎉🎉❤️❤️❤️
New (for me) champions breakfast: cottage cheese, chestnut honey and chia seeds on bread!

June 22, 2025 at 5:11 AM
New (for me) champions breakfast: cottage cheese, chestnut honey and chia seeds on bread!
Prague summer vibes 😍
(Ok, it was not the most summery weather, but still)
(Ok, it was not the most summery weather, but still)


June 7, 2025 at 4:33 PM
Prague summer vibes 😍
(Ok, it was not the most summery weather, but still)
(Ok, it was not the most summery weather, but still)


I love Prague so much! 😍

May 22, 2025 at 6:47 AM
I love Prague so much! 😍
@noagarciad.bsky.social is giving a very interesting and important talk on Fairness and Bias in Computer Vision at the Faculty of Electrical Engineering, Czech Technical University in Prague.


May 21, 2025 at 9:27 AM
@noagarciad.bsky.social is giving a very interesting and important talk on Fairness and Bias in Computer Vision at the Faculty of Electrical Engineering, Czech Technical University in Prague.
I have found this on my morning walk in the nature. Please tell me that I’ve found a prehistoric fossil! Any experts here? 🙏🙏

May 4, 2025 at 11:38 AM
I have found this on my morning walk in the nature. Please tell me that I’ve found a prehistoric fossil! Any experts here? 🙏🙏
Our EGO needs some fuel from time to time…

May 1, 2025 at 7:37 AM
Our EGO needs some fuel from time to time…
Our method achieves state-of-the-art results on iGround, VidSTG, and ActivityNet-Entities datasets! Extensive ablations highlight the importance of large-scale pre-training and show significant gains with our temporal objectness approach. 6/7


April 16, 2025 at 4:15 PM
Our method achieves state-of-the-art results on iGround, VidSTG, and ActivityNet-Entities datasets! Extensive ablations highlight the importance of large-scale pre-training and show significant gains with our temporal objectness approach. 6/7
Introducing GROVE, our GROunded Video caption gEneration model featuring spatio-temporal adapters, bounding-box decoding, and a novel temporal objectness head for identifying when captioned objects appear. 4/7
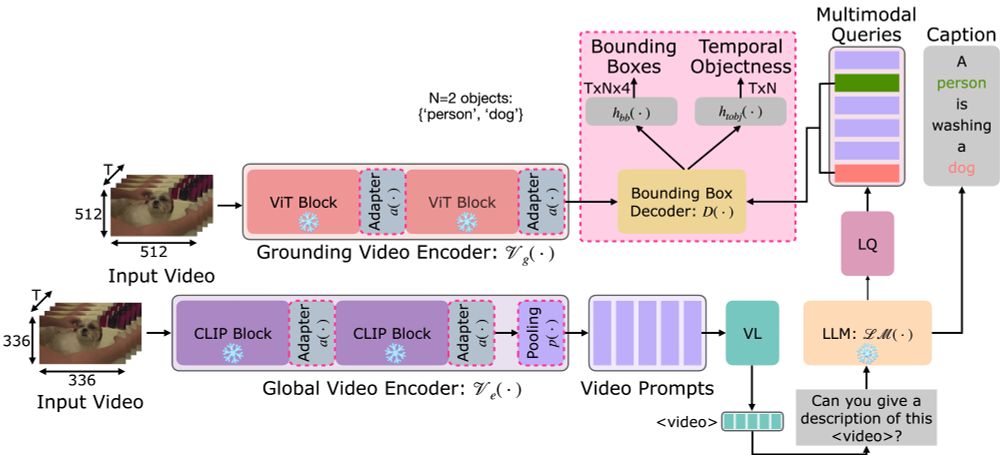
April 16, 2025 at 4:15 PM
Introducing GROVE, our GROunded Video caption gEneration model featuring spatio-temporal adapters, bounding-box decoding, and a novel temporal objectness head for identifying when captioned objects appear. 4/7
We present HowToGround1M, a new dataset of 1M videos from HowTo100M, annotated automatically using our method. It includes captions and dense bounding boxes for all the frames that objects from the caption are visible. 3/7

April 16, 2025 at 4:15 PM
We present HowToGround1M, a new dataset of 1M videos from HowTo100M, annotated automatically using our method. It includes captions and dense bounding boxes for all the frames that objects from the caption are visible. 3/7
We've developed a large-scale automatic annotation method leveraging an image-level grounded captioning model and LLMs to aggregate frame-level details into comprehensive video-level labels, consisting of captions along with dense bounding boxes corresponding to objects from the caption. 2/7
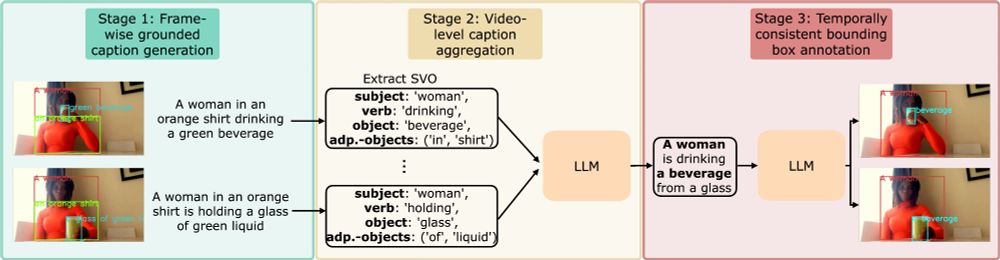
April 16, 2025 at 4:15 PM
We've developed a large-scale automatic annotation method leveraging an image-level grounded captioning model and LLMs to aggregate frame-level details into comprehensive video-level labels, consisting of captions along with dense bounding boxes corresponding to objects from the caption. 2/7
New type of socks that I never had before. I love them! 😍



April 16, 2025 at 12:15 PM
New type of socks that I never had before. I love them! 😍
So I was correct. The deadline is off by one day in AI Conference DL Countdown.

March 5, 2025 at 11:03 AM
So I was correct. The deadline is off by one day in AI Conference DL Countdown.
This is the best I could get. A bit embarrassed to share the prompt as I go off the rails 🤣🤣

February 23, 2025 at 9:14 PM
This is the best I could get. A bit embarrassed to share the prompt as I go off the rails 🤣🤣

