



@edwardraffml.bsky.social
Sr. Director @CrowdStrike. Visiting Prof @UMBC. Interested in all things ML
It is an important job! Good work 👊
July 20, 2025 at 11:27 PM
It is an important job! Good work 👊
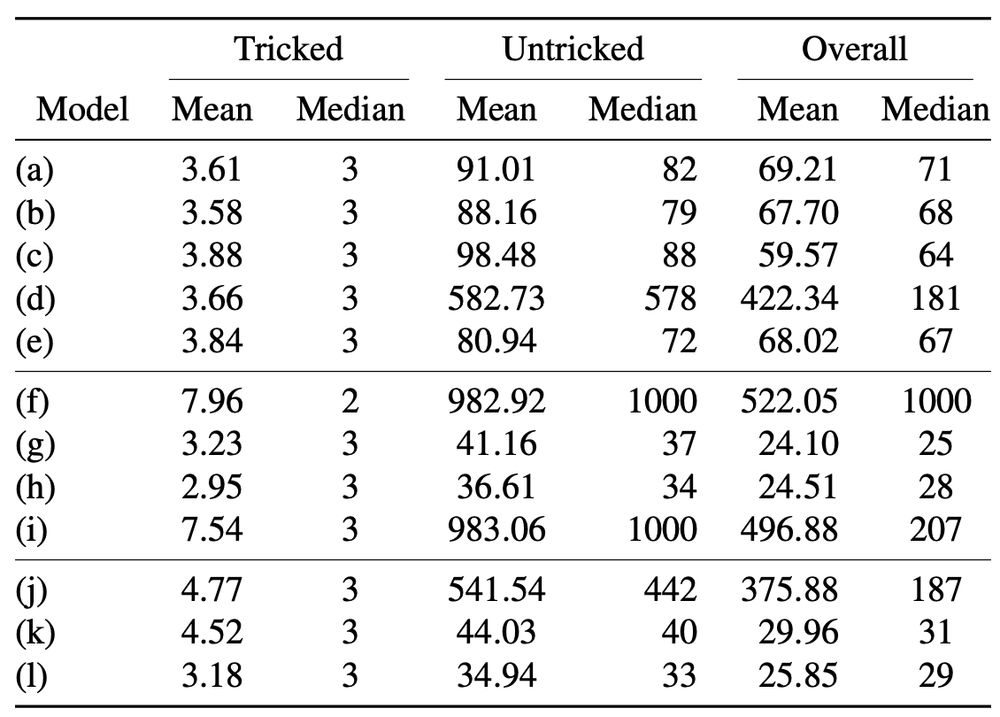
You can see some simple stats below. Images that get tricked usually need just 3 iterations of PGD to break, and most models don't use even 100 - but there is a long tail in the iterations you need. Lucky fo rus, adaptive step sizes don't improve PGD so much, so we get this fun!
June 16, 2025 at 1:45 PM
You can see some simple stats below. Images that get tricked usually need just 3 iterations of PGD to break, and most models don't use even 100 - but there is a long tail in the iterations you need. Lucky fo rus, adaptive step sizes don't improve PGD so much, so we get this fun!
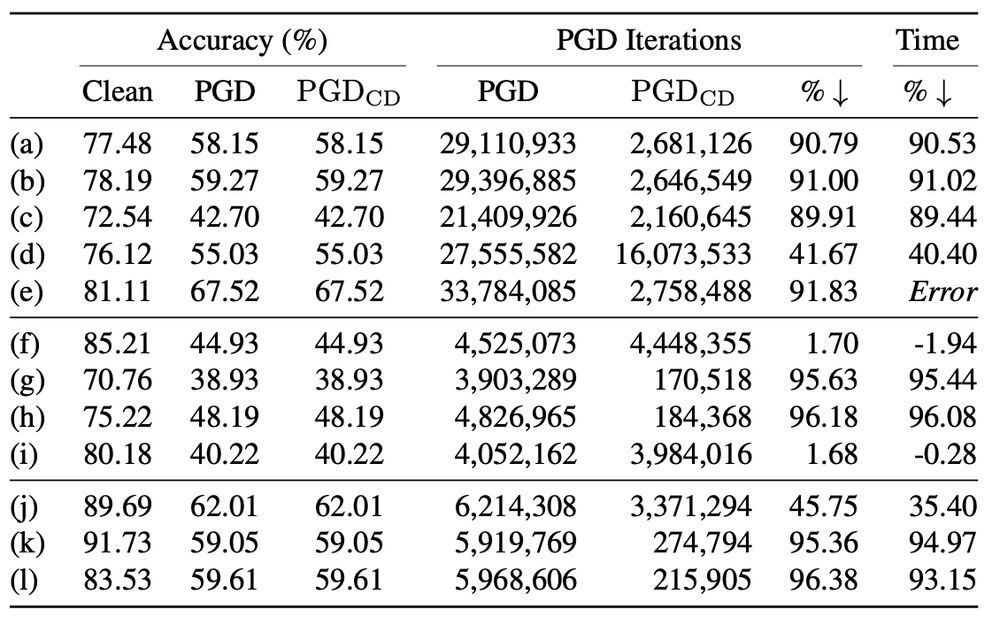
This results in real-world speedups; there are two slightly slower cases because the models just didn't cycle. But those are on CIFAR10, as the dimension goes up we see better results because more of the mass exists on the edge of the ∞-norm ball, making cycling easier.
June 16, 2025 at 1:45 PM
This results in real-world speedups; there are two slightly slower cases because the models just didn't cycle. But those are on CIFAR10, as the dimension goes up we see better results because more of the mass exists on the edge of the ∞-norm ball, making cycling easier.
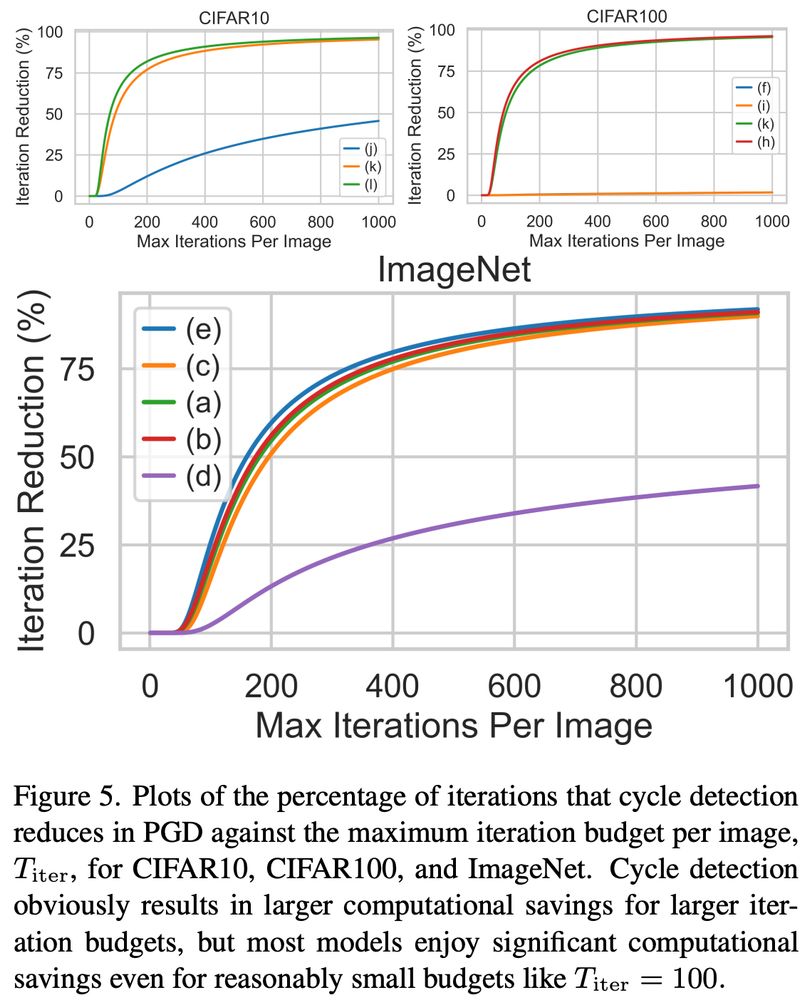
As you perform more attack iterations, you see the advantage increase. If you want to do a standard 1k eval attacks against ImageNet, the naive PGD would be just as expensive as training the model, but now you can get the cost way down
June 16, 2025 at 1:45 PM
As you perform more attack iterations, you see the advantage increase. If you want to do a standard 1k eval attacks against ImageNet, the naive PGD would be just as expensive as training the model, but now you can get the cost way down
A second simple observation is that when you do successfully attack an image, you can just stop. Shockingly, no code for PGD in any of the major frameworks checks for this! Once in a cycle you know the future, so also stop. So the complete procedure is very simple.

June 16, 2025 at 1:45 PM
A second simple observation is that when you do successfully attack an image, you can just stop. Shockingly, no code for PGD in any of the major frameworks checks for this! Once in a cycle you know the future, so also stop. So the complete procedure is very simple.
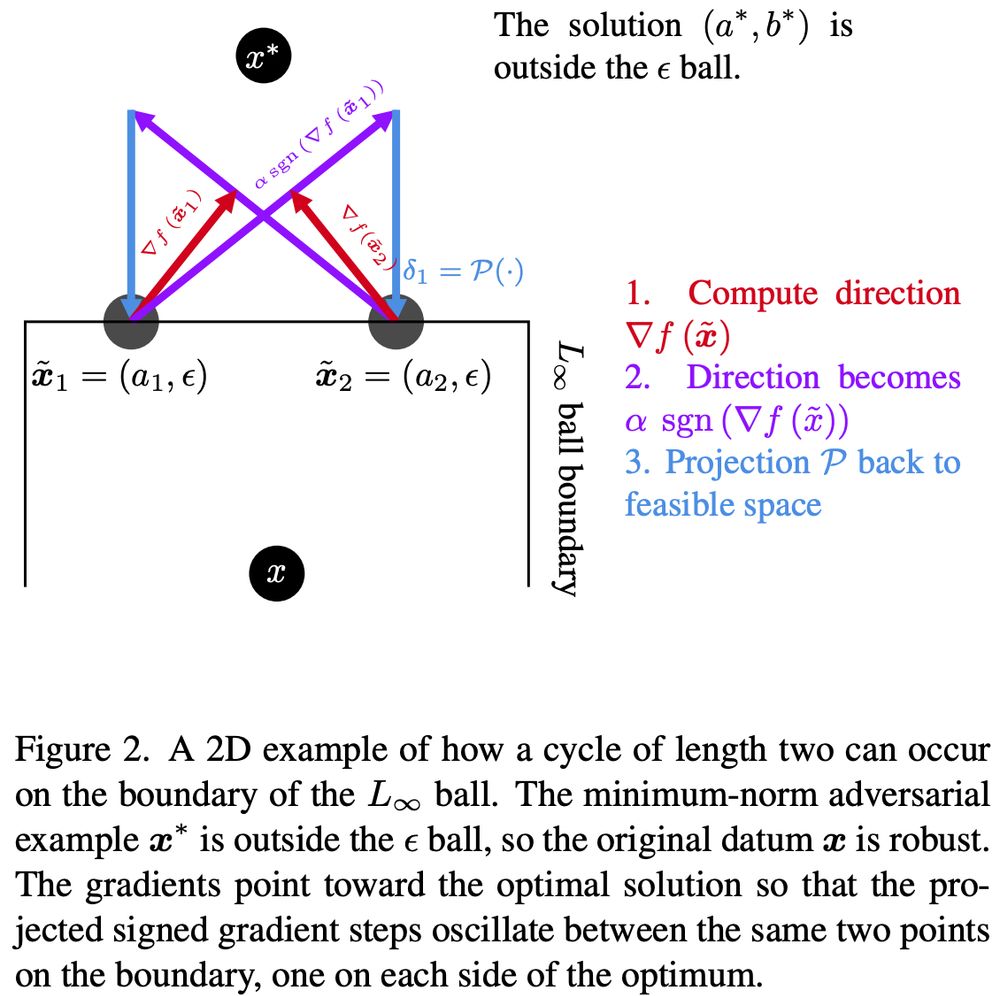
Why does it start to cycle? The solution point exists outside the L∞ ball, and can not be reached. When you use PGD and clip to the sign, you "normalize" the steps and enforce a grid of finite locations for the search to proceed from. Voila, you get cycles!
June 16, 2025 at 1:45 PM
Why does it start to cycle? The solution point exists outside the L∞ ball, and can not be reached. When you use PGD and clip to the sign, you "normalize" the steps and enforce a grid of finite locations for the search to proceed from. Voila, you get cycles!
The crux of the paper is simple, you want a large max iteration count T, but you don't want ot use them all every time! When a model is robust under the L∞ norm, your perturbation starts to cycle in the corners, so you start to do redundant work!

June 16, 2025 at 1:45 PM
The crux of the paper is simple, you want a large max iteration count T, but you don't want ot use them all every time! When a model is robust under the L∞ norm, your perturbation starts to cycle in the corners, so you start to do redundant work!
Very inclusive, we are all rank-n university graduates for some value of n!
April 11, 2025 at 4:00 PM
Very inclusive, we are all rank-n university graduates for some value of n!
Fits conveniently in your wallet!
March 30, 2025 at 3:58 PM
Fits conveniently in your wallet!
I'm skipping a lot of nitty gritty details on how to make this over 10% more accurate then the next best option! So you should read them at arxiv.org/abs/2502.02759 and check RJ out int he future at TheWebConf !

March 26, 2025 at 4:53 PM
I'm skipping a lot of nitty gritty details on how to make this over 10% more accurate then the next best option! So you should read them at arxiv.org/abs/2502.02759 and check RJ out int he future at TheWebConf !
But plurality voting like everyone else is lame. We want to be Bayesian about it, and scale up Independent Bayesian Classifier Combination to handle sparse data like we have - with the world's fastest and most scalable implementation!
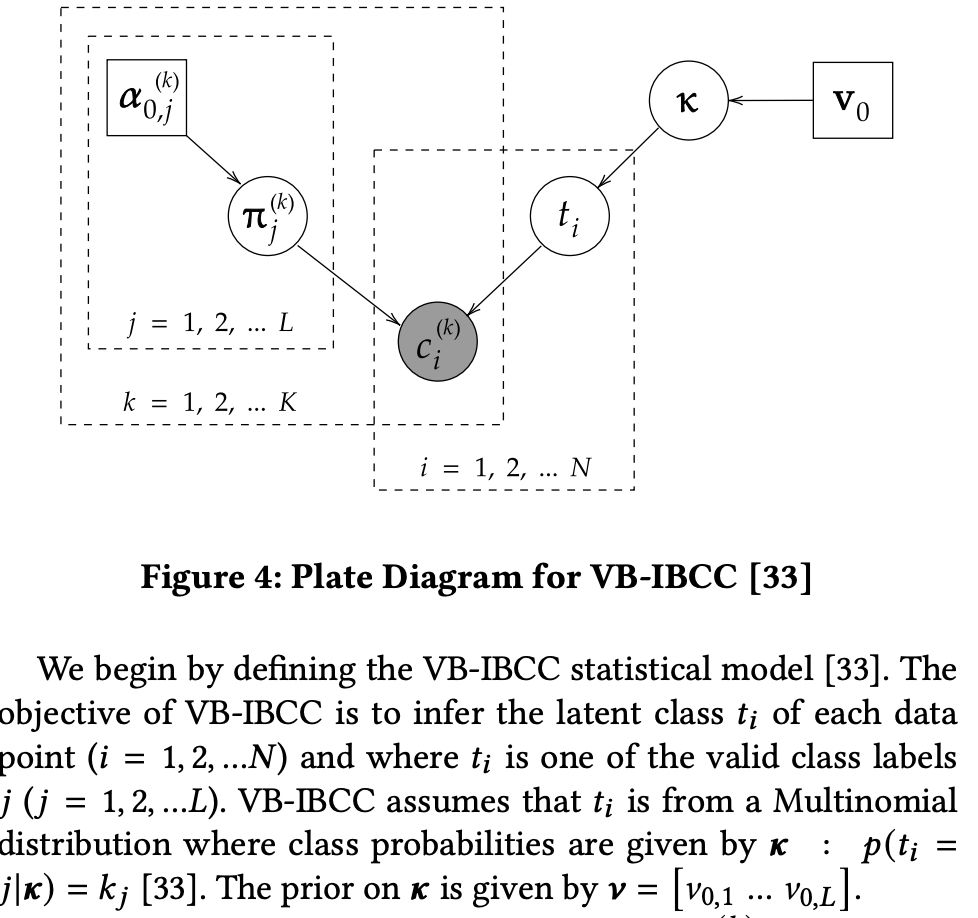
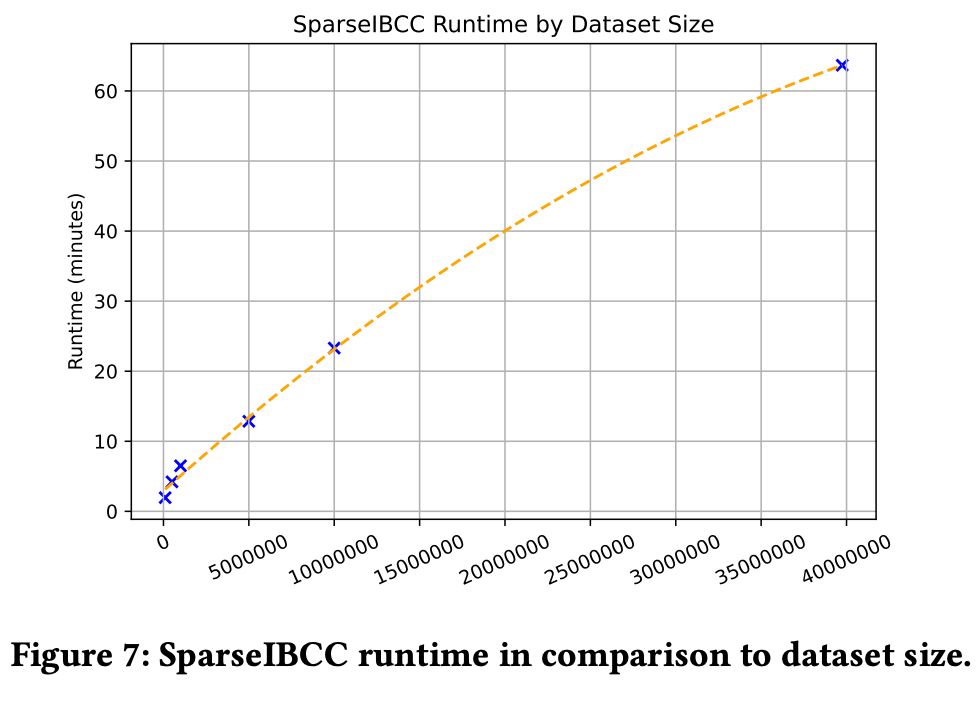
March 26, 2025 at 4:53 PM
But plurality voting like everyone else is lame. We want to be Bayesian about it, and scale up Independent Bayesian Classifier Combination to handle sparse data like we have - with the world's fastest and most scalable implementation!
Mostly, you wait for RJ to write a parser for almost every AV that exists to break out their responses into a standardized tokenization AND to record the relationships between AVs toa void double-voting!
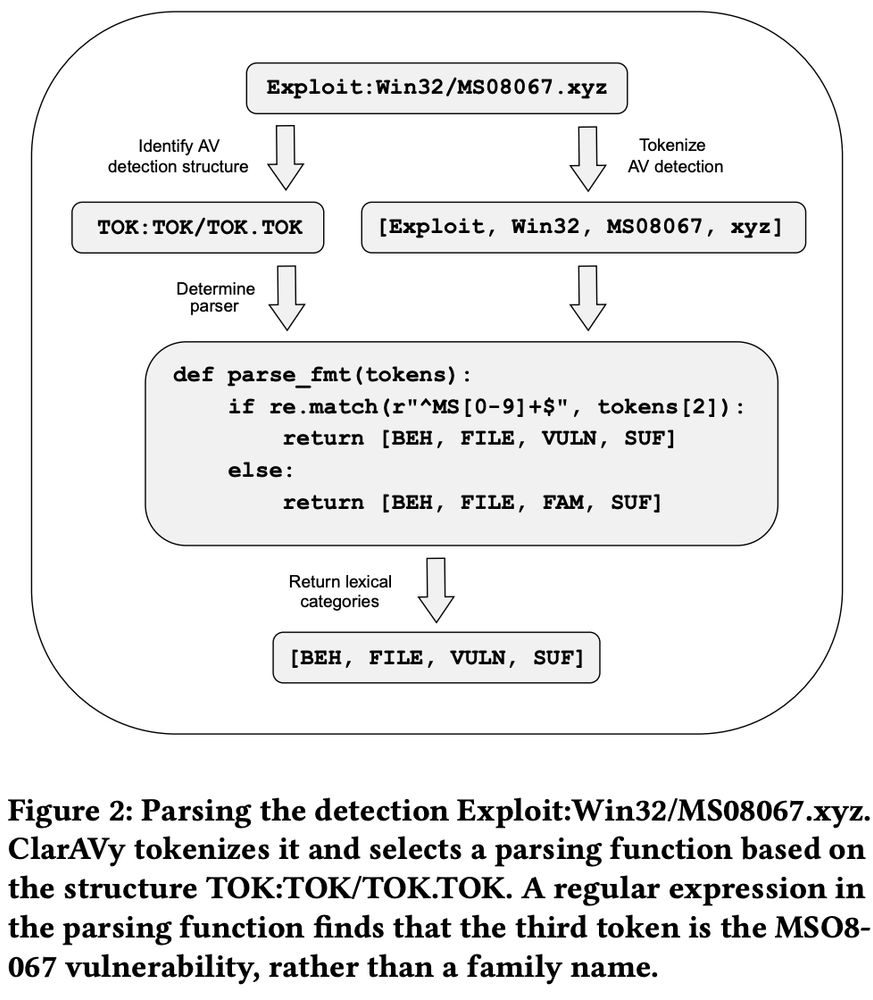
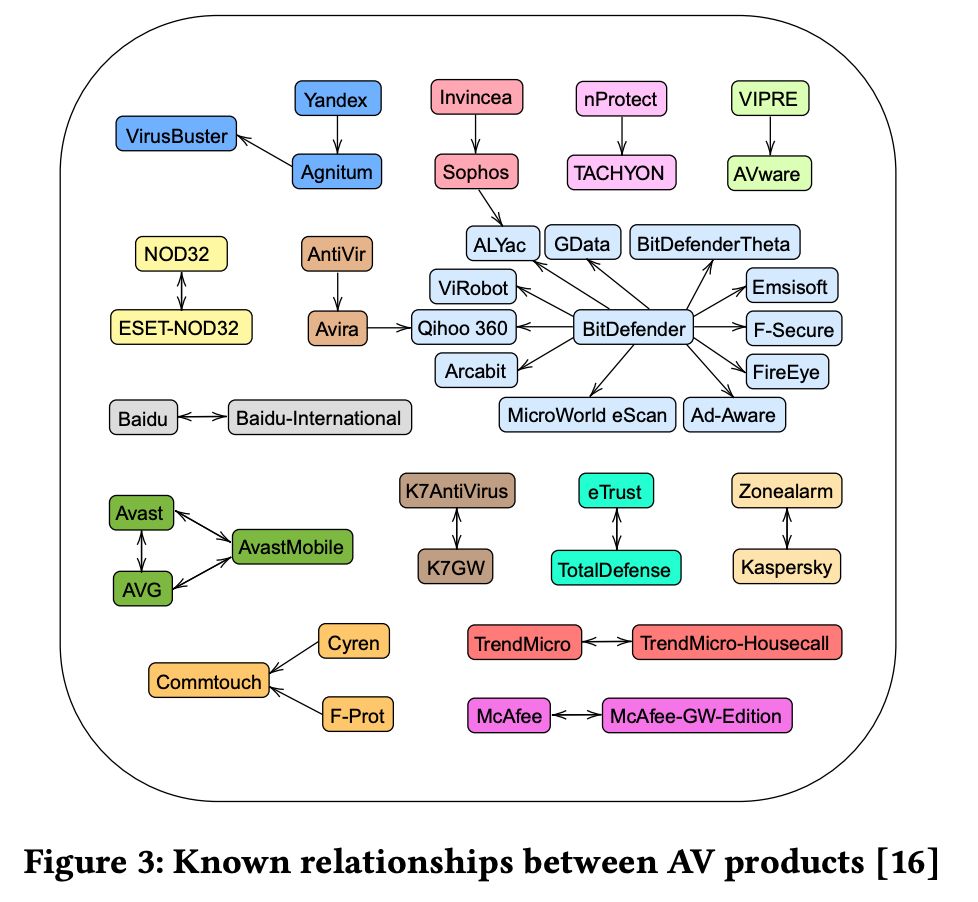
March 26, 2025 at 4:53 PM
Mostly, you wait for RJ to write a parser for almost every AV that exists to break out their responses into a standardized tokenization AND to record the relationships between AVs toa void double-voting!
You start with AV reports from your friendly neighborhood @virustotal.bsky.social , but you get conflicting answers /info that is unstandardized from every AV, what do you do?

March 26, 2025 at 4:53 PM
You start with AV reports from your friendly neighborhood @virustotal.bsky.social , but you get conflicting answers /info that is unstandardized from every AV, what do you do?
agree that if a paper does convincingly a good service to a research community, that would be enough to warrant publication regardless of the complexity of the underlying idea. We concur with R3, in fact, that "high technical complexity does not necessarily mean novelty or good science.""
March 6, 2025 at 4:29 PM
agree that if a paper does convincingly a good service to a research community, that would be enough to warrant publication regardless of the complexity of the underlying idea. We concur with R3, in fact, that "high technical complexity does not necessarily mean novelty or good science.""
(2) the proposed method is very simple. Besides other minor issues, disagreement arises as to whether a very simple but useful idea, as the one proposed here, deserves being published in a prestigious scientific venue such as CVPR. We discussed this extensively during the AC triplet meeting and we
March 6, 2025 at 4:29 PM
(2) the proposed method is very simple. Besides other minor issues, disagreement arises as to whether a very simple but useful idea, as the one proposed here, deserves being published in a prestigious scientific venue such as CVPR. We discussed this extensively during the AC triplet meeting and we