



@edwardraffml.bsky.social
Sr. Director @CrowdStrike. Visiting Prof @UMBC. Interested in all things ML

September 1, 2025 at 11:04 PM
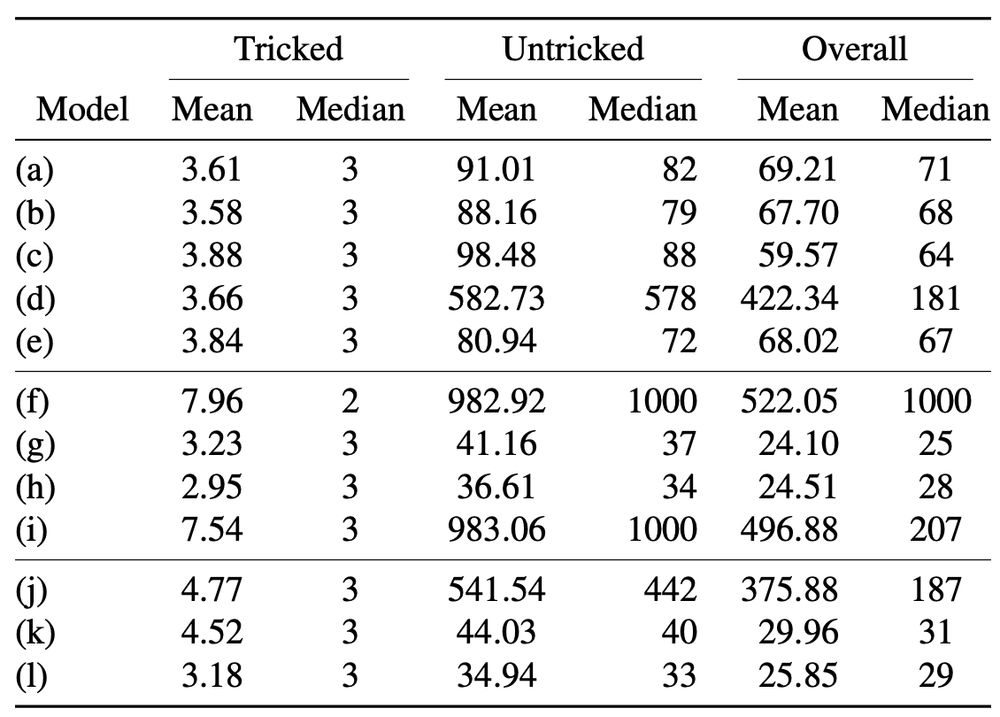
You can see some simple stats below. Images that get tricked usually need just 3 iterations of PGD to break, and most models don't use even 100 - but there is a long tail in the iterations you need. Lucky fo rus, adaptive step sizes don't improve PGD so much, so we get this fun!
June 16, 2025 at 1:45 PM
You can see some simple stats below. Images that get tricked usually need just 3 iterations of PGD to break, and most models don't use even 100 - but there is a long tail in the iterations you need. Lucky fo rus, adaptive step sizes don't improve PGD so much, so we get this fun!
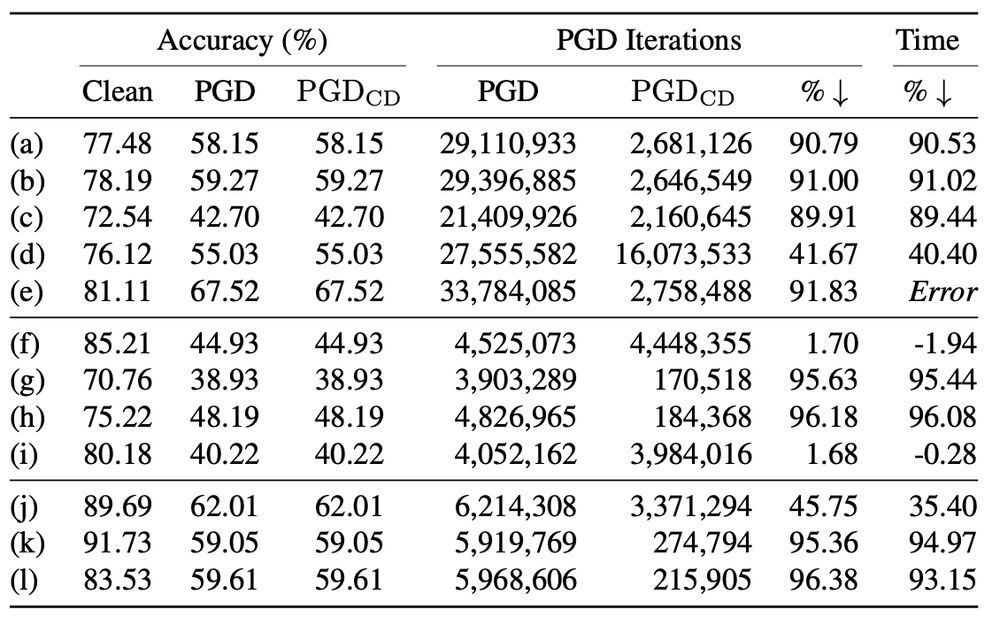
This results in real-world speedups; there are two slightly slower cases because the models just didn't cycle. But those are on CIFAR10, as the dimension goes up we see better results because more of the mass exists on the edge of the ∞-norm ball, making cycling easier.
June 16, 2025 at 1:45 PM
This results in real-world speedups; there are two slightly slower cases because the models just didn't cycle. But those are on CIFAR10, as the dimension goes up we see better results because more of the mass exists on the edge of the ∞-norm ball, making cycling easier.
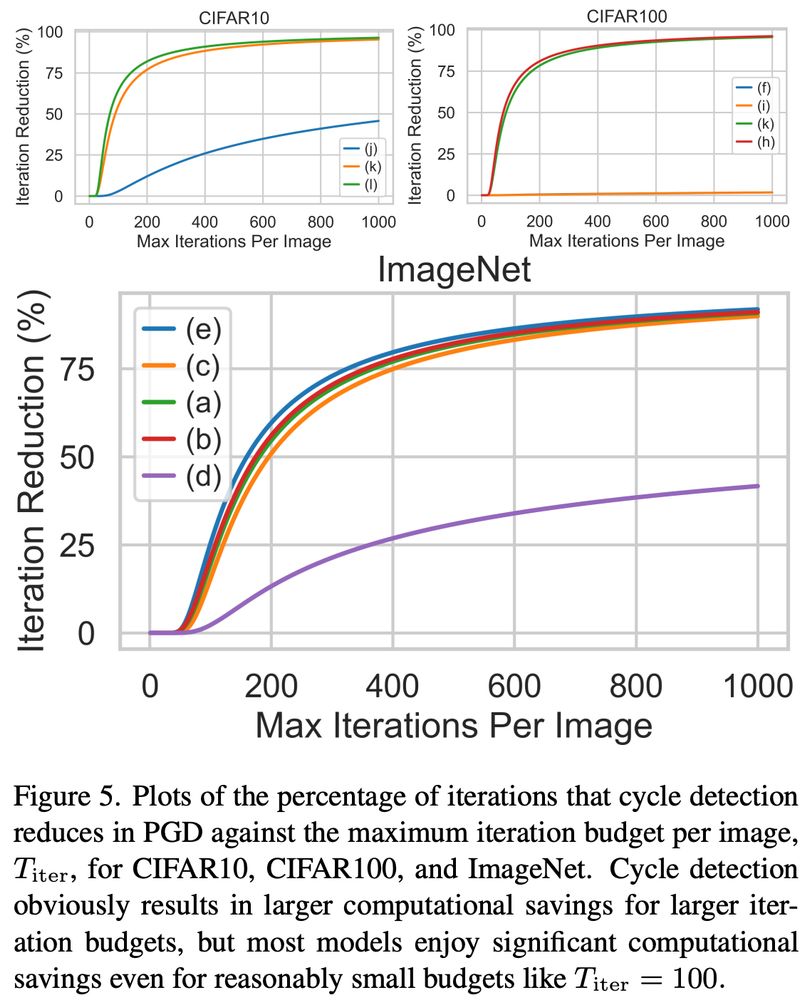
As you perform more attack iterations, you see the advantage increase. If you want to do a standard 1k eval attacks against ImageNet, the naive PGD would be just as expensive as training the model, but now you can get the cost way down
June 16, 2025 at 1:45 PM
As you perform more attack iterations, you see the advantage increase. If you want to do a standard 1k eval attacks against ImageNet, the naive PGD would be just as expensive as training the model, but now you can get the cost way down
A second simple observation is that when you do successfully attack an image, you can just stop. Shockingly, no code for PGD in any of the major frameworks checks for this! Once in a cycle you know the future, so also stop. So the complete procedure is very simple.

June 16, 2025 at 1:45 PM
A second simple observation is that when you do successfully attack an image, you can just stop. Shockingly, no code for PGD in any of the major frameworks checks for this! Once in a cycle you know the future, so also stop. So the complete procedure is very simple.
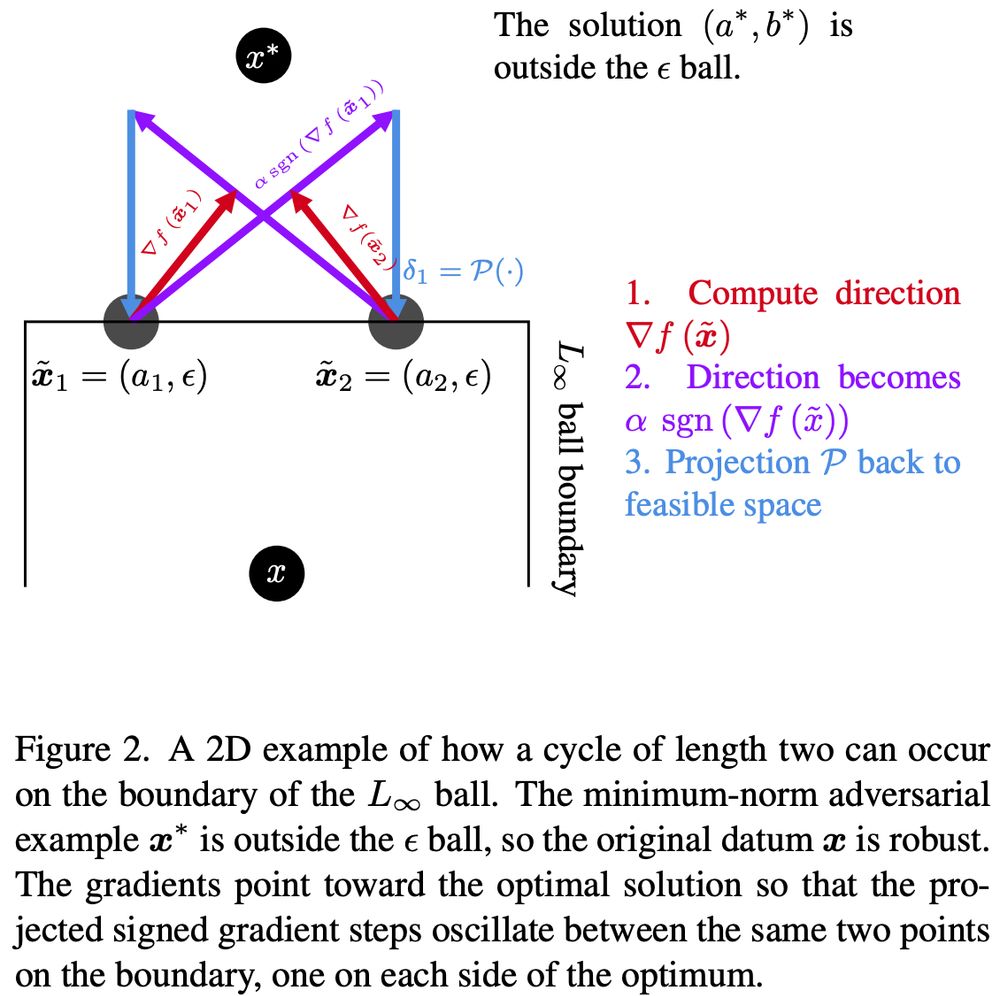
Why does it start to cycle? The solution point exists outside the L∞ ball, and can not be reached. When you use PGD and clip to the sign, you "normalize" the steps and enforce a grid of finite locations for the search to proceed from. Voila, you get cycles!
June 16, 2025 at 1:45 PM
Why does it start to cycle? The solution point exists outside the L∞ ball, and can not be reached. When you use PGD and clip to the sign, you "normalize" the steps and enforce a grid of finite locations for the search to proceed from. Voila, you get cycles!
The crux of the paper is simple, you want a large max iteration count T, but you don't want ot use them all every time! When a model is robust under the L∞ norm, your perturbation starts to cycle in the corners, so you start to do redundant work!

June 16, 2025 at 1:45 PM
The crux of the paper is simple, you want a large max iteration count T, but you don't want ot use them all every time! When a model is robust under the L∞ norm, your perturbation starts to cycle in the corners, so you start to do redundant work!
Philip Doldo 's first @cvprconference.bsky.social paper, 𝑆𝑡𝑜𝑝 𝑊𝑎𝑙𝑘𝑖𝑛𝑔 𝑖𝑛 𝐶𝑖𝑟𝑐𝑙𝑒𝑠! 𝐵𝑎𝑖𝑙𝑖𝑛𝑔 𝑂𝑢𝑡 𝐸𝑎𝑟𝑙𝑦 𝑖𝑛 𝑃𝑟𝑜𝑗𝑒𝑐𝑡𝑒𝑑 𝐺𝑟𝑎𝑑𝑖𝑒𝑛𝑡 𝐷𝑒𝑠𝑐𝑒𝑛𝑡, is a rare free lunch for 10x faster AML 🧵👇 openaccess.thecvf.com/content/CVPR...

June 16, 2025 at 1:45 PM
Philip Doldo 's first @cvprconference.bsky.social paper, 𝑆𝑡𝑜𝑝 𝑊𝑎𝑙𝑘𝑖𝑛𝑔 𝑖𝑛 𝐶𝑖𝑟𝑐𝑙𝑒𝑠! 𝐵𝑎𝑖𝑙𝑖𝑛𝑔 𝑂𝑢𝑡 𝐸𝑎𝑟𝑙𝑦 𝑖𝑛 𝑃𝑟𝑜𝑗𝑒𝑐𝑡𝑒𝑑 𝐺𝑟𝑎𝑑𝑖𝑒𝑛𝑡 𝐷𝑒𝑠𝑐𝑒𝑛𝑡, is a rare free lunch for 10x faster AML 🧵👇 openaccess.thecvf.com/content/CVPR...
I'm skipping a lot of nitty gritty details on how to make this over 10% more accurate then the next best option! So you should read them at arxiv.org/abs/2502.02759 and check RJ out int he future at TheWebConf !

March 26, 2025 at 4:53 PM
I'm skipping a lot of nitty gritty details on how to make this over 10% more accurate then the next best option! So you should read them at arxiv.org/abs/2502.02759 and check RJ out int he future at TheWebConf !
But plurality voting like everyone else is lame. We want to be Bayesian about it, and scale up Independent Bayesian Classifier Combination to handle sparse data like we have - with the world's fastest and most scalable implementation!
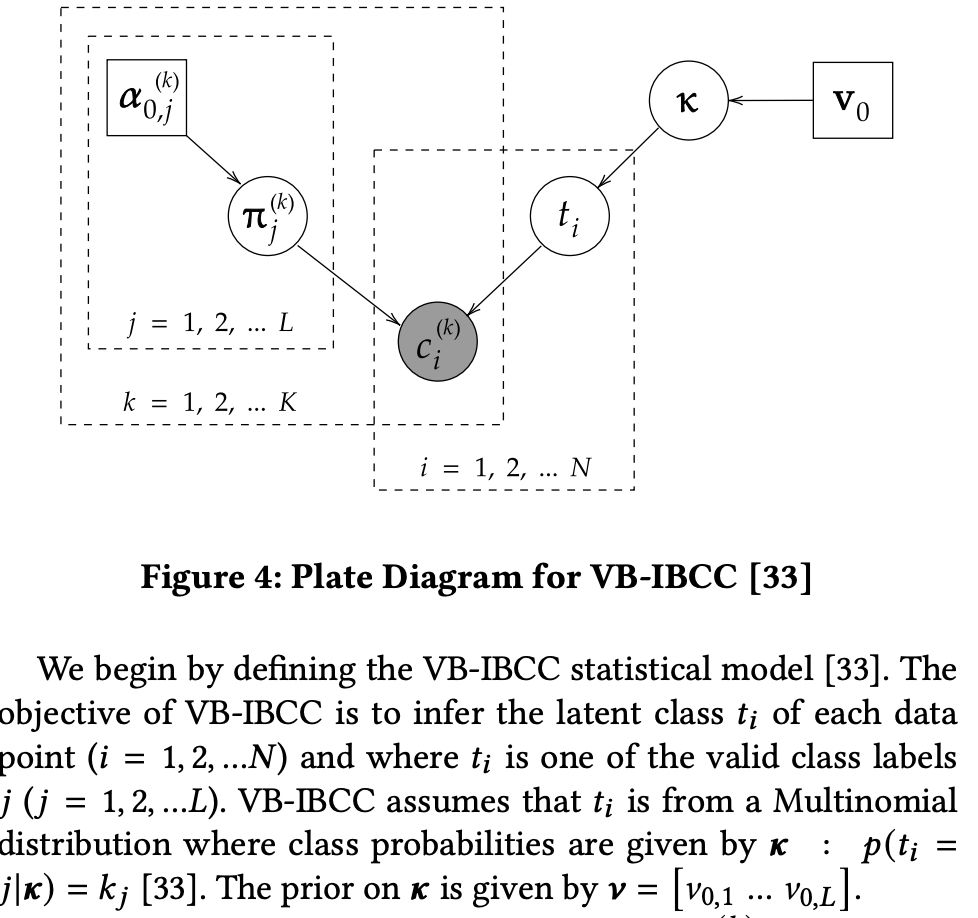
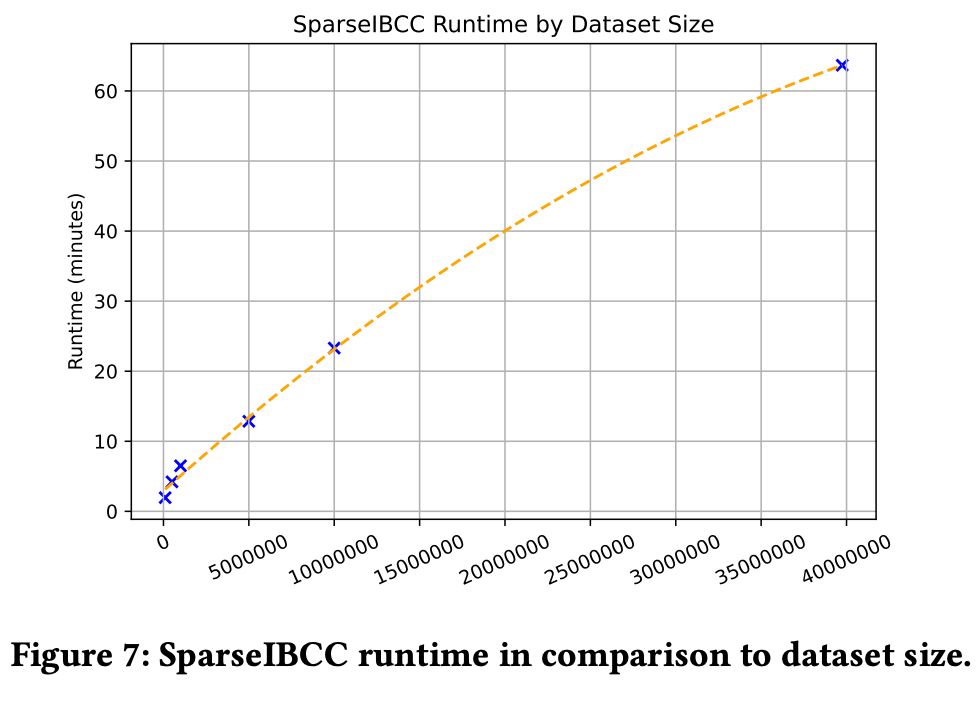
March 26, 2025 at 4:53 PM
But plurality voting like everyone else is lame. We want to be Bayesian about it, and scale up Independent Bayesian Classifier Combination to handle sparse data like we have - with the world's fastest and most scalable implementation!
Mostly, you wait for RJ to write a parser for almost every AV that exists to break out their responses into a standardized tokenization AND to record the relationships between AVs toa void double-voting!
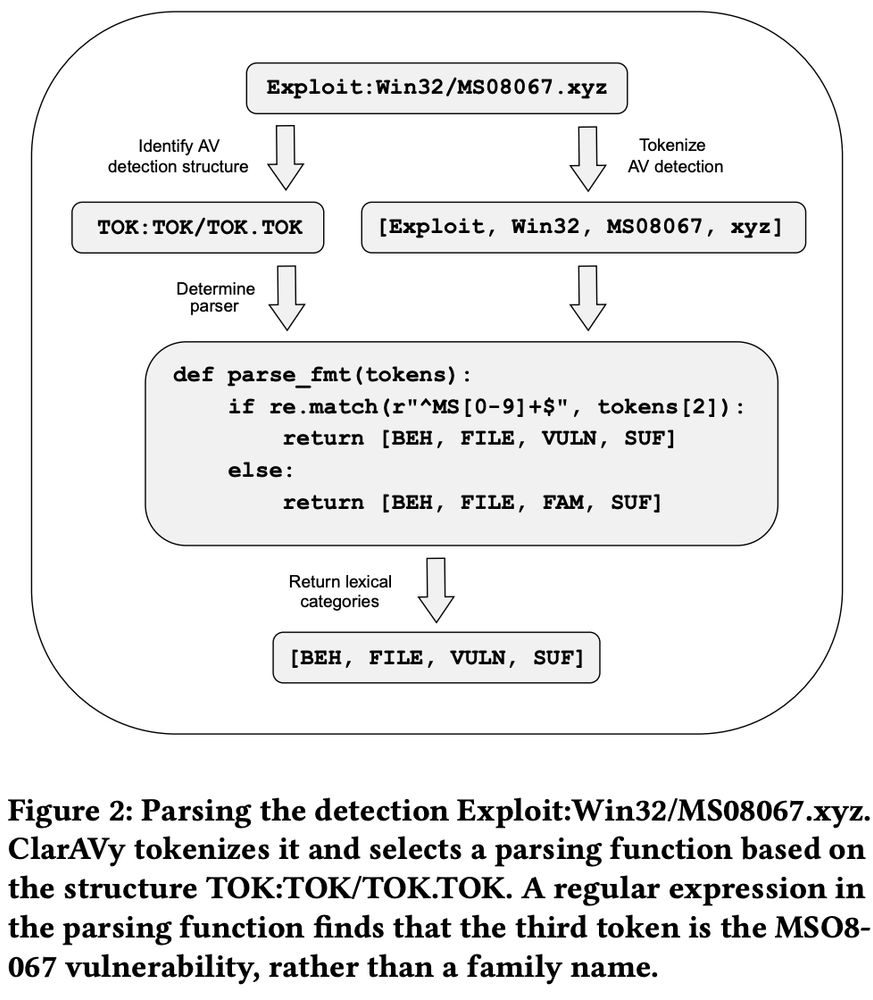
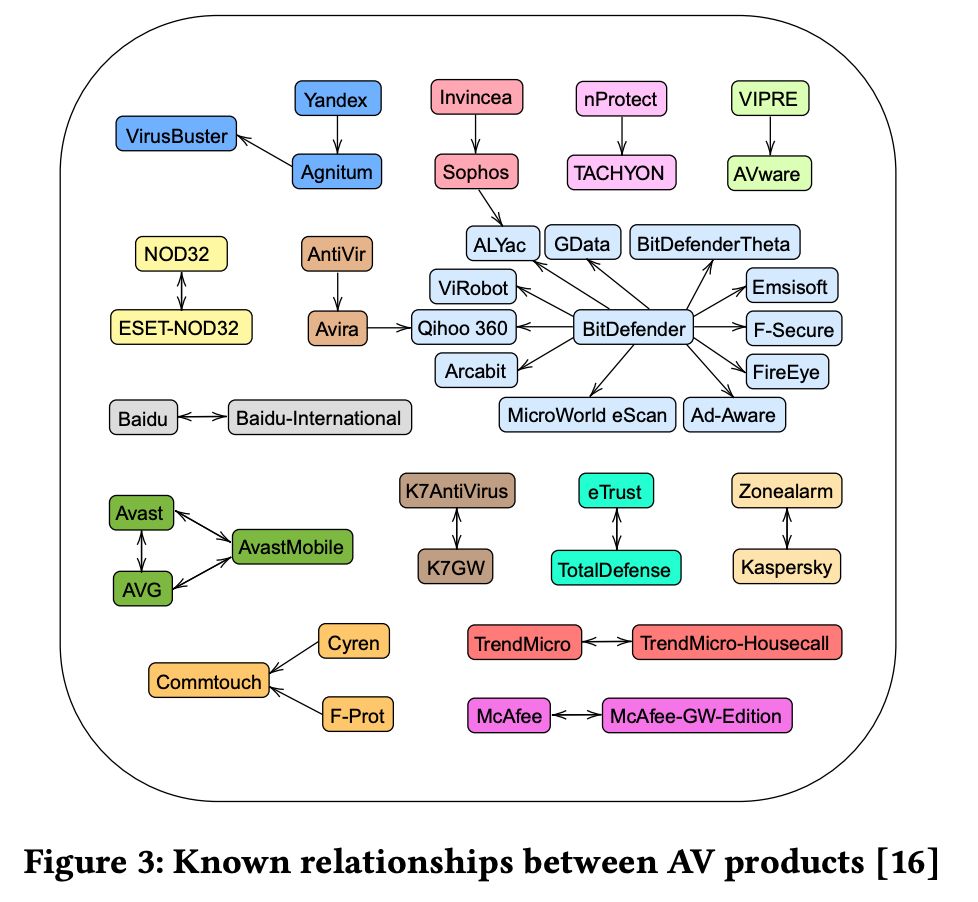
March 26, 2025 at 4:53 PM
Mostly, you wait for RJ to write a parser for almost every AV that exists to break out their responses into a standardized tokenization AND to record the relationships between AVs toa void double-voting!
You start with AV reports from your friendly neighborhood @virustotal.bsky.social , but you get conflicting answers /info that is unstandardized from every AV, what do you do?

March 26, 2025 at 4:53 PM
You start with AV reports from your friendly neighborhood @virustotal.bsky.social , but you get conflicting answers /info that is unstandardized from every AV, what do you do?
Would you like to have the world's most accurate malware label predictor? RJ #BoozAllen has you covered w/ ClarAVy: A Tool for Scalable and Accurate Malware Family Labeling, arxiv.org/abs/2502.02759 work 🧵👇 to appear at thewebconf.org

March 26, 2025 at 4:53 PM
Would you like to have the world's most accurate malware label predictor? RJ #BoozAllen has you covered w/ ClarAVy: A Tool for Scalable and Accurate Malware Family Labeling, arxiv.org/abs/2502.02759 work 🧵👇 to appear at thewebconf.org
Wow @cvprconference.bsky.social rejected 19 otherwise accepted papers for reviewer authors not participating. Honestly, good this has teeth and hope it will encourage more effortful reviewing! I always thought CVPR does the best in trying to balance the author/reviewer equities!

February 26, 2025 at 10:31 PM
Wow @cvprconference.bsky.social rejected 19 otherwise accepted papers for reviewer authors not participating. Honestly, good this has teeth and hope it will encourage more effortful reviewing! I always thought CVPR does the best in trying to balance the author/reviewer equities!
Why does this work? The same reason any new feature works. The (selected) Yara atoms have relatively little correlation with the Ember features, even if they have a higher self-similarity due to their construction to target some malware family/functionality of interest.

December 21, 2024 at 4:56 PM
Why does this work? The same reason any new feature works. The (selected) Yara atoms have relatively little correlation with the Ember features, even if they have a higher self-similarity due to their construction to target some malware family/functionality of interest.
And voila, you can outperform Ember-only features by adding features selected by mining Yara rules! It is a fairly non-trivial lift, considering how little effort was involved and that you don't need to add that many Yara atoms to get a lift.

December 21, 2024 at 4:56 PM
And voila, you can outperform Ember-only features by adding features selected by mining Yara rules! It is a fairly non-trivial lift, considering how little effort was involved and that you don't need to add that many Yara atoms to get a lift.
We test several ways you can add them based on how much computational cost you want to pay. The idea is basically simple: you have your existing features and concatenate the new features to a representation of the original (could be them, or a logit, or something else).

December 21, 2024 at 4:56 PM
We test several ways you can add them based on how much computational cost you want to pay. The idea is basically simple: you have your existing features and concatenate the new features to a representation of the original (could be them, or a logit, or something else).
Training on only the Yara signatures as features is surprisingly decent as a malware detector! Not amazing, but decent! But the real value here is that they are being created/updated already - and you can add them to your existing feature sets.

December 21, 2024 at 4:56 PM
Training on only the Yara signatures as features is surprisingly decent as a malware detector! Not amazing, but decent! But the real value here is that they are being created/updated already - and you can add them to your existing feature sets.
"But aren't Yara rules very precise, why would they generalize?" Yes, individualy they tend to be very high recall or precision, but not both. Individually though - people use the condition statement to get the final target precision. The atoms themselves are pretty diverse!

December 21, 2024 at 4:56 PM
"But aren't Yara rules very precise, why would they generalize?" Yes, individualy they tend to be very high recall or precision, but not both. Individually though - people use the condition statement to get the final target precision. The atoms themselves are pretty diverse!
Yara rules are basically fancy regular expressions. We can take all the 'atoms' of the rule, like $av4, and turn them into binary present/absent features for our model to incorporate. Nature of Yara means these are usually pretty fast to find/extract too 📰https://arxiv.org/abs/2411.18516

December 21, 2024 at 4:56 PM
Yara rules are basically fancy regular expressions. We can take all the 'atoms' of the rule, like $av4, and turn them into binary present/absent features for our model to incorporate. Nature of Yara means these are usually pretty fast to find/extract too 📰https://arxiv.org/abs/2411.18516
AV system is hard in part b/c you are constantly searching for new features. But analysts are also writing Yara rules, can you steal them as features? New paper #IEEEBigData looks are how you can live of the analyst w/ @cmat.bsky.social @cknicholas.bsky.social @csee-umbc.bsky.social 🧵

December 21, 2024 at 4:56 PM
AV system is hard in part b/c you are constantly searching for new features. But analysts are also writing Yara rules, can you steal them as features? New paper #IEEEBigData looks are how you can live of the analyst w/ @cmat.bsky.social @cknicholas.bsky.social @csee-umbc.bsky.social 🧵
A lot of work went into inspection and making sense of what was happening. You need to process the data b/c a lot of things that the compiler might naively tell you are different are really the same, thanks C++ templating 🫠

December 7, 2024 at 8:24 PM
A lot of work went into inspection and making sense of what was happening. You need to process the data b/c a lot of things that the compiler might naively tell you are different are really the same, thanks C++ templating 🫠
The results are quite good, avg MRR means you need to search on average top 2 nearest neighbors to find what you are looking for. Note that BSim and many others use a LOT of manual artisanal RE work and don't perform as well in this task! Good tools, but not for all tasks

December 7, 2024 at 8:24 PM
The results are quite good, avg MRR means you need to search on average top 2 nearest neighbors to find what you are looking for. Note that BSim and many others use a LOT of manual artisanal RE work and don't perform as well in this task! Good tools, but not for all tasks
We train using triplet learning after a lot of careful dataset construction/separation of functions, like identifying functions copied from @stackoverflow.com.web.brid.gy and copied into multiple projects! But the model is simple: MalConv strikes again!

December 7, 2024 at 8:24 PM
We train using triplet learning after a lot of careful dataset construction/separation of functions, like identifying functions copied from @stackoverflow.com.web.brid.gy and copied into multiple projects! But the model is simple: MalConv strikes again!
We train using Assemblage, but also build test-sets from other papers and RJ's MOTIF arxiv.org/pdf/2111.15031 work so that we can cover a spectrum of evaluation scenarios over multiple OS, so that we can get a much better holistic picture. NOTE: BinaryCorp is the training data for some prior stuff

December 7, 2024 at 8:24 PM
We train using Assemblage, but also build test-sets from other papers and RJ's MOTIF arxiv.org/pdf/2111.15031 work so that we can cover a spectrum of evaluation scenarios over multiple OS, so that we can get a much better holistic picture. NOTE: BinaryCorp is the training data for some prior stuff