




Edoardo Ponti
@edoardo-ponti.bsky.social
Assistant professor in Natural Language Processing at the University of Edinburgh and visiting professor at NVIDIA | A Kleene star shines on the hour of our meeting.
🏆 We evaluate inference-time hyper-scaling on DeepSeek R1-distilled models of different sizes, increasing accuracy on maths, science, and coding by up to 15 points for a given budget.

June 6, 2025 at 12:33 PM
🏆 We evaluate inference-time hyper-scaling on DeepSeek R1-distilled models of different sizes, increasing accuracy on maths, science, and coding by up to 15 points for a given budget.
💡The idea behind DMS is to *train* existing LLMs to evict tokens from the KV cache, while delaying the eviction some time after the decision.
This allows LLMs to preserve information while reducing latency and memory size.
This allows LLMs to preserve information while reducing latency and memory size.

June 6, 2025 at 12:33 PM
💡The idea behind DMS is to *train* existing LLMs to evict tokens from the KV cache, while delaying the eviction some time after the decision.
This allows LLMs to preserve information while reducing latency and memory size.
This allows LLMs to preserve information while reducing latency and memory size.
⚖️ The magic works only if accuracy is preserved even at high compression ratios.
Enter Dynamic Memory Sparsification (DMS), which achieves 8x KV cache compression with 1K training steps and retains accuracy better than SOTA methods.
Enter Dynamic Memory Sparsification (DMS), which achieves 8x KV cache compression with 1K training steps and retains accuracy better than SOTA methods.

June 6, 2025 at 12:33 PM
⚖️ The magic works only if accuracy is preserved even at high compression ratios.
Enter Dynamic Memory Sparsification (DMS), which achieves 8x KV cache compression with 1K training steps and retains accuracy better than SOTA methods.
Enter Dynamic Memory Sparsification (DMS), which achieves 8x KV cache compression with 1K training steps and retains accuracy better than SOTA methods.
🚀 By *learning* to compress the KV cache in Transformer LLMs, we can generate more tokens for the same compute budget.
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!

June 6, 2025 at 12:33 PM
🚀 By *learning* to compress the KV cache in Transformer LLMs, we can generate more tokens for the same compute budget.
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
4) Finally, we introduce novel scaling laws for sparse attention and validate them on held-out results: evidence that our findings will likely hold true broadly.
Our insights demonstrate that sparse attention will play a key role in next-generation foundation models.
Our insights demonstrate that sparse attention will play a key role in next-generation foundation models.

April 25, 2025 at 3:39 PM
4) Finally, we introduce novel scaling laws for sparse attention and validate them on held-out results: evidence that our findings will likely hold true broadly.
Our insights demonstrate that sparse attention will play a key role in next-generation foundation models.
Our insights demonstrate that sparse attention will play a key role in next-generation foundation models.
3) There is no single best strategy across tasks and phases.
However, on average Verticals-Slashes for prefilling and Quest for decoding are the most competitive. Context-aware, and highly adaptive variants are preferable.
However, on average Verticals-Slashes for prefilling and Quest for decoding are the most competitive. Context-aware, and highly adaptive variants are preferable.

April 25, 2025 at 3:39 PM
3) There is no single best strategy across tasks and phases.
However, on average Verticals-Slashes for prefilling and Quest for decoding are the most competitive. Context-aware, and highly adaptive variants are preferable.
However, on average Verticals-Slashes for prefilling and Quest for decoding are the most competitive. Context-aware, and highly adaptive variants are preferable.
2) Sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding ✍️ than prefilling 🧠, and correlates with model size in the former.
Importantly, for most settings there is at least one degraded task, even at moderate compressions (<5x).
Importantly, for most settings there is at least one degraded task, even at moderate compressions (<5x).

April 25, 2025 at 3:39 PM
2) Sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding ✍️ than prefilling 🧠, and correlates with model size in the former.
Importantly, for most settings there is at least one degraded task, even at moderate compressions (<5x).
Importantly, for most settings there is at least one degraded task, even at moderate compressions (<5x).
1) For very long sequences, *larger and highly sparse models* are preferable to small, dense ones for the same FLOPS budget.
This suggests a strategy shift where scaling up model size must be combined with sparse attention to achieve an optimal trade-off.
This suggests a strategy shift where scaling up model size must be combined with sparse attention to achieve an optimal trade-off.

April 25, 2025 at 3:39 PM
1) For very long sequences, *larger and highly sparse models* are preferable to small, dense ones for the same FLOPS budget.
This suggests a strategy shift where scaling up model size must be combined with sparse attention to achieve an optimal trade-off.
This suggests a strategy shift where scaling up model size must be combined with sparse attention to achieve an optimal trade-off.
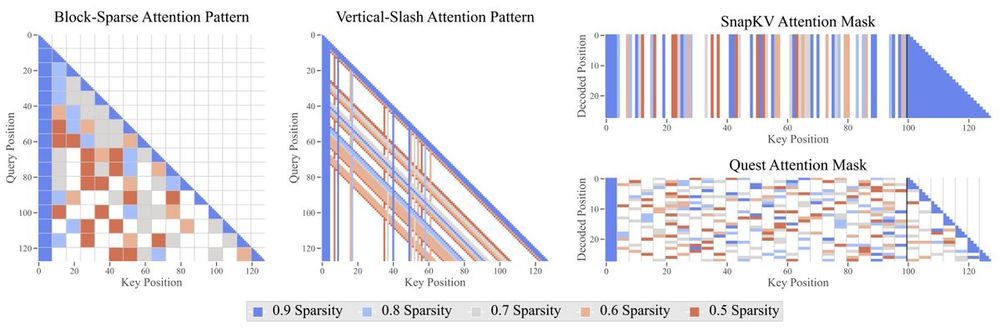
Sparse attention is one of the most promising strategies to unlock long-context processing and long-generation reasoning in LLMs.
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
April 25, 2025 at 3:39 PM
Sparse attention is one of the most promising strategies to unlock long-context processing and long-generation reasoning in LLMs.
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
We're hiring a lecturer or reader in embodied NLP at the University of Edinburgh!
Deadline: 31 Jan 2025
Call for applications: elxw.fa.em3.oraclecloud.com/hcmUI/Candid...
Deadline: 31 Jan 2025
Call for applications: elxw.fa.em3.oraclecloud.com/hcmUI/Candid...

December 22, 2024 at 9:46 AM
We're hiring a lecturer or reader in embodied NLP at the University of Edinburgh!
Deadline: 31 Jan 2025
Call for applications: elxw.fa.em3.oraclecloud.com/hcmUI/Candid...
Deadline: 31 Jan 2025
Call for applications: elxw.fa.em3.oraclecloud.com/hcmUI/Candid...



Another nano gem from my amazing student
Piotr Nawrot!
A repo & notebook on sparse attention for efficient LLM inference: github.com/PiotrNawrot/...
This will also feature in my #NeurIPS 2024 tutorial "Dynamic Sparsity in ML" with André Martins: dynamic-sparsity.github.io Stay tuned!
Piotr Nawrot!
A repo & notebook on sparse attention for efficient LLM inference: github.com/PiotrNawrot/...
This will also feature in my #NeurIPS 2024 tutorial "Dynamic Sparsity in ML" with André Martins: dynamic-sparsity.github.io Stay tuned!

November 20, 2024 at 12:51 PM
Another nano gem from my amazing student
Piotr Nawrot!
A repo & notebook on sparse attention for efficient LLM inference: github.com/PiotrNawrot/...
This will also feature in my #NeurIPS 2024 tutorial "Dynamic Sparsity in ML" with André Martins: dynamic-sparsity.github.io Stay tuned!
Piotr Nawrot!
A repo & notebook on sparse attention for efficient LLM inference: github.com/PiotrNawrot/...
This will also feature in my #NeurIPS 2024 tutorial "Dynamic Sparsity in ML" with André Martins: dynamic-sparsity.github.io Stay tuned!